表流读写
三角洲湖与Spark结构化流通过readStream而且writeStream.Delta Lake克服了许多与流系统和文件相关的限制,包括:
合并低延迟摄取产生的小文件
使用多个流(或并发批处理作业)维护“恰好一次”的处理
当使用文件作为流的源时,有效地发现哪些文件是新的
表作为源
当您将Delta表加载为流源并在流查询中使用它时,查询将处理表中出现的所有数据以及流启动后到达的任何新数据。
您可以将路径和表作为流加载。
火花.readStream.格式(“δ”).负载(“/ tmp /δ/事件”)进口io.δ.值得一提的._火花.readStream.δ(“/ tmp /δ/事件”)
或
进口io.δ.值得一提的._火花.readStream.格式(“δ”).表格(“事件”)
限制输入速率
以下选项可用于控制微批次:
maxFilesPerTrigger:每个微批处理中要考虑多少个新文件。缺省值是1000。maxBytesPerTrigger:每个微批处理的数据量。该选项设置了一个“软最大值”,这意味着批处理大约这个数据量,并且可能处理超过限制的数据量,以便在最小输入单元大于此限制的情况下使流查询向前移动。如果你使用触发器。一次对于流,此选项将被忽略。默认情况下没有设置。
如果你使用maxBytesPerTrigger连同maxFilesPerTrigger时,微批处理数据直到maxFilesPerTrigger或maxBytesPerTrigger达到极限。
请注意
在源表事务被清理的情况下logRetentionDuration配置并且流处理滞后,Delta Lake处理与源表的最新可用事务历史相对应的数据,但不会使流失败。这可能导致数据被删除。
流Delta Lake变更数据捕获(CDC)馈送
三角洲湖更改数据馈送记录对Delta表的更改,包括更新和删除。启用后,您可以从更改数据提要进行流处理,并将逻辑写入下游表中处理插入、更新和删除。虽然更改数据提要数据输出与它所描述的Delta表略有不同,但这提供了一种解决方案,可以将增量更改传播到数据库中的下游表大奖章架构.
忽略更新和删除
结构化流不处理非追加的输入,如果对用作源的表进行了任何修改,则抛出异常。有两种主要策略用于处理不能自动向下游传播的更改:
您可以删除输出和检查点,并从头重新启动流。
您可以设置以下两个选项之一:
ignoreDeletes:忽略在分区边界删除数据的事务。ignoreChanges:重新处理更新,如果文件必须重写源表中由于数据更改操作,如更新,合并成,删除(在分区内),或覆盖.未更改的行仍然可能被发出,因此您的下游消费者应该能够处理重复的行。删除不会向下传播。ignoreChanges包容ignoreDeletes.因此,如果你使用ignoreChanges,您的流将不会被删除或更新源表中断。
例子
例如,假设您有一个表user_events与日期,user_email,行动所划分的列日期.你流出user_events表,由于GDPR,您需要删除其中的数据。
当您在分区边界处删除时(即在哪里在分区列上),这些文件已经按值分割,因此删除只是将这些文件从元数据中删除。因此,如果你只是想从某些分区删除数据,你可以使用:
火花.readStream.格式(“δ”).选项(“ignoreDeletes”,“真正的”).负载(“/ tmp /δ/ user_events”)
但是,如果要删除的数据基于user_email,则需要使用:
火花.readStream.格式(“δ”).选项(“ignoreChanges”,“真正的”).负载(“/ tmp /δ/ user_events”)
如果你更新了user_email与更新语句中,包含user_email问题是重写。当你使用ignoreChanges,新记录与同一文件中所有其他未更改的记录一起向下传播。您的逻辑应该能够处理这些传入的重复记录。
指定初始位置
您可以使用以下选项指定Delta Lake流源的起点,而无需处理整个表。
startingVersion:从Delta Lake版本开始。从这个版本(包括)开始的所有表更改都将由流源读取。提交版本可以从版本的列描述历史命令的输出。在Databricks Runtime 7.4及以上版本中,若要仅返回最新更改,请指定
最新的.startingTimestamp:开始的时间戳。在时间戳或之后提交的所有表更改(包括)将被流源读取。之一:时间戳字符串。例如,
“2019 - 01 - 01 t00:00:00.000z”.日期字符串。例如,
“2019-01-01”.
