自适应查询执行
请注意
火花UI功能不可用这个版本砖在谷歌的云上。
自适应查询执行(AQE)是发生在查询执行查询重新优化。
运行时重新优化的动机是砖最新的准确的统计数据的洗牌和广播交换(称为AQE查询阶段)。因此,砖可以选择更好的物理策略,选择最优post-shuffle分区大小和数目,或做优化,用于需要提示,例如,斜加入处理。
时,这可能是非常有用的统计信息收集统计时不打开或失效。也有用在静态导出统计数据是不准确的地方,例如在一个复杂的查询,或者发生后的数据倾斜。
功能
在砖运行时7.3 LTS以上,AQE默认情况下是启用的。它有4个主要特点:
排序合并连接到广播哈希连接动态变化。
动态合并分区(结合小分区合理大小的分区)洗牌后交流。非常小的任务更糟糕的I / O吞吐量和更容易遭受来自调度开销和任务设置开销。结合小任务节约资源和提高集群的吞吐量。
动态处理斜排序合并连接和洗牌哈希连接的分裂和复制(如果需要)倾斜任务为大致均匀大小的任务。
动态检测和传播空的关系。
应用程序
AQE适用于所有查询:
的非
包含至少一个交易所(通常当有一个连接、聚集或窗口),子查询,或两者兼而有之。
并不是所有AQE-applied必然是优化查询。重新优化可能或不可能想出一个比一个静态编译不同的查询计划。确定查询的计划已经改变了AQE,看到下面的部分,查询计划。
查询计划
本节讨论如何以不同的方式查看查询计划。
在本节中:
火花UI
DataFrame.explain ()

有效性
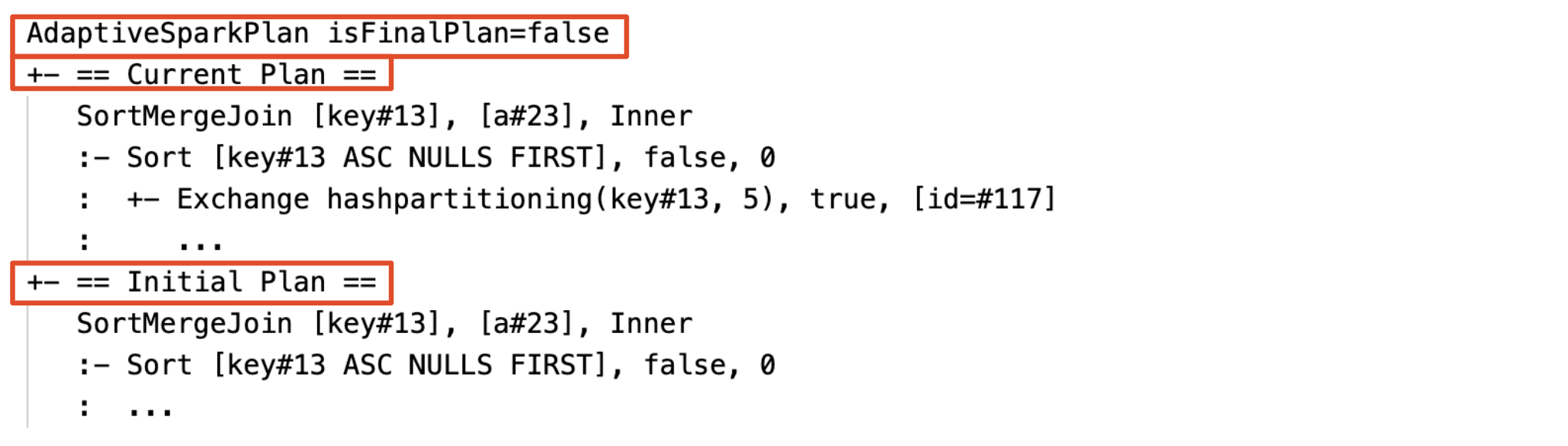
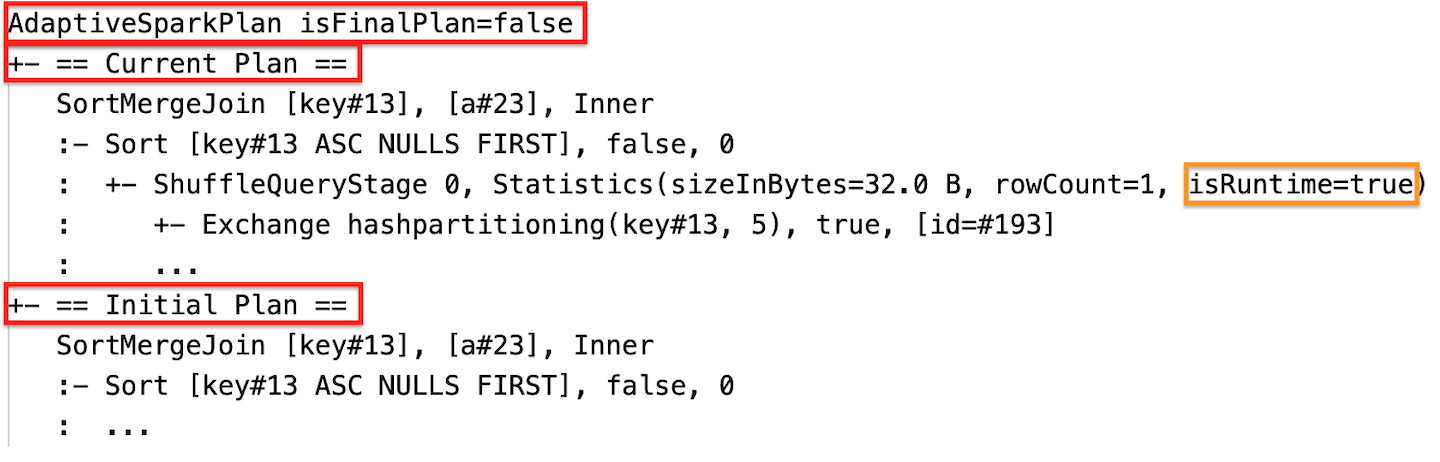
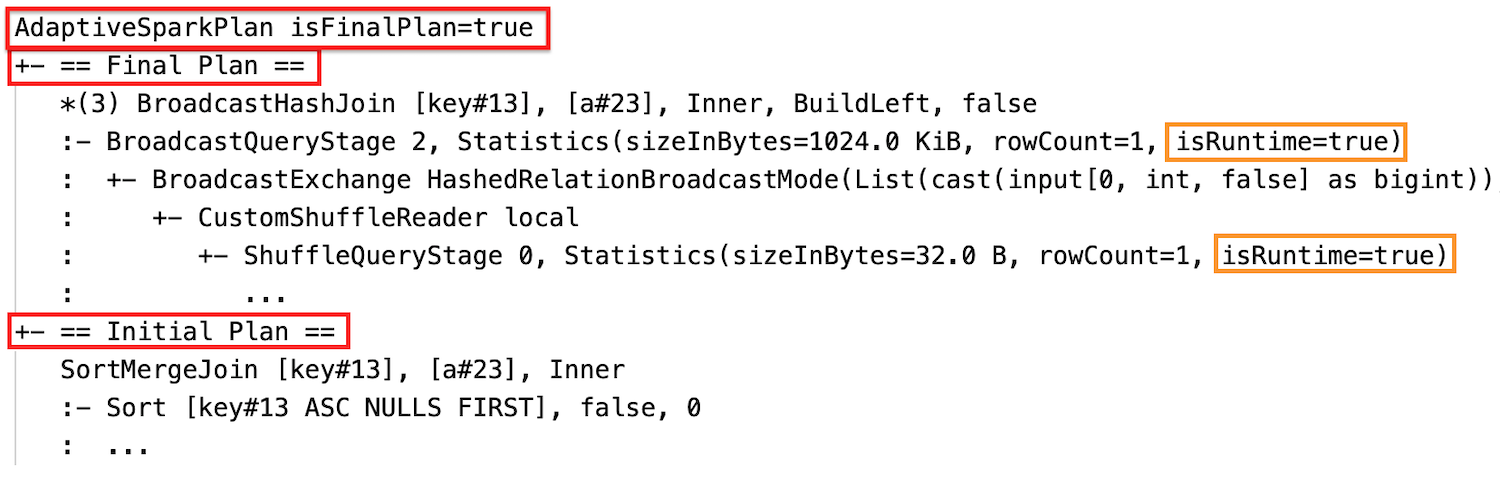
查询计划将会改变,如果一个或多个AQE优化生效。这些AQE优化的效果之间的差异,证明了电流和最终的计划和初始计划和具体计划在当前节点和最终的计划。
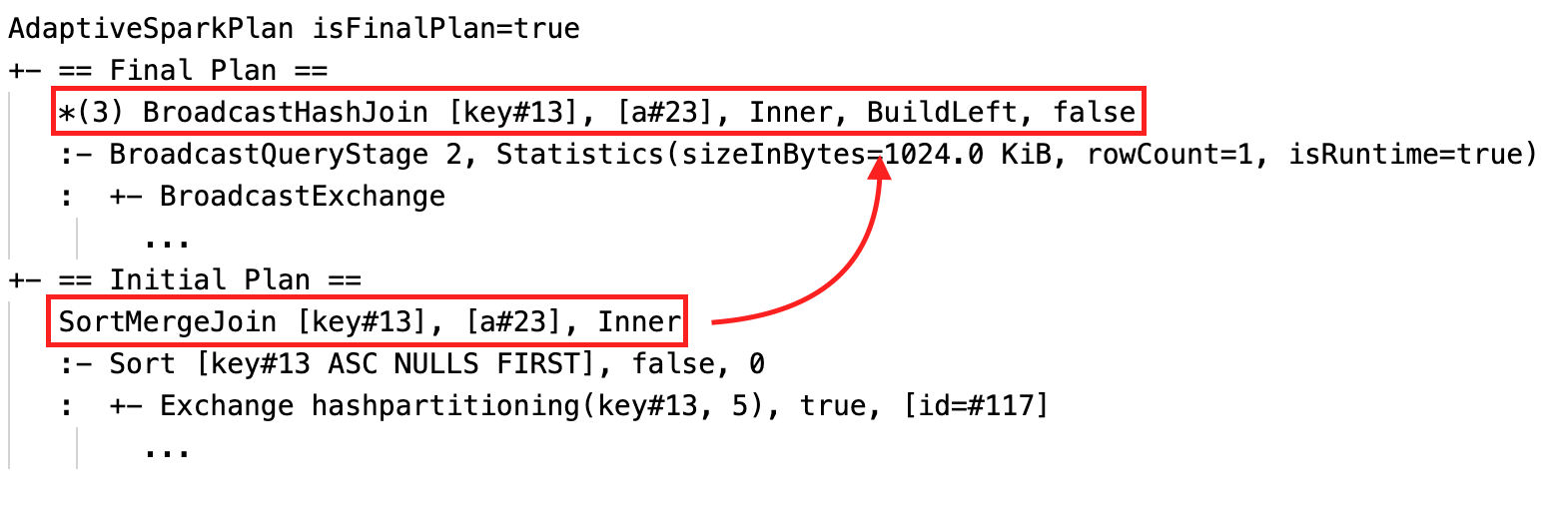
动态改变排序合并连接到广播哈希连接:不同的物理连接节点之间的电流/最终计划和最初的计划
