

检测大规模金融欺诈与决策树和MLflow砖






2019年5月2日 在公司博客上
使用人工智能检测欺诈模式规模是一个挑战,无论用例。筛选的大量历史数据,不断发展的机器学习的复杂性和深度学习技术,和非常小的数量的实际例子的欺诈行为与发现海里捞针虽然不知道针的样子。在金融服务业,增加对安全性和解释的重要性的关注欺诈行为被确认进一步增加了任务的复杂性。

建立这些检测模式,一个领域专家团队提出了一个基于骗子通常的行为的规则集。工作流可能包括一个主题专家在金融欺诈检测空间放在一起一组要求一个特定的行为。数据科学家可能会拿一个可用的子样本数据并选择一组深度学习或机器学习算法使用这些需求和可能是一些已知的诈骗案件。数据工程师把模式在生产中可能产生的模型转换为与阈值的一组规则,经常使用SQL实现。
这种方法允许金融机构提供一套清晰的特点,导致识别欺诈性交易,符合一般的数据保护监管(GDPR)。然而,这种方法也会带来许多困难。欺诈检测系统的实现使用一个硬编码的规则集是非常脆弱。对欺诈模式的任何更改将花费很长的时间来更新。反过来,这很难跟上和适应欺诈活动的转变发生在当前的市场。
此外,在上面描述的工作流系统往往是孤立的,领域专家,数据科学家,和数据工程师所有的区分。数据工程师负责维护大量的数据和翻译领域专家和数据科学家的工作代码投入生产水平。由于缺乏共同的平台,科学家不得不依赖领域专家和数bob体育客户端下载据采样数据,适合在单个机器上进行分析。这导致沟通困难,最终缺乏协作。
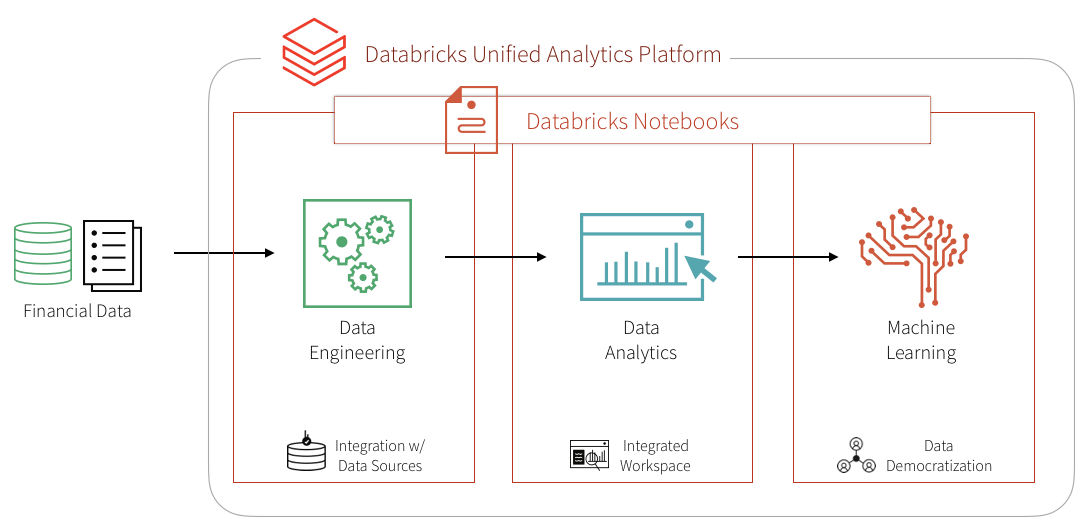
在这个博客中,我们将展示如何将几个这样的基于规则的检测用例转换成机器学习用例在砖平台,统一的关键球员在欺诈检测:领域专家,数据科学家,和数据工程师。bob体育客户端下载我们将学习如何创建一个管道和机器学习欺诈检测数据实时可视化数据利用的框架构建模块化特性从大型数据集。我们还将学习如何使用决策树和Apache火花MLlib检测欺诈行为。我们将使用MLflow迭代和优化模型来提高其准确性。
解决与机器学习
有一定程度的不情愿对机器学习模型在金融世界认为提供一个“黑盒”的解决方案,没有办法证明所确定的欺诈案件。GDPR需求,以及金融监管,使其看似不可能的利用数据科学的力量。然而,一些成功的用例表明,大规模机器学习应用到检测欺诈行为可以解决上述问题。
培训监督机器学习模型来检测金融欺诈是非常困难的因为数量少,实际确认的欺诈行为的例子。然而,存在一个已知的规则集,确定一个特定类型的欺诈可以帮助创建一组合成标签和一组初始的特性。检测的输出模式,开发了领域专家在该领域可能已经过适当的审批流程在生产。旗帜和可能产生预期的欺诈行为,因此,作为一个起点培训机器学习模型。这同时,缓解了三个问题:
- 缺乏训练的标签,
- 决定使用什么功能,
- 有一个适当的基准模型。
