配置三角洲湖控制数据文件大小
三角洲湖提供选择手动或自动配置的目标文件大小和写道优化操作。砖自动调这些设置,并支持特性,通过寻求调整文件自动提高表性能。
请注意
在砖运行时的13.2及以上,砖建议使用集群为三角洲表布局。看到使用液体集群为三角洲表。
为统一目录管理表,砖曲调的大多数这些配置自动如果你使用一个SQL仓库或砖运行时11.3 LTS或以上。
请注意
除非另有规定,本文中所有的建议不适用于统一目录管理表运行最新的运行时。
当运行优化
汽车压实和优化写每个减少小文件的问题,但不完全替代优化。特别是对于表超过1 TB,砖建议运行优化安排进一步巩固文件。砖不自动运行ZORDER在桌子上,所以你必须运行优化与ZORDER启用增强数据跳过。看到数据不与z顺序索引三角洲湖。
汽车优化数据砖是什么?
这个词自动优化有时是用来描述功能控制的设置delta.autoOptimize.autoCompact和delta.autoOptimize.optimizeWrite。这学期已经退休的描述每个单独设置。看到汽车压实对砖三角洲湖和优化为三角洲湖砖。
汽车压实对砖三角洲湖
汽车压实结合δ内小文件表分区自动减少小文件的问题。汽车压实后发生写入表已成功同步并运行在集群上执行写入。汽车只压缩压缩文件,没有压实。
你可以通过设置来控制输出文件的大小火花配置spark.databricks.delta.autoCompact.maxFileSize。砖建议使用自动调谐根据工作负载或表的大小。看到基于工作负载的自动调谐文件大小和基于表的大小自动调谐文件大小。
汽车压实只是触发分区或表至少有一定数量的小文件。你可以选择改变触发汽车所需的最小数量的文件压缩设置spark.databricks.delta.autoCompact.minNumFiles。
汽车压实可以启用表或会话级别使用以下设置:
表属性:
delta.autoOptimize.autoCompactSparkSession设置:
spark.databricks.delta.autoCompact.enabled
这些设置接受以下选项:
选项 |
行为 |
|---|---|
|
曲调目标文件的大小,同时尊重其他自动调谐功能。需要砖运行时的10.1或以上。 |
|
别名 |
|
使用128 MB作为目标文件大小。没有动态分级。 |
|
关闭自动压实。在会话级别可以设置覆盖汽车压实所有三角洲表修改的工作量。 |
重要的
在砖10.3运行时,下面的,当其他作家执行操作删除,合并,更新,或优化同时,汽车压实可以导致其他工作失败,事务冲突。这不是一个问题在砖运行时10.4及以上。
优化为三角洲湖砖
优化写改善文件大小数据写入和后续读取表中受益。
分区表的优化中是最有效的,因为他们减少小文件写入每个分区。写更少的大文件比写作更有效的许多小文件,但你仍然会看到增加写延迟,因为数据是之前写的。
下图演示了如何优化工作写道:
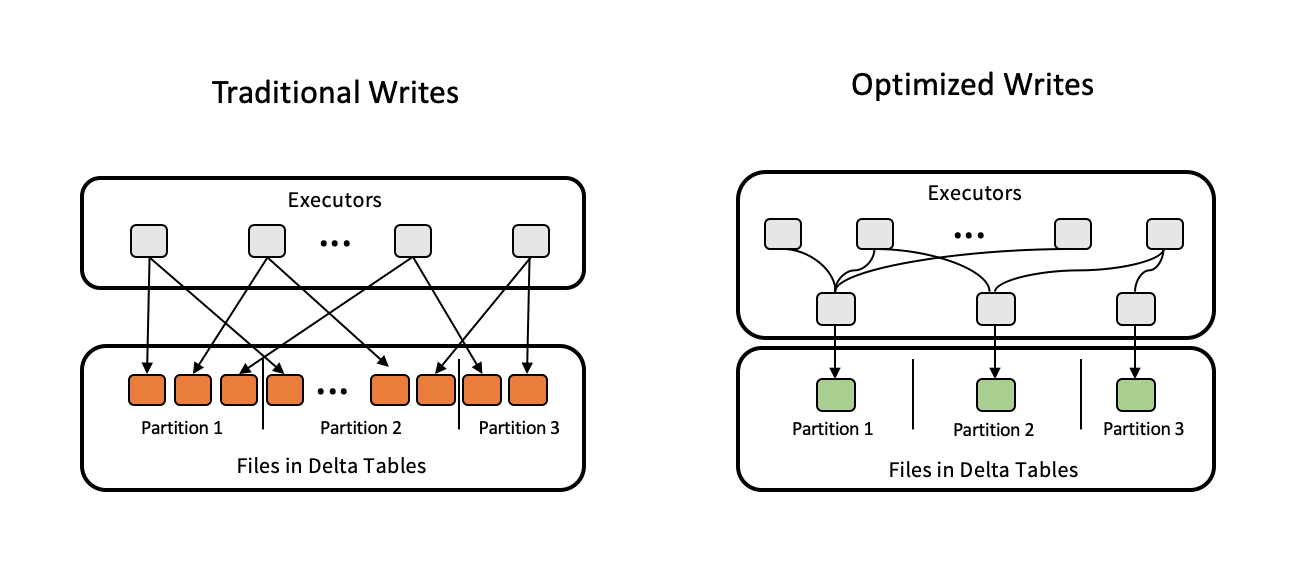
注意:你可能会运行的代码合并(n)或重新分区(n)之前你写出数据到控制文件的数量。优化写道消除了需要使用此模式。
优化写在砖是默认启用以下业务运行时9.1 LTS及以上:
合并更新与子查询删除与子查询
优化也支持写道商品交易顾问基金语句和插入当使用SQL仓库操作。在砖运行时的13.1及以上,所有注册表三角洲统一目录启用了优化写道商品交易顾问基金语句和插入分区表的操作。
优化写在表或会话级别可以启用使用以下设置:
表设置:
delta.autoOptimize.optimizeWriteSparkSession设置:
spark.databricks.delta.optimizeWrite.enabled
这些设置接受以下选项:
选项 |
行为 |
|---|---|
|
使用128 MB作为目标文件大小。 |
|
关闭优化写道。在会话级别可以设置覆盖汽车压实所有三角洲表修改的工作量。 |
设定了一个目标文件大小
请注意
在砖运行时8.2及以上。