你不能同时设置两个选项;你只能使用其中一个。只有在开始新的流查询时才生效。如果流查询已经启动,并且进度已记录在其检查点中,则忽略这些选项。
重要的
虽然可以从指定的版本或时间戳启动流源,但流源的模式始终是Delta表的最新模式。必须确保在指定的版本或时间戳之后,Delta表没有不兼容的模式更改。否则,流源在读取使用不正确模式的数据时可能返回不正确的结果。
处理初始快照,不删除数据
请注意
该特性在Databricks Runtime 11.1及以上版本上可用。此功能已在公共预览.
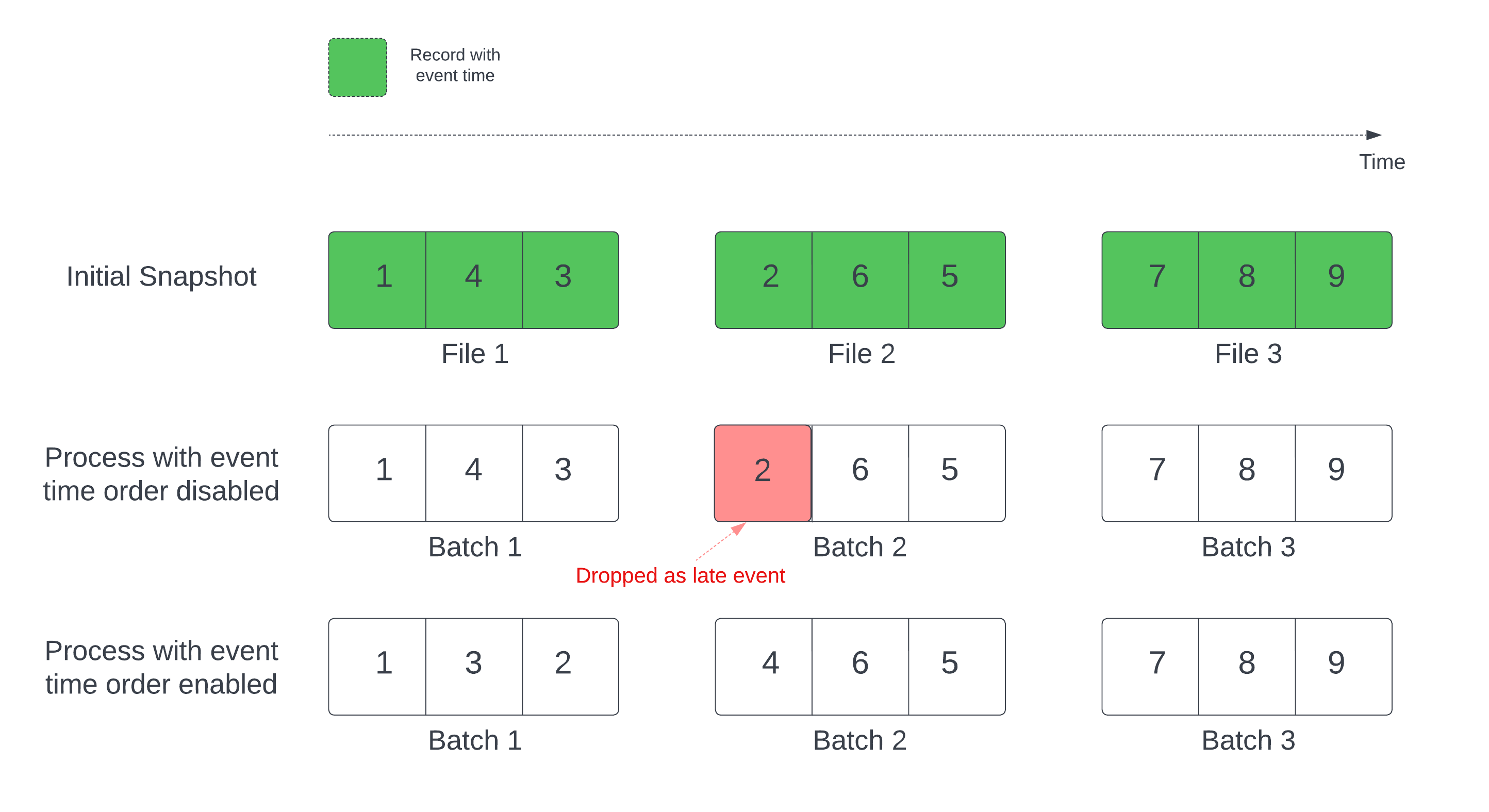
当使用Delta表作为流源时,查询首先处理表中出现的所有数据。这个版本的Delta表称为初始快照。默认情况下,Delta表的数据文件根据最后修改的文件进行处理。但是,最后一次修改时间并不一定代表记录事件的时间顺序。
在具有已定义水印的有状态流查询中,按修改时间处理文件可能导致记录以错误的顺序处理。这可能导致记录通过水印作为后期事件删除。
您可以通过启用以下选项来避免数据丢失问题:
withEventTimeOrder:初始快照是否应该按照事件时间顺序进行处理。
启用事件时间顺序后,快照初始数据的事件时间范围被划分为多个时间桶。每个微批通过过滤时间范围内的数据来处理一个桶。maxFilesPerTrigger和maxBytesPerTrigger配置选项仍然适用于控制微批处理大小,但由于处理的性质,只能以近似的方式进行控制。
下图展示了这个过程:
关于此特性的注意事项:
只有在按默认顺序处理有状态流查询的初始Delta快照时,才会发生数据丢失问题。
你无法改变
withEventTimeOrder一旦流查询开始,而初始快照仍在处理中。重新启动withEventTimeOrder更改后,您需要删除检查点。如果您正在运行启用theventtimeorder的流查询,在初始快照处理完成之前,您不能将其降级为不支持此功能的DBR版本。如果需要降级,可以等待初始快照完成,或者删除检查点并重新启动查询。
以下特殊场景不支持该特性:
事件时间列是一个生成的列,并且在增量源和水印之间存在非投影转换。
在流查询中,有一个水印具有多个增量源。
启用事件时间顺序后,Delta初始快照处理的性能可能会变慢。
每个微批处理扫描初始快照,以过滤相应事件时间范围内的数据。为了加快筛选操作,建议使用Delta源列作为事件时间,以便应用数据跳过(检查数据跳跃与z顺序索引三角洲湖当它适用的时候)。此外,沿着事件时间列进行表分区可以进一步加快处理速度。您可以检查Spark UI,以查看为特定的微批处理扫描了多少增量文件。
表作为接收器
还可以使用结构化流将数据写入Delta表。事务日志使Delta Lake能够保证只进行一次处理,即使有其他流或批查询同时对该表运行。
请注意
三角洲湖真空函数删除不受Delta Lake管理的所有文件,但跳过以_.可以使用目录结构(如。)将检查点与Delta表的其他数据和元数据一起安全地存储< table_name > / _checkpoints.
指标
请注意
在Databricks Runtime 8.1及以上版本中可用。
类型中尚未处理的字节数和文件数流查询流程随着numBytesOutstanding而且numFilesOutstanding指标。其他指标包括:
numNewListedFiles:为计算此批积压而列出的Delta Lake文件的数量。backlogEndOffset:用于计算待办事项的表格版本。