训练一个机器学习模型来识别标志提供了一个基于规则的欺诈行为直接比较预期的输出通过混淆矩阵。提供基于规则的检测结果匹配的模式,这种方法有助于获得信心在基于机器学习的欺诈防范的怀疑论者。这个模型的输出很容易解释,可能作为讨论的基准预期的假阴性和假阳性相比原来的检测模式。
此外,关注与机器学习模型很难解释可能进一步减轻如果决策树模型作为初始的机器学习模型。因为模型正在训练一组规则,决策树可能比任何其他机器学习模型。额外的好处是,当然,最透明的模型,这将基本上显示欺诈行为的决策过程,但没有人工干预,需要硬编码任何规则或阈值。当然,它必须明白,未来的迭代模型可能使用一个完全不同的算法,以达到最大程度的准确性。模型的透明度最终是通过理解进了算法的特性。有可判断的特性将产生可翻译的和可靠的模型结果。
机器学习方法的最大好处是,在最初的建模工作之后,未来的迭代模块化和更新的标签,特性,或模型类型很容易和无缝,减少生产的时间。这是进一步促进砖领域专家统一的分析平台,数据科学家,工程师可能工作在相同的数据集规模和合作在bob体育亚洲版笔记本中直接环境。bob体育客户端下载所以让我们开始吧!
摄取和探索数据
我们将使用这个例子的合成数据集。加载数据集,请下载它从Kaggle到您的本地机器上,然后通过导入数据,导入数据Azure和AWS
PaySim数据基于样本来模拟移动货币交易的交易从一个月的金融日志中提取从一个移动货币服务中实现一个非洲国家。下面的表显示了数据集的信息提供:
探索数据
创建DataFrames——既然我们已经上传数据砖文件系统(DBFS),我们可以快速、轻松地创建DataFrames使用火花SQL
#创建df DataFrame这包含我们的模拟金融欺诈检测数据集df=火花。sql(“选择步骤中,类型、数量、nameOrig oldbalanceOrg newbalanceOrig,命名,oldbalanceDest, newbalanceDest sim_fin_fraud_detection”)现在,我们已经创建了DataFrame,让我们看看模式和第一个几千行审核数据。
#检查数据的模式df.printSchema ()根| - - -步骤:整数(可空=真正的)| - - -类型:字符串(可空=真正的)|——数量:双(可空=真正的)|——nameOrig:字符串(可空=真正的)|——oldbalanceOrg:双(可空=真正的)|——newbalanceOrig:双(可空=真正的)|——命名:字符串(可空=真正的)|——oldbalanceDest:双(可空=真正的)|——newbalanceDest:双(可空=真正的)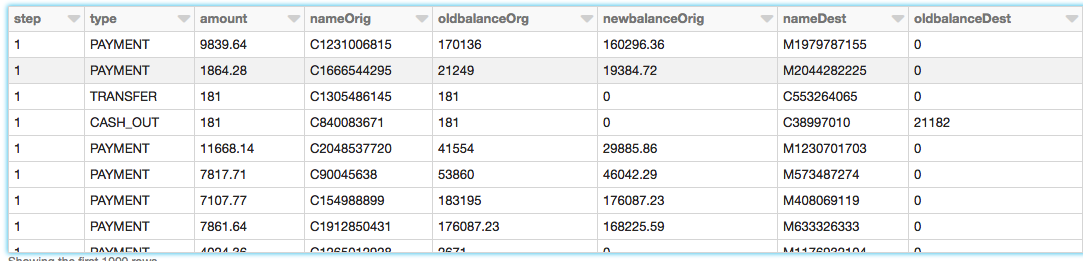
类型的交易
让我们可视化数据理解交易的类型数据捕获和整体交易量的贡献。
![]()
来了解我们谈论的是多少钱,我们也可视化数据基于交易的类型和他们的贡献的现金转移(即金额(金额))。
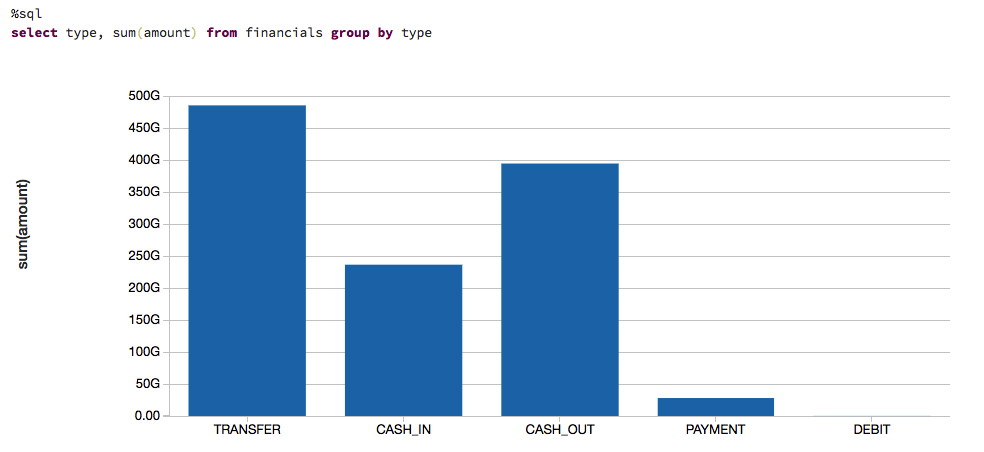
基于规则的模型
