使用时间序列特性表时间点支持
砖特性存储支持用例要求时间点的正确性。
数据用于训练模型通常内置的时间依赖关系。举个例子,如果你正在训练一个模型来预测哪些机器需要维护一个工厂,你可能有历史数据集包含传感器测量数据和使用数据对许多机器,随着目标标签表明如果机器需要服务。机器的数据集可能包含数据之前和之后都进行维修服务。
构建模型时,您必须考虑只有特性值直到时间的观察到目标值(需要服务或不需要的服务)。如果你没有明确考虑每个观测的时间戳,你可能无意中使用特征值测量目标的时间戳值后培训。这就是所谓的“数据泄漏”,可以对模型的性能产生不利影响。
时间序列特征表包含一个时间戳键列,确保训练数据集的每一行表示的最新特性值称为行的时间戳。您应该使用时间序列特征表特征值随时间变化时,例如时间序列数据,基于事件的数据,或time-aggregated数据。
请注意
时间序列特征表如何工作的呢
假设你有以下特性表。这些数据来自例如笔记本电脑。
表包含传感器数据测量温度,相对湿度,环境光和二氧化碳在一个房间里。地面真值表表明如果一个人出现在房间里。每个表的主键(“房间”)和一个时间戳(ts)的关键。为简单起见,只有一个值的数据主键(“0”)。
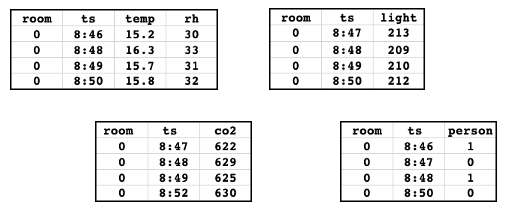
下图说明了时间戳的关键是用于确保时间点训练数据集的正确性。特征值匹配基于主键(图中未显示)和时间戳键,使用一个连接。最近加入的是确保特性时的时间戳值用于训练集。
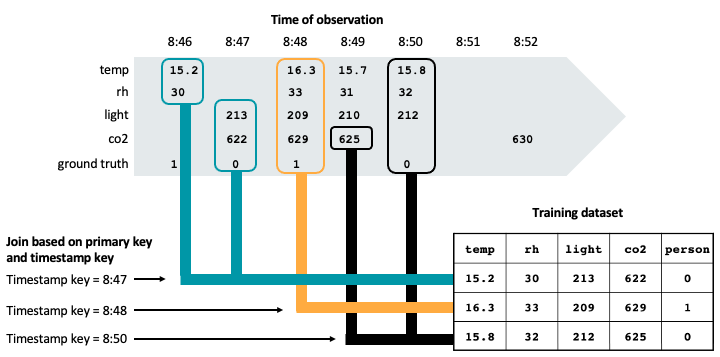
如图,训练数据集包括最新的每个传感器特性值之前观察地面上的时间戳的真理。
如果您创建了一个训练数据集不考虑时间戳键,您可能有一个行用这些特征值和观察地面的真相:
临时 |
rh |
光 |
二氧化碳 |
地面实况 |
|---|---|---|---|---|
15.8 |
32 |
212年 |
630年 |
0 |
然而,这不是一个有效的观察训练,因为630年的二氧化碳阅读,在落地后观察地面真理,14日。未来数据训练集“泄漏”,这将损害模型的性能。
创建一个表在砖功能存储时间序列特性
创建一个时间序列特征表,DataFrame或模式必须包含一个列指定时间戳的关键。
fs=FeatureStoreClient()# user_features_df DataFrame包含以下列:#——user_id# - ts#——purchases_30d#——is_free_trial_activefs。create_table(的名字=“ads_team.user_features”,primary_keys=(“user_id”,“t”),timestamp_keys=“t”,features_df=user_features_df,)
一个时间序列特性表必须有一个时间戳键,不能有任何分区列。时间戳键列必须的TimestampType或DateType也不能成为一个主键。
砖建议的时间序列特征表没有超过两个主键列,以确保性能和查找写道。
更新时间序列特征表
当写作特征的时间序列特性表、DataFrame必须提供值表的所有功能特性,与常规功能表。这个约束减少了稀疏的特征值在时间序列特性表中的时间戳。
fs=FeatureStoreClient()# daily_users_batch_df DataFrame包含以下列:#——user_id# - ts#——purchases_30d#——is_free_trial_activefs。write_table(“ads_team.user_features”,daily_users_batch_df,模式=“合并”)
流写入时间序列特征表支持。
创建一个训练集,一个时间序列特性表
执行时间点查找特性值时间序列特征表,您必须指定一个timestamp_lookup_key功能的FeatureLookup,这表明DataFrame列的名称包含时间戳来查找时间序列的特性。砖特性存储检索最新的特性值之前DataFrame的指定的时间戳timestamp_lookup_key列,其主键DataFrame的匹配值lookup_key列,或零如果没有这样的特性值的存在。
feature_lookups=(FeatureLookup(table_name=“ads_team.user_features”,feature_names=(“purchases_30d”,“is_free_trial_active”),lookup_key=“u_id”,timestamp_lookup_key=“ad_impression_ts”),FeatureLookup(table_name=“ads_team.ad_features”,feature_names=(“sports_relevance”,“food_relevance”),lookup_key=“ad_id”,)]# raw_clickstream DataFrame包含以下列:#——u_id#——ad_id#——ad_impression_tstraining_set=fs。create_training_set(raw_clickstream,feature_lookups=feature_lookups,exclude_columns=(“u_id”,“ad_id”,“ad_impression_ts”),标签=“did_click”,)training_df=training_set。load_df()
任何FeatureLookup在一个时间序列特性表必须及时查找,所以它必须指定一个timestamp_lookup_key在你的DataFrame列使用。时间点查找不跳过的行零特性值存储在时间序列特征表。
设置时间限制的历史特性值
从功能存储客户端v0.13.0,可以排除特性值和年长的训练集的时间戳。为此,使用参数lookback_window在FeatureLookup。
的数据类型lookback_window必须datetime.timedelta,默认值是没有一个(使用的所有特征值,不管年龄)。
例如,下面的代码不包括任何特性值超过7天:
从datetime进口timedeltafeature_lookups=(FeatureLookup(table_name=“ads_team.user_features”,feature_names=(“purchases_30d”,“is_free_trial_active”),lookup_key=“u_id”,timestamp_lookup_key=“ad_impression_ts”,lookback_window=timedelta(天=7))]
当你打电话create_training_set使用上面的FeatureLookup,它会自动执行时间点加入和不包括特征值大于7天。
lookback窗口应用在训练和批处理推理。在在线推理,总是使用最新的特性值,不管lookback窗口。