如果在笔记本中运行流,则可以在原始数据页中的流查询进度仪表板:
{“源”:[{“描述”:“DeltaSource(文件/道路/ /源):“,“指标”:{“numBytesOutstanding”:“3456”,“numFilesOutstanding”:“8”},}]}
Append模式
默认情况下,流以追加模式运行,即向表中添加新记录。
你可以使用path方法:
(事件.writeStream.格式(“δ”).outputMode(“添加”).选项(“checkpointLocation”,“/ tmp /δ/ _checkpoints /”).开始(“/δ/事件”))
事件.writeStream.格式(“δ”).outputMode(“添加”).选项(“checkpointLocation”,“/ tmp /δ/事件/ _checkpoints /”).开始(“/ tmp /δ/事件”)
或者是toTable在Spark 3.1及以上版本(Databricks Runtime 8.3及以上版本)中使用。(在3.1之前的Spark版本(Databricks Runtime 8.2及以下)中,请使用表格方法。)
(事件.writeStream.格式(“δ”).outputMode(“添加”).选项(“checkpointLocation”,“/ tmp /δ/事件/ _checkpoints /”).toTable(“事件”))
事件.writeStream.outputMode(“添加”).选项(“checkpointLocation”,“/ tmp /δ/事件/ _checkpoints /”).toTable(“事件”)
完整的模式
您还可以使用结构化流来用每个批处理替换整个表。一个例子是使用聚合计算摘要:
(火花.readStream.格式(“δ”).负载(“/ tmp /δ/事件”).groupBy(“customerId”).数().writeStream.格式(“δ”).outputMode(“完整的”).选项(“checkpointLocation”,“/ tmp /δ/ eventsByCustomer / _checkpoints /”).开始(“/ tmp /δ/ eventsByCustomer”))
火花.readStream.格式(“δ”).负载(“/ tmp /δ/事件”).groupBy(“customerId”).数().writeStream.格式(“δ”).outputMode(“完整的”).选项(“checkpointLocation”,“/ tmp /δ/ eventsByCustomer / _checkpoints /”).开始(“/ tmp /δ/ eventsByCustomer”)
上面的示例持续更新一个表,该表包含按客户划分的事件总数。
对于延迟要求较低的应用程序,可以使用一次性触发器节省计算资源。使用这些工具更新给定计划上的摘要聚合表,只处理自上次更新以来到达的新数据。
幂等表写入foreachBatch
请注意
在Databricks Runtime 8.4及以上版本中可用。
命令foreachBatch允许您指定在流查询中的任意转换后对每个微批的输出执行的函数。这允许实现一个foreachBatch函数,该函数可以将微批输出写入一个或多个目标Delta表目的地。然而,foreachBatch不会使这些写操作为幂等的,因为这些写尝试缺乏批处理是否正在重新执行的信息。例如,重新运行失败的批处理可能导致重复的数据写入。