我们不可能从一个大型数据集的欺诈案件来训练我们的模型。在大多数实际应用中,欺诈检测模式是由一组规则建立的领域专家。在这里,我们创建一个列标签基于这些规则。
#规则识别舞弊df = df.withColumn (“标签”,F.when (((df.oldbalanceOrg56900年)& (df.newbalanceOrig56900年)& (df.newbalanceOrig>12)& (df。量>1160000)),1).otherwise (0))可视化标记的数据规则
这些规则通常国旗相当大量的欺诈案件。让我们想象标记事务的数量。我们可以看到规则旗大约4%的病例和11%的总金额为作弊。
![]()
选择合适的机器学习模型
在许多情况下,一个黑盒子方法不能使用欺诈检测。首先,领域专家需要能够理解为什么一个事务被认定为欺诈。如果是采取行动,在法庭上提供的证据必须。决策树是一个更容易解释的模型和这个用例是一个伟大的起点。
创建一个训练集
毫升模型构建和验证,我们将做一个80/20分割使用.randomSplit。这将留出一个随机选择的培训和剩下的20% 80%的数据来验证结果。
#分裂之间训练数据集和测试数据集(火车、测试)= df.randomSplit ([0.8,0.2),种子=12345年)创建毫升管道模型
准备的数据模型,我们必须首先分类变量转换为数字.StringIndexer。然后我们必须组装的所有功能我们想为模型使用。我们创建一个管道来包含这些特性制备步骤除了决策树模型,在不同的数据集可能重复这些步骤。注意,我们适应管道先训练数据,然后使用它来改变我们的测试数据在后面的步骤。
从pyspark.ml进口管道从pyspark.ml.feature进口StringIndexer从pyspark.ml.feature进口VectorAssembler从pyspark.ml.classification进口DecisionTreeClassifier#标签的编码字符串列索引的列标签索引器= StringIndexer (inputCol =“类型”outputCol =“typeIndexed”)# VectorAssembler变压器相结合是一个给定的列成一个向量列的列表弗吉尼亚州= VectorAssembler (inputCols = (“typeIndexed”,“数量”,“oldbalanceOrg”,“newbalanceOrig”,“oldbalanceDest”,“newbalanceDest”,“orgDiff”,“destDiff”),outputCol =“特征”)#使用DecisionTree分类器模型dt = DecisionTreeClassifier (labelCol =“标签”featuresCol =“特征”种子=54321年maxDepth =5)#创建管道阶段管道=管道(阶段=[索引器,弗吉尼亚州,dt])#查看决策树模型(CrossValidator之前)dt_model = pipeline.fit(火车)可视化模型