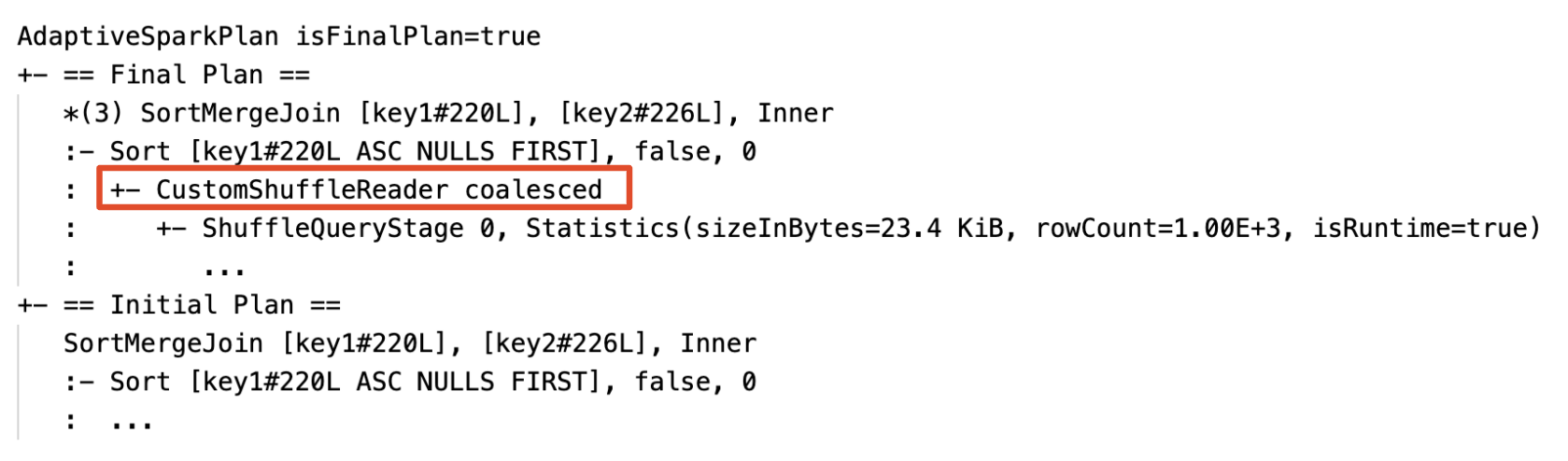
动态合并分区:节点
CustomShuffleReader有财产合并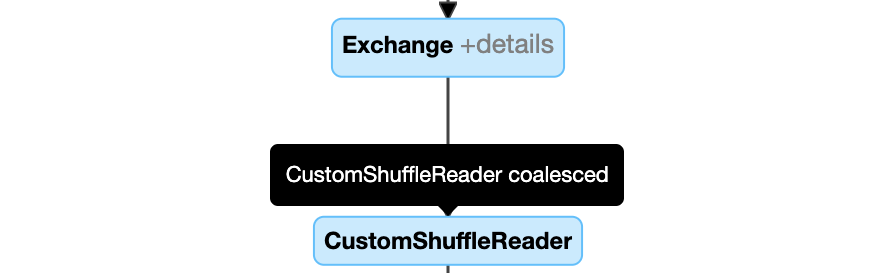
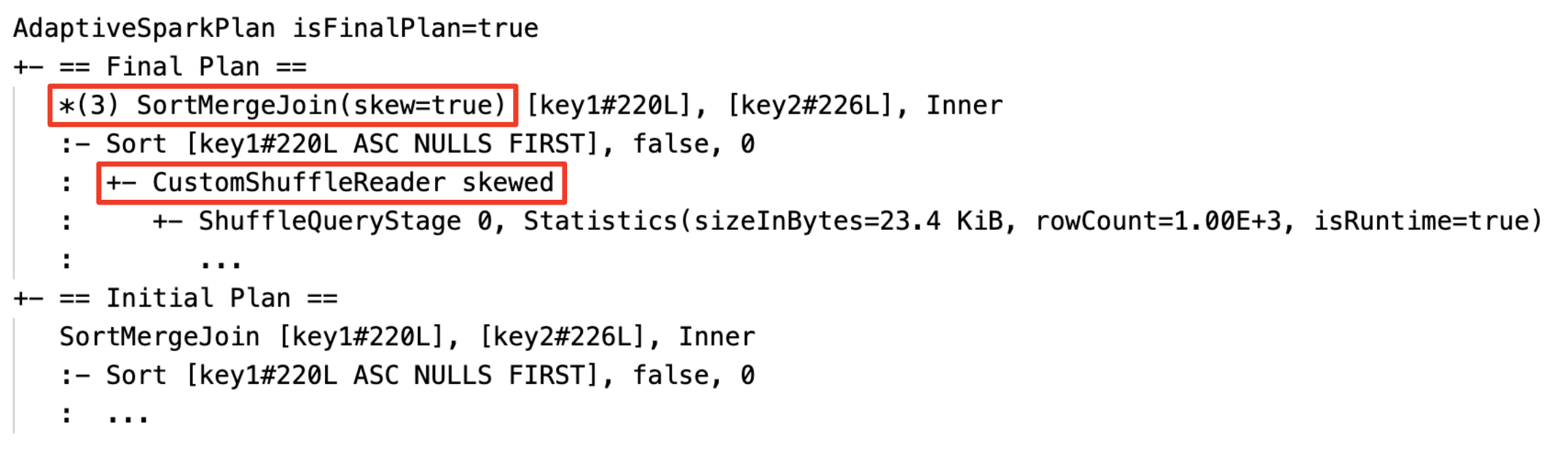
动态处理斜加入:节点
SortMergeJoin与字段isSkew是真实的。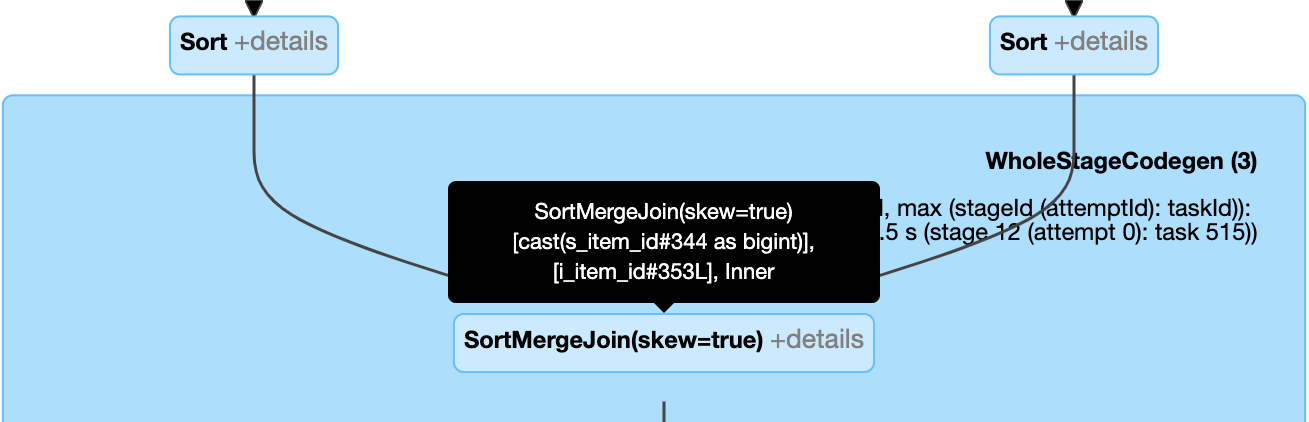
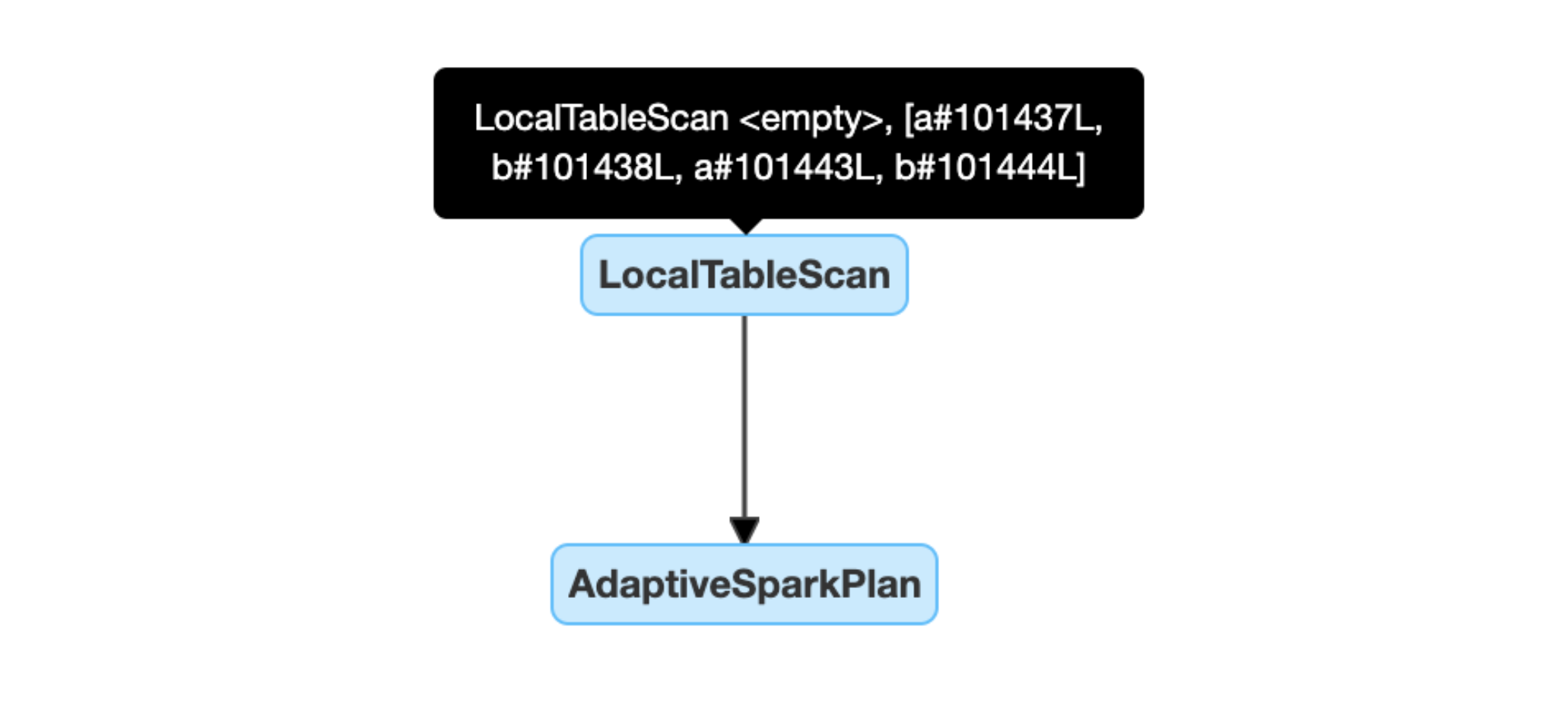
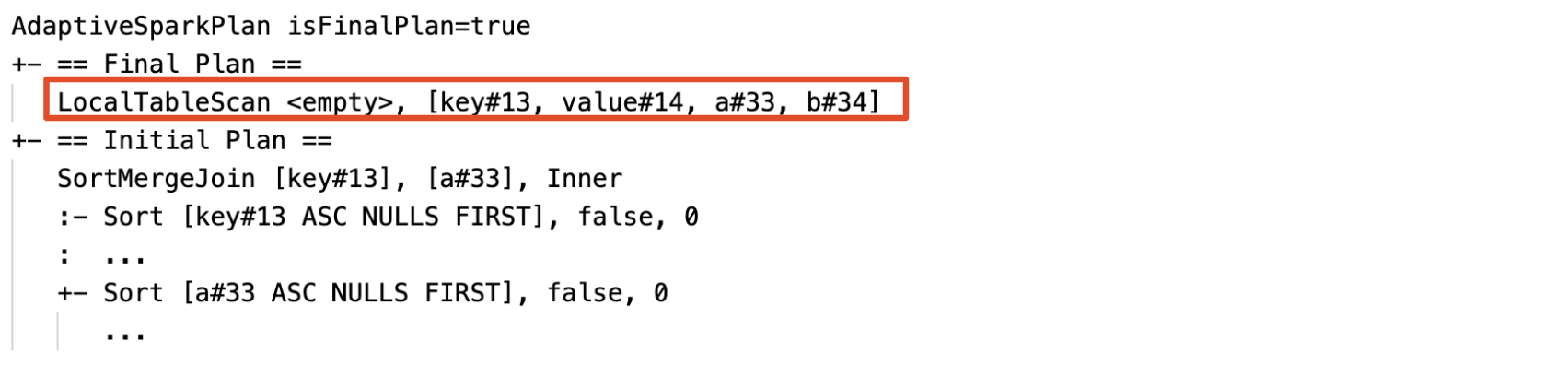
动态检测和传播空关系:部分(或全部)的计划取而代之的是节点LocalTableScan关系字段为空。







配置
启用和禁用自适应查询执行
财产 |
|---|
spark.databricks.optimizer.adaptive.enabled 类型: 是否启用或禁用自适应查询执行。 默认值: |
