教程:使用笔记本查询数据
本教程将引导您使用Databricks Data Science & Engineering工作空间创建集群和笔记本、从数据集创建表、查询表以及显示查询结果。
提示
作为本文的补充,请尝试在Databricks数据科学与工程登录页上提供的快速入门教程。这是一个5分钟的动手介绍Databricks。当您登录Databricks时,请查找指南:快速入门教程2 .在首页单击开始教程.
如果您没有看到教程,请从侧栏中的角色切换器中选择Data Science & Engineering。
你也可以使用Databricks Terraform提供商创建本文的资源。看到使用Terraform创建集群、笔记本和作业.
需求
您已经登录到Databricks,并且处于Data Science & Engineering工作区。看到开始:免费试用和安装.
数据科学与工程UI

从左边栏和常见的任务在登录页面上,您可以访问Databricks Data Science & Engineering的基本实体:工作区、集群、表、笔记本电脑、作业和库。工作空间是一个特殊的根文件夹,用于存储Databricks资产(如笔记本和库)以及导入的数据。

 在人物角色旁边。再次单击以移除引脚。
在人物角色旁边。再次单击以移除引脚。
步骤1:创建集群
集群是Databricks计算资源的集合。创建集群。
在侧栏中,单击
 计算.
计算.在“计算池”页面,单击创建计算.
在“新建计算”页面,选择11.3 LTS ML (Scala 2.12, Spark 3.3.0)从Databricks运行时版本下拉菜单。
点击创建集群.
步骤2:创建一个笔记本
笔记本是在Apache Spark集群上运行计算的单元格的集合。在工作区中创建一个笔记本:
在侧栏中,单击
 工作空间.
工作空间.在工作区文件夹中,选择
 创建>笔记本.
创建>笔记本.
在“创建笔记本”对话框中,输入一个名称并选择SQL在“语言”下拉菜单中。这个选择决定了默认的语言笔记本的。
点击创建.笔记本打开时,顶部有一个空单元格。
将笔记本附加到您创建的集群。单击笔记本工具栏中的集群选择器,从下拉菜单中选择您的集群。如果没有看到您的集群,请单击更多…并从对话框中的下拉菜单中选择集群。

