如何从4.5小时加速需求规划和Azure砖下1小时吗




供应链分析的重要性
快速变化的消费购买行为可以产生实质性影响供应链规划、库存管理和业务结果。消费需求的准确预测是优化盈利能力的起点和其他业务的结果。斯威夫特库存调整在分销网络是至关重要的,以确保供应满足消费者需求,同时最小化运输成本。此外,消费者赎回季节性提供购买插件和影响产品供应和物流规划的订阅。
在ButcherBox供应链分析
ButcherBox面临极其复杂的需求规划,因为它试图确保库存足够的交货期,满足高度可变的客户订单偏好,导航预测客户注册和管理物流配送等。它需要一个预测解决方案来应对这些挑战,适应快速、紧密集成的Azure房地产数据。
“虽然ButcherBox cloud-born,我们所有的团队使用电子表格,“吉米·库珀说,头的数据,ButcherBox。“正因为如此,我们在使用过时的数据发表的一份报告。这是一个非常不同的世界,现在我们正在与Azure砖。”
ButcherBox精简供应链分析如何
ButcherBox使用Azure砖生成其需求计划。当Azure数据工厂(ADF)触发需求计划来看,Azure砖从Azure数据流程供应链数据的湖,供应商和蜂巢缓存数据。湖新输出存储在一个数据,然后Azure突触更新需求计划生产可视化。

ButcherBox利用Azure砖摄取所有实时的原始数据流从供应商、内部来源和历史数据。Azure砖相此数据项,框和分配水平需求的用户查看即将到来的一年。然后将这些数据用于保留建模和推到Azure突触的历史比较。
Apache火花SQL Azure砖设计是兼容的Apache蜂巢。ButcherBox使用蜂巢从CSV文件缓存数据,然后处理缓存的数据在Azure砖,使需求计划计算时间从4.5小时减少到少于一个小时。这使一个更新的需求计划为业务用户提供每天早上来帮助决策。摄入这些数据流也为其他进程创造了值得信赖的数据集和消费的活动。这些新的工具和能力帮助ButcherBox迅速理解和适应成员行为的变化,尤其是在他COVID-19大流行。
创建您的第一个需求预测使用Azure砖
为需求预测开始使用Azure砖,下载这个示例的笔记本并将其导入Azure砖工作区。
步骤1:加载存储项目销售数据
我们的训练数据集是五年的事务数据在10个不同的商店。我们将定义一个模式,我们的数据读入DataFrame为后续的查询,然后创建一个临时视图。
从pyspark.sql.types进口*#训练数据集的结构train_schema = StructType ([StructField (“日期”DateType ()),StructField (“存储”IntegerType ()),StructField (“项目”IntegerType ()),StructField (“销售”IntegerType ())])#培训文件读入dataframe火车= spark.read.csv (' / FileStore /表/ demand_forecast /火车/ train.csv”,头=真正的,模式= train_schema)#让dataframe可查询作为临时视图train.createOrReplaceTempView (“火车”)步骤2:检查数据
聚集在月级别的数据,我们可以观察到一个可识别的年度季节性模式,随着时间的增长。我们可以调整我们的查询来寻找其他模式,如每周的季节性和整体销售增长。
步骤3:组装历史数据集
从我们以前的加载数据,我们可以构建一个熊猫DataFrame通过查询“训练”临时视图,然后删除任何缺失的值。
#查询汇总数据到目前为止(ds)的水平sql_statement =“‘选择ds(日期日期),销售为y从火车在商店= 1 = 1项ORDER BY ds“‘#在熊猫dataframe组装数据集history_pd = spark.sql (sql_statement) .toPandas ()#删除任何丢失的记录history_pd = history_pd.dropna ()第四步:建立模型
根据勘探的数据,我们需要设置模型参数根据观察到的增长和季节模式。因此,我们选择了一个线性增长模式,使每周的评价和每年的季节性模式。我们的模型参数设置后,我们可以很容易地适应历史模型,数据清洗。
#设置模型参数模型=先知(interval_width =0.95,增长=“线性”,daily_seasonality =假,weekly_seasonality =真正的,yearly_seasonality =真正的,seasonality_mode =“乘法”)#适合模型的历史数据model.fit (history_pd)第五步:使用训练模型来构建一个90天的预测
由于我们的模型是训练有素的,我们可以用它来建立一个预测类似ButcherBox使用在他们的需求计划。这可以很快完成使用历史数据如下所示。
#定义一个数据集包括历史日期和超越过去的可用日期90天future_pd = model.make_future_dataframe (时间=90年,频率=' d ',include_history =真正的)#预测数据集forecast_pd = model.predict (future_pd)
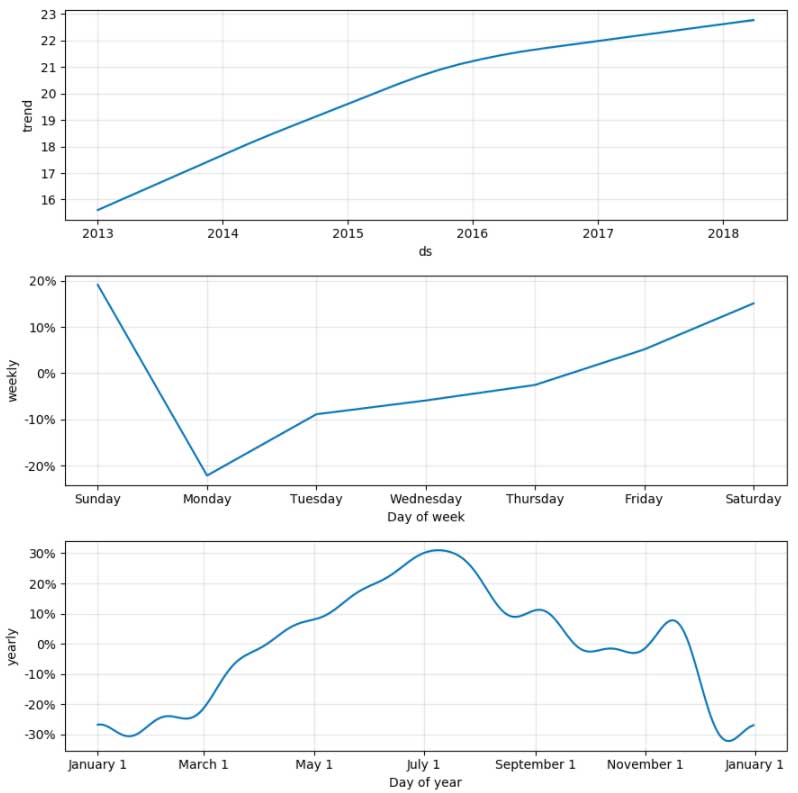
显示器(forecast_pd)一旦我们预测未来的数据集,我们可以生产一般和季节性趋势在我们的模型图(如下所示)。
trends_fig = model.plot_components (forecast_pd)显示器(trends_fig)