为了解决这个问题,Delta表支持以下功能DataFrameWriter使写函数幂等的选项:
txnAppId:可以传递给每个对象的唯一字符串DataFrame写。例如,您可以使用StreamingQuery ID作为txnAppId.txnVersion:作为事务版本的单调递增的数字。
Delta表使用的组合txnAppId而且txnVersion识别重复写并忽略它们。
如果批写操作因失败而中断,则使用相同的应用程序和批处理ID重新运行批处理,这将帮助运行时正确识别重复的写操作并忽略它们。申请编号(txnAppId)可以是任何用户生成的唯一字符串,并且不必与流ID相关。
警告
如果删除流检查点并使用新的检查点重新启动查询,则必须提供不同的检查点appId;否则,从重新启动的查询写入将被忽略,因为它将包含相同的内容txnAppId批处理ID从0开始。
相同的DataFrameWriter选项可用于在非流作业中实现幂等写入。有关详细信息,启用跨作业的幂等写入.
例子
app_id=...#作为应用程序ID的唯一字符串。defwriteToDeltaLakeTableIdempotent(batch_df,batch_id):batch_df.写.格式(...).选项(“txnVersion”,batch_id).选项(“txnAppId”,app_id).保存(...)#位置1batch_df.写.格式(...).选项(“txnVersion”,batch_id).选项(“txnAppId”,app_id).保存(...)#位置2
瓦尔appId=...//作为应用程序ID的唯一字符串。streamingDF.writeStream.foreachBatch{(batchDF:DataFrame,batchId:长)= >batchDF.写.格式(…)。选项(“txnVersion”,batchId).选项(“txnAppId”,appId).保存(…)// location 1batchDF.写.格式(…)。选项(“txnVersion”,batchId).选项(“txnAppId”,appId).保存(…)// location 2}
执行流静态连接
您可以依赖Delta Lake的事务保证和版本控制协议来执行stream-static连接。流静态连接使用无状态连接将Delta表(静态数据)的最新有效版本连接到数据流。
当Databricks在流-静态连接中处理微批数据时,来自静态Delta表的最新有效数据版本将与当前微批中的记录进行连接。因为连接是无状态的,所以您不需要配置水印,并且可以以较低的延迟处理结果。连接中使用的静态Delta表中的数据应该是缓慢变化的。
streamingDF=火花.readStream.表格(“订单”)staticDF=火花.读.表格(“顾客”)查询=(streamingDF.加入(staticDF,streamingDF.customer_id= =staticDF.id,“内心”).writeStream.选项(“checkpointLocation”,checkpoint_path).表格(“orders_with_customer_info”))
Upsert从流查询使用foreachBatch
你可以使用的组合合并而且foreachBatch将流查询中的复杂upserts写入Delta表。看到使用foreachBatch使用结构化流写入任意数据接收器.
