使用SCIM通过IAM凭据传递访问S3
预览
此功能已在公共预览.
IAM凭据传递允许您使用登录Databricks时使用的身份自动从Databricks集群验证到S3桶。当您为您的集群启用IAM凭据传递时,您在该集群上运行的命令可以使用您的身份读取和写入S3中的数据。IAM凭据传递与使用安全方法访问S3桶相比有两个关键好处实例配置文件:
IAM证书透传允许多个具有不同数据访问策略的用户共享一个Databricks集群访问S3中的数据,同时保证数据的安全性。一个实例概要文件只能与一个实例相关联我的角色.这要求Databricks集群上的所有用户共享该角色和该角色的数据访问策略。
IAM证书传递将用户与某个身份关联起来。这反过来支持通过CloudTrail记录S3对象。所有S3访问都通过CloudTrail日志中的ARN直接绑定到用户。
设置一个元实例概要文件
为了使用IAM凭据传递,您必须首先设置至少一个元实例概要来承担您分配给用户的IAM角色。
一个我的角色是一个AWS身份,其策略决定该身份在AWS中可以做什么,不可以做什么。一个实例配置文件是IAM角色的容器,当实例启动时,您可以使用该容器将角色信息传递给EC2实例。实例概要文件允许您访问Databricks集群中的数据,而无需访问嵌入AWS密钥在笔记本电脑。
虽然实例概要文件使得在集群上配置角色非常简单,但只能与实例概要文件关联一个我的角色。这要求Databricks集群上的所有用户共享该角色和该角色的数据访问策略。但是,IAM角色可以用来承担其他IAM角色,或者自己直接访问数据。调用使用一个角色的凭据来承担不同的角色角色链接.
IAM凭据传递允许管理员将实例概要文件使用的IAM角色和用户访问数据时使用的角色分开。在Databricks中,我们称实例角色为IAM元角色和数据访问角色data IAM角色.类似于实例概要文件元实例概要是一个元IAM角色的容器。
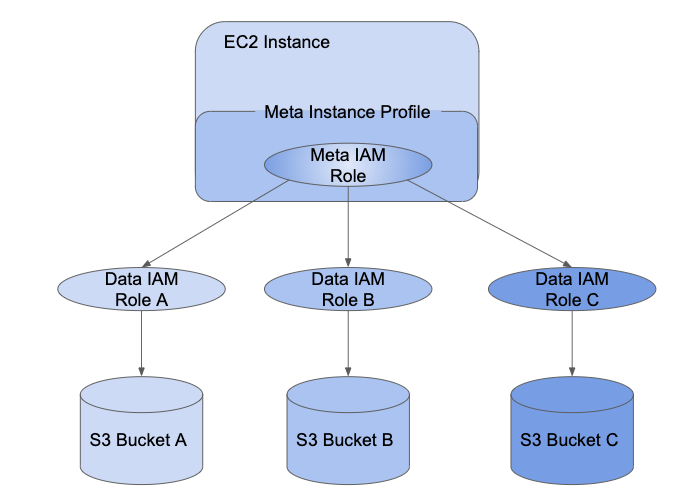
对象授予用户对数据IAM角色的访问权SCIM API.如果您正在将角色与您的标识提供程序映射,那么这些角色将同步到Databricks SCIM API。当您使用带有凭据传递和元实例概要文件的集群时,您只能假定您可以访问的数据IAM角色。这允许具有不同数据访问策略的多个用户共享一个Databricks集群,同时保证数据安全。
本节介绍如何设置启用IAM凭据透传所需的元实例配置文件。
步骤1:配置IAM鉴权透传角色
创建data IAM角色
使用现有的数据IAM角色或可选地遵循使用实例概要配置S3访问,创建可以访问S3桶的data IAM角色。
配置IAM元角色
将meta IAM角色配置为data IAM角色。
在AWS控制台中,转到我服务。
单击角色选项卡。
点击创建角色.
下选择受信任实体类型中,选择AWS服务。
单击EC2服务。
点击下一个权限.