调用显示()在最后阶段的管道,这是决策树模型,允许我们查看初始安装和每个节点的选择决策模型。这有助于理解算法到达最终的预测。
显示器(dt_model.stages [1])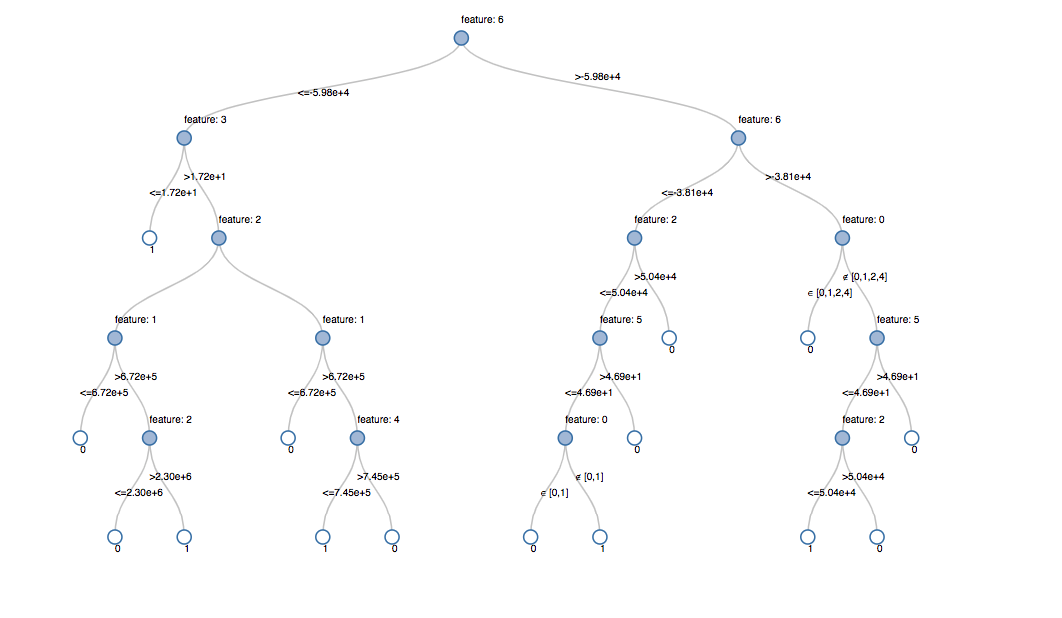
模型优化
树,以确保我们有最好的拟合模型,我们将与几个旨在模型参数变化。鉴于我们的数据由负96%和4%的阳性病例,我们将使用Precision-Recall (PR)评价指标占不平衡分布。
< b >从< / b > pyspark.ml。调优< b >进口< / b > CrossValidator ParamGridBuilder#构建电网不同的参数paramGrid = ParamGridBuilder () \.addGrid (dt。maxDepth, (5,10,15])\.addGrid (dt。maxBins, (10,20.,30.])\.build ()#构建交叉验证crossval = CrossValidator(估计量= dt,estimatorParamMaps = paramGrid,评估者= evaluatorPR,numFolds =3)#建立简历管道pipelineCV =管道(阶段=[索引器,弗吉尼亚州,crossval])#训练使用管道模型,参数网格和前BinaryClassificationEvaluatorcvModel_u = pipelineCV.fit(火车)模型的性能
我们评估模型通过比较Precision-Recall(公关)和ROC曲线下面积(AUC)度量的训练集和测试集。公关和AUC似乎很高。
#构建最好的模型(训练和测试数据集)train_pred = cvModel_u.transform(火车)test_pred = cvModel_u.transform(测试)#评估模型训练数据集pr_train = evaluatorPR.evaluate (train_pred)auc_train = evaluatorAUC.evaluate (train_pred)#评估模型的测试数据集pr_test = evaluatorPR.evaluate (test_pred)auc_test = evaluatorAUC.evaluate (test_pred)#打印出公关和AUC值打印(“公关培训:“pr_train)打印(”AUC训练:“auc_train)打印(“公关测试:”pr_test)打印(“AUC测试:“auc_test)
推荐- - - - - -#输出:#公关培训:0.9537894984523128# AUC火车:0.998647996459481#公关测试:0.9539170535377599# AUC测试:0.9984378183482442看看模型分类错误的结果,让我们使用matplotlib和熊猫来可视化混淆矩阵。
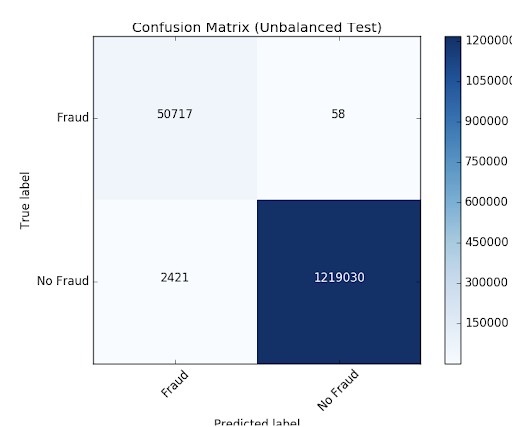