启用自动最优化洗牌
财产 |
|---|
spark.sql.shuffle.partitions 类型: 洗牌时的默认分区数量使用连接或聚合数据。设置的值 注意:对于结构化流,这之间的配置不能改变查询从相同的检查点位置重新启动。 默认值:200 |
动态改变排序合并连接到广播哈希连接
财产 |
|---|
spark.databricks.adaptive.autoBroadcastJoinThreshold 类型: 阈值触发切换到广播在运行时加入。 默认值: |
动态合并分区
财产 |
|---|
spark.sql.adaptive.coalescePartitions.enabled 类型: 是否启用或禁用分区合并。 默认值: |
spark.sql.adaptive.advisoryPartitionSizeInBytes 类型: 合并后的目标尺寸。合并分区大小将接近但不超过这一目标的大小。 默认值: |
spark.sql.adaptive.coalescePartitions.minPartitionSize 类型: 合并后分区的最小大小。合并分区大小不会比这个尺寸小。 默认值: |
spark.sql.adaptive.coalescePartitions.minPartitionNum 类型: 合并后的最小数量的分区。不推荐,因为设置显式重写 默认值:2 x。集群的核心 |
动态处理斜加入
财产 |
|---|
spark.sql.adaptive.skewJoin.enabled 类型: 是否启用或禁用斜加入处理。 默认值: |
spark.sql.adaptive.skewJoin.skewedPartitionFactor 类型: 一个因素,当乘以平均分区大小有助于确定一个分区是否倾斜。 默认值: |
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 类型: 一个阈值,有助于确定一个分区是否倾斜。 默认值: |