点击创建政策.打开一个新窗口。
单击JSON选项卡。
复制以下策略并设置
<帐户id >到您的AWS帐户ID和< data-iam-role >到上一节中数据IAM角色的名称。{“版本”:“2012-10-17”,“声明”:[{“席德”:“AssumeDataRoles”,“效应”:“允许”,“行动”:“sts: AssumeRole”,“资源”:[“攻击:aws:我::<帐户id >:角色/ < data-iam-role >”]}]}
点击审查政策.
在“Name”字段中输入策略名称,单击创建政策.
返回到角色窗口并刷新它。
搜索策略名称并选中策略名称旁边的复选框。
点击下一个标签而且下一个评论.
在角色名称文件中,键入元IAM角色的名称。
点击创建角色.
在角色摘要中,复制实例配置ARN.
配置data IAM角色信任meta IAM角色
为了使元IAM角色能够承担数据IAM角色,您需要使元角色受数据角色信任。
在AWS控制台中,转到我服务。
单击角色选项卡。
找到在上一步中创建的数据角色并单击它以进入角色详细信息页面。
单击信任关系TAB,如果未设置,则添加以下语句:
{“版本”:“2012-10-17”,“声明”:[{“效应”:“允许”,“校长”:{“AWS”:“攻击:aws:我::<帐户id >:角色/ < meta-iam-role >”},“行动”:“sts: AssumeRole”}]}
步骤2:在Databricks中配置元实例配置文件
介绍在Databricks中配置元实例配置文件的操作步骤。
确定Databricks部署时使用的IAM角色
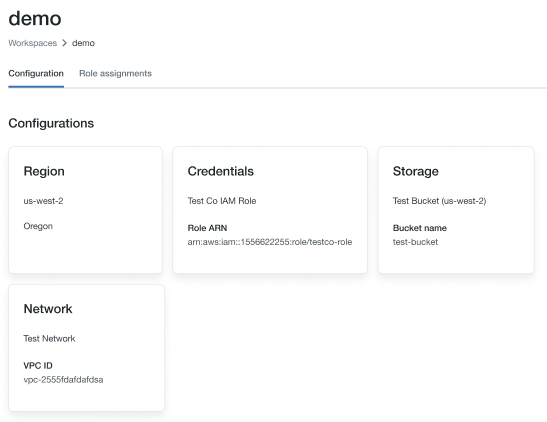
去账户控制台.
单击工作区图标。
单击工作区的名称。
请注意在凭证部分的ARN键的末尾的角色名称,在下面的图像中它是“testco-role”。

修改Databricks部署时使用的IAM角色中的策略
在AWS控制台中,转到我服务。
单击角色选项卡。
编辑上一节中提到的角色。
单击附加到角色的策略。
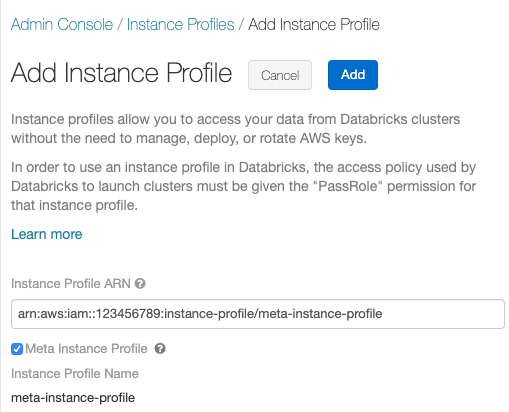
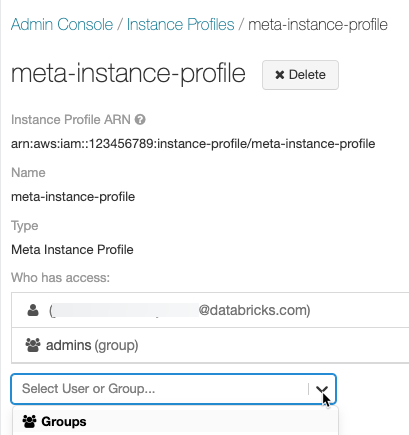
修改策略以允许Databricks内的Spark集群的EC2实例使用您在中创建的元实例配置文件配置IAM元角色.有关示例,请参见在EC2策略中添加S3 IAM角色.