平衡类
我们可以看到,该模型比原标识2421多例规则确定。这不是一样惊人的检测更潜在的欺诈案件可能是一件好事。然而,有58例未检测到的算法,但最初识别。我们将试图提高我们预测进一步平衡我们的类使用欠采样。,我们将保留所有的欺诈案件,然后downsample non-fraud案件匹配数量平衡的数据集。当我们可视化新数据集,我们可以看到,是的,没有病例的50/50。
#重置DataFrames没有欺诈(dfn)和欺诈(dfy)dfn =火车。过滤器(火车。标签==0)dfy =火车。过滤器(火车。标签==1)#计算汇总指标N = train.count ()y = dfy.count ()p = y / N#创建一个更加平衡的训练数据集train_b = dfn.sample (< b >假< / b > p种子=92285年).union (dfy)#输出指标打印(“总数:% s,诈骗案件数:% s,诈骗案件的比例:% s”% (N, y, p))打印(“平衡训练数据集计数:% s”% train_b.count ())
推荐- - - - - -#输出:#总数:5090394,诈骗案件数:204865,诈骗案件的比例:0.040245411258932016#平衡训练数据集数:401898推荐- - - - - -#显示更加平衡的训练数据集显示器(train_b.groupBy (“标签”).count ())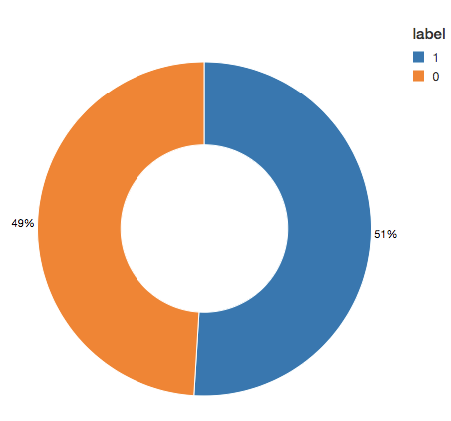
更新管道
现在让我们更新毫升管道并创建一个新的交叉验证器。因为我们使用毫升管道,我们只需要更新新的数据集,我们可以快速重复相同的管道的步骤。
#重新运行相同的ML管道(包括参数网格)crossval_b = CrossValidator(估计量= dt,estimatorParamMaps = paramGrid,评估者= evaluatorAUC,numFolds =3)pipelineCV_b =管道(阶段=[索引器,弗吉尼亚州,crossval_b])#训练使用管道模型,参数网格和BinaryClassificationEvaluator使用train_b数据集cvModel_b = pipelineCV_b.fit (train_b)#构建最好的模型(平衡训练和完整的测试数据集)train_pred_b = cvModel_b.transform (train_b)test_pred_b = cvModel_b.transform(测试)#评估模型平衡训练数据集pr_train_b = evaluatorPR.evaluate (train_pred_b)auc_train_b = evaluatorAUC.evaluate (train_pred_b)#评估模型完整的测试数据集pr_test_b = evaluatorPR.evaluate (test_pred_b)auc_test_b = evaluatorAUC.evaluate (test_pred_b)#打印出公关和AUC值打印(“公关培训:“pr_train_b)打印(”AUC训练:“auc_train_b)打印(“公关测试:”pr_test_b)打印(“AUC测试:“auc_test_b)
