sparklyr
请注意
此功能不可用此版本砖在谷歌的云上。
砖支持sparklyr在笔记本电脑,工作,和RStudio桌面。
需求
砖分配的最新稳定版本sparklyr每次运行时版本。您可以使用sparklyr砖R的笔记本或内部RStudio服务器托管在砖通过导入sparklyr的安装的版本。
在RStudio桌面,砖连接允许你从本地机器连接sparklyr砖集群和运行Apache火花代码。看到使用砖sparklyr和RStudio桌面连接。
连接sparklyr砖集群
建立sparklyr连接,您可以使用“砖”的连接方法spark_connect ()。没有额外的参数spark_connect ()电话是必须的,也不是spark_install ()需要,因为火花已经安装在砖集群。
#调用spark_connect()首先需要加载sparklyr包。图书馆(sparklyr)#创建sparklyr连接。sc< -spark_connect(方法=“砖”)
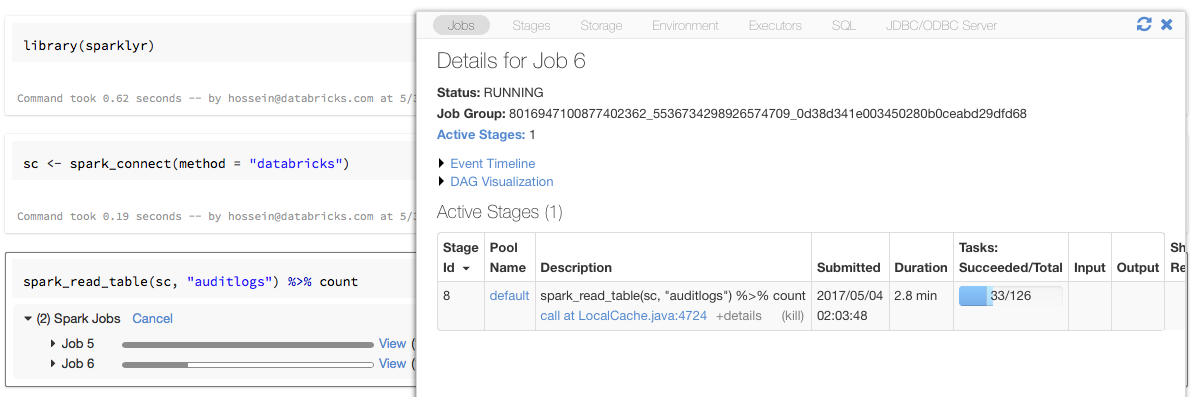
进度条和火花与sparklyr UI
如果你将sparklyr连接对象分配给一个变量命名sc在上面的示例中,您将看到火花进度条在笔记本上每个命令后,触发火花工作。另外,您可以点击链接旁边的进度条来查看火花UI与给定的火花相关工作。
使用sparklyr
安装sparklyr和建立连接后,所有其他sparklyr API作为平时的水平。看到例如笔记本电脑的一些例子。
sparklyr通常使用以及其他tidyverse包如dplyr。大部分的这些包是预装在砖,为了您的方便。您可以简单地将它们导入并开始使用API。
sparklyr SparkR一起使用
SparkR和sparklyr可以一起使用一个笔记本或工作。可以导入SparkR sparklyr和使用它的功能。在砖笔记本,SparkR连接是预先配置的。
的一些功能SparkR dplyr面具的功能:
>图书馆(SparkR)的后对象是戴面具的从”包:dplyr”:安排,之间的,合并,收集,包含,数,cume_dist,dense_rank,desc,截然不同的,解释,过滤器,第一个,group_by,相交,滞后,去年,铅,变异,n,n_distinct,ntile,percent_rank,重命名,row_number,sample_frac,选择,sql,总结,联盟
如果你进口SparkR dplyr进口后,您可以参考函数dplyr通过使用完全限定的名称,例如,dplyr:安排()。同样如果你进口dplyr SparkR后,函数SparkR由dplyr蒙面。
或者,您可以选择性地分离两个包中的一个,而你不需要它。
分离(“包:dplyr”)
另请参阅比较SparkR和sparklyr。
使用sparklyr spark-submit工作
运行脚本,可以使用在砖sparklyr spark-submit工作,与小代码修改。上面的一些指令不适用于砖上使用sparklyr spark-submit工作。特别是,您必须提供火花主URLspark_connect。例如:
图书馆(sparklyr)sc< -spark_connect(方法=“砖”,spark_home=“< spark-home-path >”)…
不支持的功能
砖不支持sparklyr方法等spark_web ()和spark_log ()需要一个本地浏览器。然而,由于火花UI是内置在砖上,您可以检查容易引发就业和日志。看到集群的司机和工人日志。
示例笔记本:Sparklyr演示
附加的例子,请参阅在R DataFrames和表工作。