点击审查政策而且保存更改.
步骤3:为Databricks用户添加IAM角色权限
维护用户到IAM角色的映射有两种方法:
在数据库中使用SCIM用户API或SCIM Groups API.
在你的身份提供商.这允许您集中数据访问,并通过SAML 2.0身份联合将这些授权直接传递给Databricks集群。
使用下面的图表来帮助您决定哪种映射方法更适合您的工作空间:
要求 |
SCIM |
身份提供商 |
|---|---|---|
单点登录到Databricks |
没有 |
是的 |
配置AWS标识提供程序 |
没有 |
是的 |
配置元实例概要 |
是的 |
是的 |
砖管理 |
是的 |
是的 |
AWS管理 |
是的 |
是的 |
标识提供程序管理 |
没有 |
是的 |
当您使用元实例配置文件启动一个集群时,该集群将通过您的身份,只承担您可以访问的数据IAM角色。管理员必须授予用户使用的数据IAM角色的权限SCIM API方法对角色设置权限。
请注意
如果您在IdP中映射角色,那么这些角色将覆盖在SCIM中映射的任何角色,您不应该将用户直接映射到角色。看到步骤6:可选地配置Databricks将角色映射从SAML同步到SCIM.
还可以使用将实例概要文件附加到用户或组Databricks Terraform提供商而且databricks_user_role或databricks_group_instance_profile.
启动IAM证书直通集群
启动具有凭据传递的集群的过程因集群模式而异。
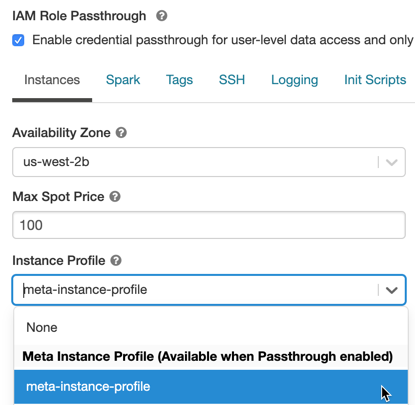
为高并发性集群启用凭据传递
高并发集群可以被多个用户共享。它们只支持带有直通功能的Python和SQL。
选择Databricks Runtime Version 6.1或以上版本。
下高级选项中,选择为用户级数据访问启用凭据传递,并且只允许Python和SQL命令.

单击实例选项卡。在实例配置文件下拉菜单,选择在其中创建的元实例概要文件将元实例配置文件添加到Databricks.

在Standard集群中开启IAM鉴权直通功能
支持具有凭据传递的标准集群,但仅限于单个用户。标准集群支持Python、SQL、Scala和r。在Databricks Runtime 10.1及以上版本上,也支持sparklyr。
创建集群时必须分配用户,但可以由具有可以管理权限随时替换原有用户。
重要的
分配给集群的用户必须至少拥有可以附着于集群的权限,以便在集群上运行命令。管理员和集群创建者拥有可以管理权限,但不能在集群上运行命令,除非他们是指定的集群用户。
选择Databricks Runtime Version 6.1或以上版本。
下高级选项中,选择为用户级数据访问启用凭据传递.
中选择用户名单用户接入下拉。
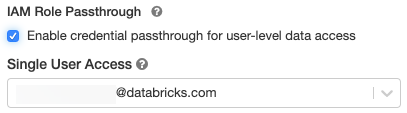
单击实例选项卡。在实例配置文件下拉菜单,选择在其中创建的元实例概要文件将元实例配置文件添加到Databricks.