推荐- - - - - -#输出:#公关培训:0.999629161563572# AUC火车:0.9998071389056655#公关测试:0.9904709171789063# AUC测试:0.9997903902204509审查结果
现在让我们来看看我们的新混淆矩阵的结果。这个模型只有一个欺诈案件的面孔。平衡类似乎提高了模型。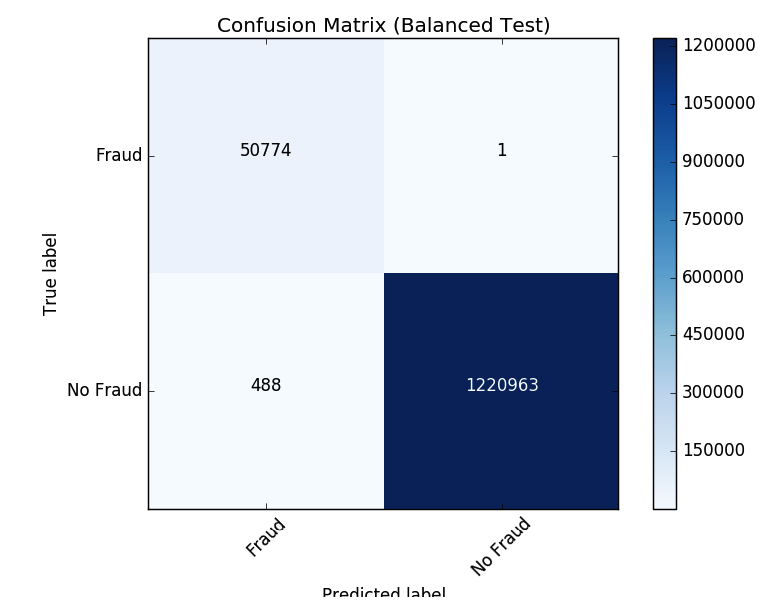
反馈和使用MLflow模型
一旦选择了一个模型,用于生产,我们希望不断收集反馈,以确保模型仍然是识别感兴趣的行为。因为我们的起点是一个基于规则的标签,我们要供应未来模型与基于人类反馈验证正确标签。这个阶段是至关重要的维持信心和信任的机器学习的过程。因为分析师不能审查每一个情况下,我们要确保我们为他们带来了精心挑选的案例来验证模型的输出。例如,预测,确定性模型低,是很好的候选人分析师审查。添加这种类型的反馈将确保模型将继续改善和发展与变化的景观。
MLflow帮助我们在这个周期是我们训练不同的模型版本。我们可以跟踪实验,比较不同模型的结果和参数配置。例如在这里,我们可以比较模型的公关和AUC训练平衡和不平衡的数据集使用MLflow UI。数据科学家可以使用MLflow跟踪各种模型的指标和任何额外的可视化和工件帮助决定哪些模型应该部署在生产。数据工程师将能够轻松地检索所选择的模型和使用的库版本培训作为一个. jar文件部署在生产新的数据。因此,领域专家之间的合作评估模型结果,科学家们更新的数据模型和数据工程师在生产部署模型,将加强在整个迭代过程。
https://www.youtube.com/watch?v=x_4S9r-Kks8
https://www.youtube.com/watch?v=BVISypymHzw
结论
我们回顾了如何使用基于规则的一个例子欺诈检测标签,将它转换成一个机器学习模型与MLflow使用砖。这种方法使我们能够建立一个可伸缩的、模块化的解决方案,将帮助我们跟上不断变化的欺诈行为模式。建立一个机器学习模型来识别欺诈允许我们创建一个反馈回路,使得模型进化和识别新的潜在欺诈模式。我们已经知道了一个决策树模型,特别是,是一个伟大的起点引入机器学习欺诈检测项目由于其解释能力和优秀的准确性。
使用砖平台的主要优点是,它允许数据科学家,工程师和业务用户在整个过程中无缝地协同bob体育客户端下载工作。准备数据,建立模型,分享成果,并把模型投入生产现在可以发生在同一平台,允许前所未有的合作。bob体育客户端下载这种方法在先前孤立的团队建立信任,导致一个有效和动态欺诈检测程序。
试试这个笔记本通过注册一个免费试用几分钟,开始创建您自己的模型。