步骤3:创建表
中提供的示例CSV数据文件中的数据创建一个表样本数据集的数据集集合什么是数据库文件系统(DBFS)?,是安装在Databricks集群上的分布式文件系统。创建表有两个选项。
选项1:根据CSV数据创建Spark表
如果您想要快速运行,并且只需要标准的性能级别,可以使用此选项。复制并粘贴以下代码片段到一个笔记本单元格:
下降表格如果存在钻石;创建表格钻石使用CSV选项(路径“/ databricks-datasets / Rdatasets /数据- 001 / csv / ggplot2 / diamonds.csv”,头“真正的”)
选项2:将CSV数据写入Delta Lake格式并创建Delta表
三角洲湖提供强大的事务存储层,支持快速读取和其他好处。Delta Lake格式由Parquet文件和事务日志组成。使用此选项可在表上的未来操作上获得最佳性能。
将CSV数据读入DataFrame并以Delta Lake格式写入。该命令使用Python语言魔术命令,它允许您使用笔记本默认语言(SQL)以外的其他语言来交错命令。复制并粘贴以下代码片段到一个笔记本单元格:
%python钻石=(火花.读.格式(“csv”).选项(“头”,“真正的”).选项(“inferSchema”,“真正的”).负载(“/ databricks-datasets / Rdatasets /数据- 001 / csv / ggplot2 / diamonds.csv”))钻石.写.格式(“δ”).保存(“/ mnt /δ/钻石”)
在存储位置创建Delta表。复制并粘贴以下代码片段到一个笔记本单元格:
下降表格如果存在钻石;创建表格钻石使用δ位置“/ mnt /δ/钻石”
按下运行单元格Shift + enter.笔记本自动附加到步骤2中创建的集群,并在单元格中运行该命令。
步骤4:查询表
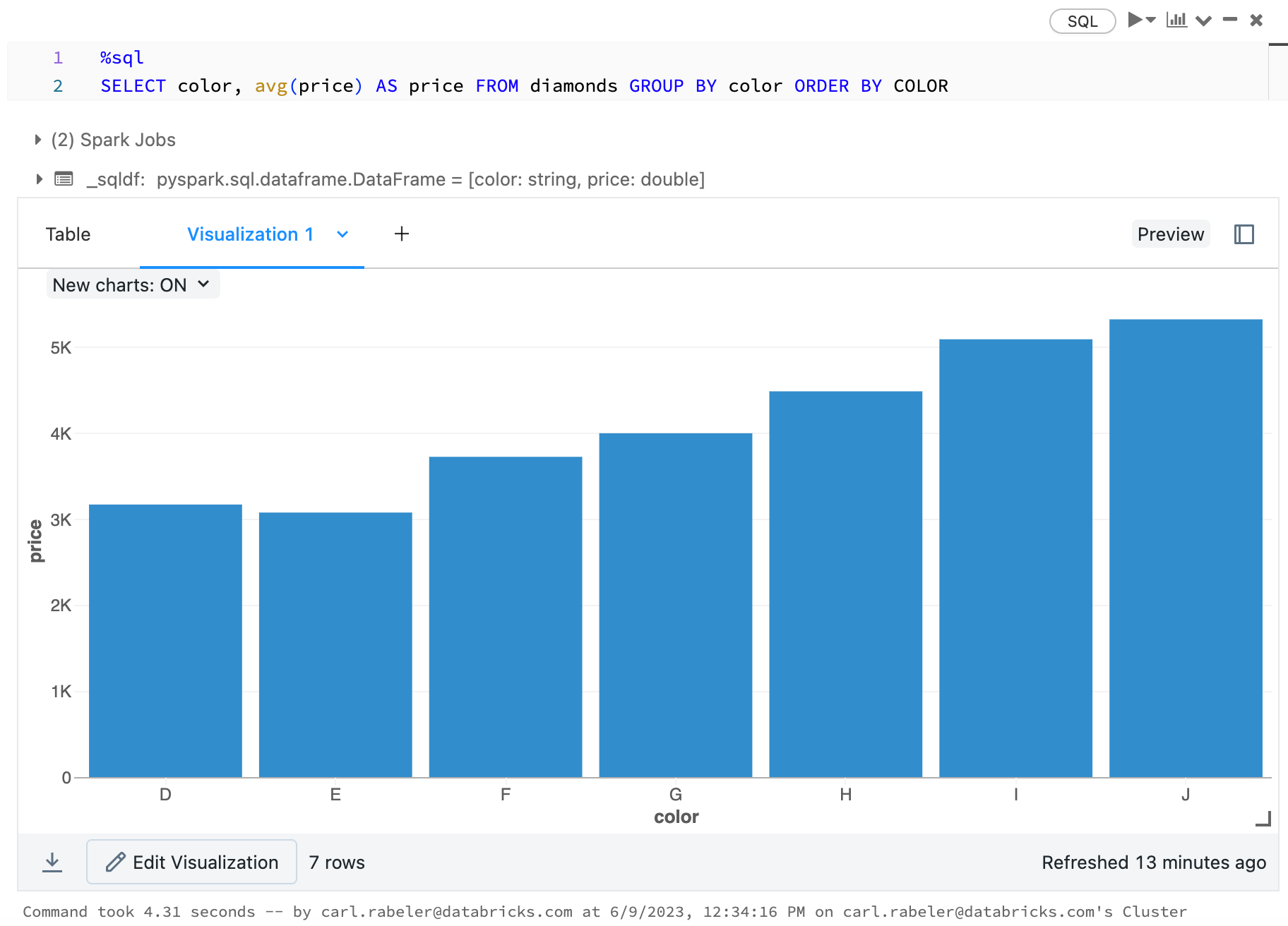
运行SQL语句以按颜色查询钻石的平均价格。
若要将单元格添加到笔记本,请将鼠标移到单元格底部并单击
 图标。
图标。
复制此代码片段并将其粘贴到单元格中。
选择颜色,avg(价格)作为价格从钻石集团通过颜色订单通过颜色
新闻Shift + enter.笔记本上显示了钻石颜色和平均价格的表格。

 图标。
图标。

 .
.