如果你想在三角洲调整大小的文件表,设置表属性delta.targetFileSize到所需的尺寸。如果设置了这个属性,所有数据布局优化操作将最优试图生成指定大小的文件。例子包括优化或z值,汽车压实,优化写道。
请注意
当使用统一目录管理表和SQL仓库或砖运行时11.3 LTS以上,优化命令尊重targetFileSize设置。
表属性 |
|---|
delta.targetFileSize 类型:大小的字节或更高的单位。 目标文件大小。例如, 默认值:无 |
对于现有的表,您可以使用SQL命令设置和设置属性ALTER TABLE设置资源的属性。你也可以设置这些属性时自动创建新表使用火花会话配置。看到三角洲表属性引用获取详细信息。
基于工作负载的自动调谐文件大小
请注意
在砖运行时8.2及以上。
砖建议设置表属性delta.tuneFileSizesForRewrites来真正的对所有表的目标很多合并或DML操作,无论砖运行时,统一目录,或其他优化。当设置为真正的,目标文件大小为表设置为更低的阈值,而加速写密集型操作。
如果没有显式地设置,砖自动检测如果9 10前三角洲表上的操作合并操作和设置这个表属性真正的。您必须显式地设置该属性假为了避免这种行为。
表属性 |
|---|
delta.tuneFileSizesForRewrites 类型: 是否为数据布局优化调整文件大小。 默认值:无 |
对于现有的表,您可以使用SQL命令设置和设置属性ALTER TABLE设置资源的属性。你也可以设置这些属性时自动创建新表使用火花会话配置。看到三角洲表属性引用获取详细信息。
基于表的大小自动调谐文件大小
请注意
在砖运行时8.4及以上。
最小化需要手动调整,砖自动曲调δ的文件大小表基于表的大小。砖将使用较小的文件大小对于小表,较大的文件大小为大表,表中文件数量不能过大。砖不自动调谐表有调整特定的目标大小或根据工作负载频繁的重写。
目标文件大小是基于当前三角洲表的大小。表小于2.56结核病、自动调谐的目标表的文件大小是256 MB。2.56结核病和10 TB之间的大小,目标规模将从256 MB到1 GB呈线性增长。表大于10 TB,目标文件的大小是1 GB。
请注意
当一个表的目标文件大小增加,现有的文件不是优化成更大的文件优化命令。一个大表可以因此总是有一些文件小于目标大小。如果是需要优化这些较小的文件到较大的文件,您可以配置一个固定的目标文件大小的表使用delta.targetFileSize表属性。
当一个表写增量,目标文件大小和文件数量将接近下面的数字,基于表的大小。这个表的文件数量只是一个例子。实际结果会有所不同取决于很多因素。
表的大小 |
目标文件大小 |
近似的文件数量表 |
|---|---|---|
10 GB |
256 MB |
40 |
1 TB |
256 MB |
4096年 |
2.56结核病 |
256 MB |
10240年 |
3结核病 |
307 MB |
12108年 |
5结核病 |
512 MB |
17339年 |
7结核病 |
716 MB |
20784年 |
10 TB |
1 GB |
24437年 |
20结核病 |
1 GB |
34437年 |
50个结核病 |
1 GB |
64437年 |
100年结核病 |
1 GB |
114437年 |
限制行写入数据文件
全心全意、表与狭窄的数据可能会遇到一个错误,在一个给定的数据文件的行数超过限制的支持拼花的格式。为了避免这种错误,您可以使用SQL会话配置spark.sql.files.maxRecordsPerFile指定的最大记录数为三角洲湖表写入一个文件。指定一个值为零或负值代表没有限制。
在砖运行时的10.5及以上,您还可以使用DataFrameWriter选项maxRecordsPerFile当使用DataFrame api编写到三角洲湖表。当maxRecordsPerFile指定的值SQL会话配置spark.sql.files.maxRecordsPerFile将被忽略。
请注意
砖不建议使用此选项,除非它是必要的,以避免上述错误。此设置可能仍然需要一些非常狭窄的数据统一目录管理表。