这个模式有很多应用,包括:
在更新模式下写入流聚合:这比完全模式更有效率。
将数据库更改流写入Delta表:合并查询,用于写入更改数据可用于
foreachBatch来连续地对Delta表应用更改流。使用重复数据删除将数据流写入Delta表:用于重复数据删除的仅插入合并查询可用于
foreachBatch使用自动重复数据删除功能,连续向Delta表写入数据(带重复)。
请注意
确保你的
合并声明内foreachBatch是幂等的,因为重新启动流查询可以对同一批数据应用多次操作。当
合并用于foreachBatch,流查询的输入数据速率(通过StreamingQueryProgress在笔记本速率图中可见)可以报告为数据在源处生成的实际速率的倍数。这是因为合并多次读取输入数据,导致输入指标相乘。如果这是一个瓶颈,您可以在此之前缓存批DataFrame合并然后将其解缓存合并.
下面的示例演示如何在foreachBatch要完成这项任务:
//使用merge将microBatchOutputDF插入Delta表的函数defupsertToDelta(microBatchOutputDF:DataFrame,batchId:长){//设置dataframe为view namemicroBatchOutputDF.createOrReplaceTempView(“更新”)//使用视图名来应用MERGE//注意:你必须使用SparkSession来定义' updates '数据框架microBatchOutputDF.sparkSession.sql(”“”合并成聚合体t使用更新ON s.key = t.key当匹配时,更新集合*如果不匹配,则插入*”“”)}//将流聚合查询的输出写入Delta表streamingAggregatesDF.writeStream.格式(“δ”).foreachBatch(upsertToDelta_).outputMode(“更新”).开始()
使用merge将microBatchOutputDF插入Delta表defupsertToDelta(microBatchOutputDF,batchId):#设置数据帧为视图名microBatchOutputDF.createOrReplaceTempView(“更新”)使用视图名称应用MERGE#注意:你必须使用SparkSession来定义“updates”数据框架在Databricks Runtime 10.5及以下版本中,您必须使用以下命令:# microBatchOutputDF._jdf.sparkSession () . sql(“””microBatchOutputDF.sparkSession.sql(”“”合并成聚合体t使用更新ON s.key = t.key当匹配时,更新集合*如果不匹配,则插入*”“”)#将流聚合查询的输出写入Delta表(streamingAggregatesDF.writeStream.格式(“δ”).foreachBatch(upsertToDelta).outputMode(“更新”).开始())
你也可以选择使用Delta Lake api来执行流upserts,如下例所示:
进口io.δ.表.*瓦尔deltaTable=DeltaTable.forPath(火花,“/数据/聚合物”)//使用merge将microBatchOutputDF插入Delta表的函数defupsertToDelta(microBatchOutputDF:DataFrame,batchId:长){deltaTable.作为(“t”).合并(microBatchOutputDF.作为(“s”),"s.key = t.key").whenMatched().updateAll().whenNotMatched().insertAll().执行()}//将流聚合查询的输出写入Delta表streamingAggregatesDF.writeStream.格式(“δ”).foreachBatch(upsertToDelta_).outputMode(“更新”).开始()
从delta.tables进口*deltaTable=DeltaTable.forPath(火花,“/数据/聚合物”)使用merge将microBatchOutputDF插入Delta表defupsertToDelta(microBatchOutputDF,batchId):(deltaTable.别名(“t”).合并(microBatchOutputDF.别名(“s”),"s.key = t.key").whenMatchedUpdateAll().whenNotMatchedInsertAll().执行())#将流聚合查询的输出写入Delta表(streamingAggregatesDF.writeStream.格式(“δ”).foreachBatch(upsertToDelta).outputMode(“更新”).开始())