使用IAM凭据直通访问S3
您可以使用凭据传递访问S3,方法是假设一个角色并直接访问S3,或者使用该角色挂载S3桶并通过挂载访问数据。
使用凭据传递读写S3数据
向S3读写数据:
dbutils.凭证.assumeRole(“攻击:aws:我::xxxxxxxx:角色/ < data-iam-role >”)火花.读.格式(“csv”).负载(“s3a: / / prod-foobar / sampledata.csv”)火花.范围(1000).写.模式(“覆盖”).保存(“s3a: / / prod-foobar / sampledata.parquet”)
dbutils.credentials.assumeRole(“攻击:aws:我::xxxxxxxx:角色/ < data-iam-role >”)# SparkR图书馆(SparkR)sparkR.session()read.df(“s3a: / / prod-foobar / sampledata.csv”,源=“csv”)write.df(作为。DataFrame(data.frame(1:1000)),路径=“s3a: / / prod-foobar / sampledata.parquet”,源=“铺”,模式=“覆盖”)# sparklyr图书馆(sparklyr)sc<-spark_connect(方法=“砖”)sc% > %spark_read_csv(“s3a: / / prod-foobar / sampledata.csv”)sc% > %sdf_len(1000)% > %spark_write_parquet(“s3a: / / prod-foobar / sampledata.parquet”,模式=“覆盖”)
使用dbutils角色:
dbutils.凭证.assumeRole(“攻击:aws:我::xxxxxxxx:角色/ < data-iam-role >”)dbutils.fs.ls(“s3a: / / bucketA /”)
dbutils.credentials.assumeRole(“攻击:aws:我::xxxxxxxx:角色/ < data-iam-role >”)dbutils.fs.ls(“s3a: / / bucketA /”)
为其他dbutils.credentials方法,请参阅凭证实用程序(dbutils.credentials).
使用IAM凭据传递将S3桶挂载到DBFS
对于更高级的场景(不同的桶或前缀需要不同的角色),使用Databricks桶挂载来指定访问特定桶路径时要使用的角色会更方便。
当您使用启用了IAM凭据传递的集群挂载数据时,对挂载点的任何读或写都将使用您的凭据对挂载点进行身份验证。这个挂载点对其他用户是可见的,但是只有那些具备读写权限的用户:
是否可以通过IAM数据角色访问底层S3存储帐户
使用集群是否启用了IAM凭据传递
dbutils.fs.山(“s3a: / / < s3 bucket > /数据/机密”,“/ mnt /机密数据”,extra_configs={“fs.s3a.credentialsType”:“自定义”,“fs.s3a.credentialsType.customClass”:“com.databricks.backend.daemon.driver.aws.AwsCredentialContextTokenProvider”,“fs.s3a.stsAssumeRole.arn”:“攻击:aws:我::xxxxxxxx:角色/ < confidential-data-role >”})
通过IAM证书透传访问作业中的S3数据
若要在作业中使用凭据传递访问S3数据,请根据配置集群启动IAM证书直通集群当您选择新的或现有的集群时。

集群将只承担作业所有者已被授予权限的角色,因此只能访问该角色有权限访问的S3数据。
使用IAM凭证传递从JDBC或ODBC客户端访问S3数据
若要通过JDBC或ODBC客户端使用IAM凭据透传访问S3数据,请根据启动IAM证书直通集群并在客户端中连接到这个集群。集群将只承担连接到它的用户已被授予访问权限的角色,因此只能访问用户有权限访问的S3数据。
要在SQL查询中指定角色,请执行以下操作:
集火花.砖.凭证.假定.角色=在攻击:aws:我::XXXX:角色/<数据-我-角色>;—访问有权限访问的桶 选择数(*)从csv.`s3://我的-桶/测验.csv`;
已知的限制
IAM证书传递不支持以下特性:
% fs(使用等价物dbutils.fs命令相反)。在SparkContext (
sc)和SparkSession (火花)对象:弃用的方法。
方法包括
addFile ()而且addJar ()允许非管理员用户调用Scala代码。访问S3以外的文件系统的任何方法。
旧的Hadoop api (
hadoopFile ()而且hadoopRDD ()).流api,因为在流仍在运行时,传递的凭据将过期。
DBFS坐骑(
/ dbfs)只适用于Databricks Runtime 7.3 LTS及以上版本。通过此路径不支持配置了凭据传递的挂载点。需要集群实例概要文件权限才能下载的集群范围的库。只支持具有DBFS路径的库。