一个分区是当两个倾斜(分区大小>skewedPartitionFactor*中位数分区大小)和(分区大小>skewedPartitionThresholdInBytes)是真正的。
动态检测和空的传播关系
财产 |
|---|
spark.databricks.adaptive.emptyRelationPropagation.enabled 类型: 是否启用或禁用动态空关系传播。 默认值: |
常见问题(FAQ)
在本节中:
为什么不AQE广播一个连接表?
如果将广播的大小关系是否属于这个阈值但还没有广播:
检查连接类型。播放不支持特定的连接类型,例如,左边的关系
左外加入不能播放。它也可以包含很多空分区的关系,在这种情况下,能够迅速完成大多数任务的排序合并连接或与斜加入可以优化处理。AQE避免改变这样的排序合并连接广播散列连接的比例低于非空分区
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin。
我还是应该使用广播提示启用了AQE加入策略吗?
是的。静态计划广播加入通常比动态规划一个更好的性能由AQE AQE才会切换到广播加入执行洗牌后双方的加入(的时间)获得的实际大小的关系。所以使用广播提示仍然可以是一个不错的选择如果你知道你的查询。AQE会尊重查询提示一样的静态优化,但是仍然可以应用动态优化不受暗示的影响。
之间的区别是什么斜加入提示和AQE倾斜连接优化吗?我应该使用哪一个?
建议依靠AQE倾斜连接处理,而不是使用倾斜连接提示,因为AQE倾斜连接是完全自动的,一般执行比提示。
AQE调整我为什么不加入自动订购吗?
的动态加入重新排序不属于AQE砖LTS 7.3运行时。
为什么不AQE检测我的数据倾斜?
有两个尺寸必须满足条件AQE检测一个分区作为一个倾斜的分区:
分区大小大于
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(默认256 mb)中等大小的分区大小大于所有分区倍倾斜分区的因素
spark.sql.adaptive.skewJoin.skewedPartitionFactor(默认5)
此外,斜处理支持某些连接类型是有限的,例如,在左外加入,只有斜左侧可以优化。