创建您的第一个工作流与砖的工作
这篇文章演示了一个砖工作协调任务阅读和处理样本数据集。在这个快速入门,你:
创建一个新的笔记本和添加代码来检索一个示例数据集包含受欢迎的婴儿名字。
保存DBFS的样本数据集。
创建一个新的笔记本,从DBFS添加代码来读取数据,过滤,并显示结果。
创建一个新的工作,使用笔记本电脑配置两个任务。
运行工作,查看结果。
创建一个笔记本
检索并保存数据
创建一个笔记本检索示例数据并将其保存DBFS:
去你的砖着陆页面并点击
 新在侧边栏并选择笔记本。砖创建并打开一个新的空白笔记本在你的默认文件夹。默认语言是你最近使用的语言,和笔记本自动附加到你最近使用的计算资源。
新在侧边栏并选择笔记本。砖创建并打开一个新的空白笔记本在你的默认文件夹。默认语言是你最近使用的语言,和笔记本自动附加到你最近使用的计算资源。如果有必要,更改默认语言Python。
复制下面的Python代码粘贴到第一个单元格的笔记本。
进口请求响应=请求。得到(“http://health.data.ny.gov../api/views/myeu-hzra/rows.csv”)csvfile=响应。内容。解码(“utf - 8”)dbutils。fs。把(“dbfs: / FileStore / babynames.csv”,csvfile,真正的)
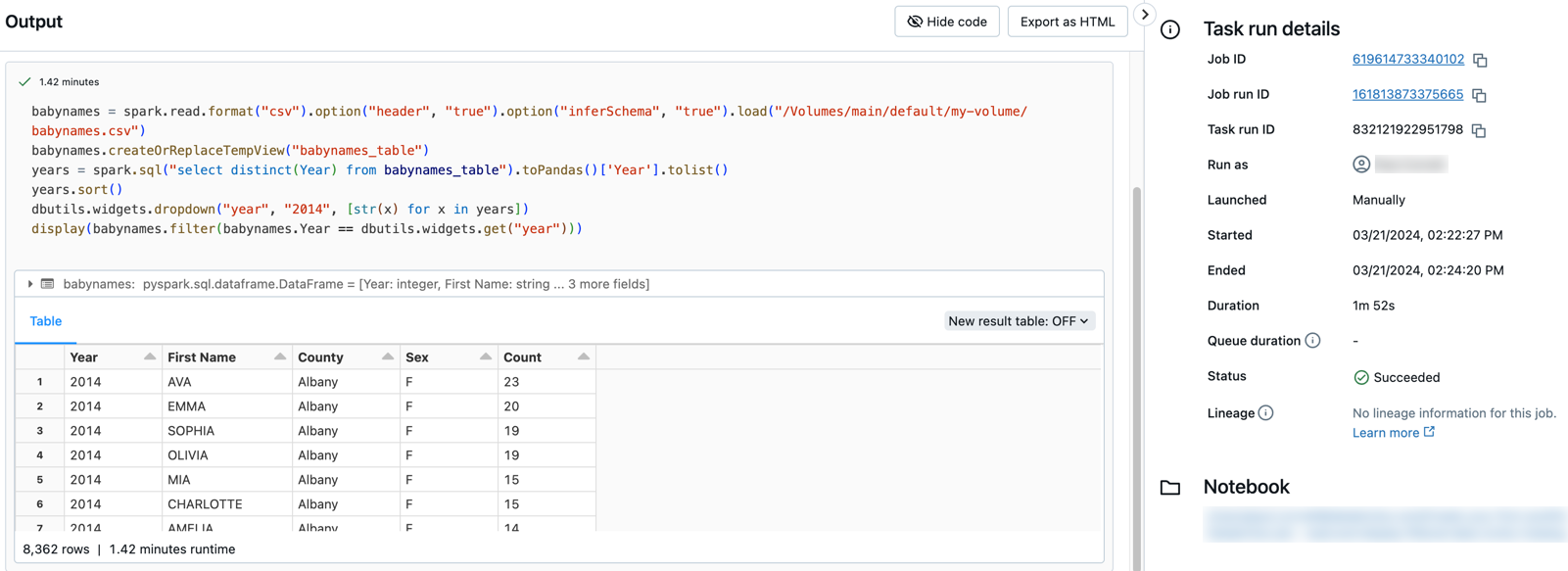
读取和显示过滤后的数据
创建一个笔记本读和现在的数据过滤:
去你的砖着陆页面并点击
新在侧边栏并选择笔记本。砖创建并打开一个新的空白笔记本在你的默认文件夹。默认语言是你最近使用的语言,和笔记本自动附加到你最近使用的计算资源。如果有必要,更改默认语言Python。
复制下面的Python代码粘贴到第一个单元格的笔记本。
babynames=火花。读。格式(“csv”)。选项(“头”,“真正的”)。选项(“inferSchema”,“真正的”)。负载(“dbfs: / FileStore / babynames.csv”)babynames。createOrReplaceTempView(“babynames_table”)年=火花。sql(“从babynames_table选择不同(年)”)。抽样。地图(λ行:行(0])。收集()年。排序()dbutils。小部件。下拉(“年”,“2014”,(str(x)为x在年])显示(babynames。过滤器(babynames。一年= =dbutils。小部件。得到(“年”)))
创建一个工作
点击
 工作流在侧边栏。
工作流在侧边栏。点击
 。
。的任务选项卡显示了创建任务对话框。
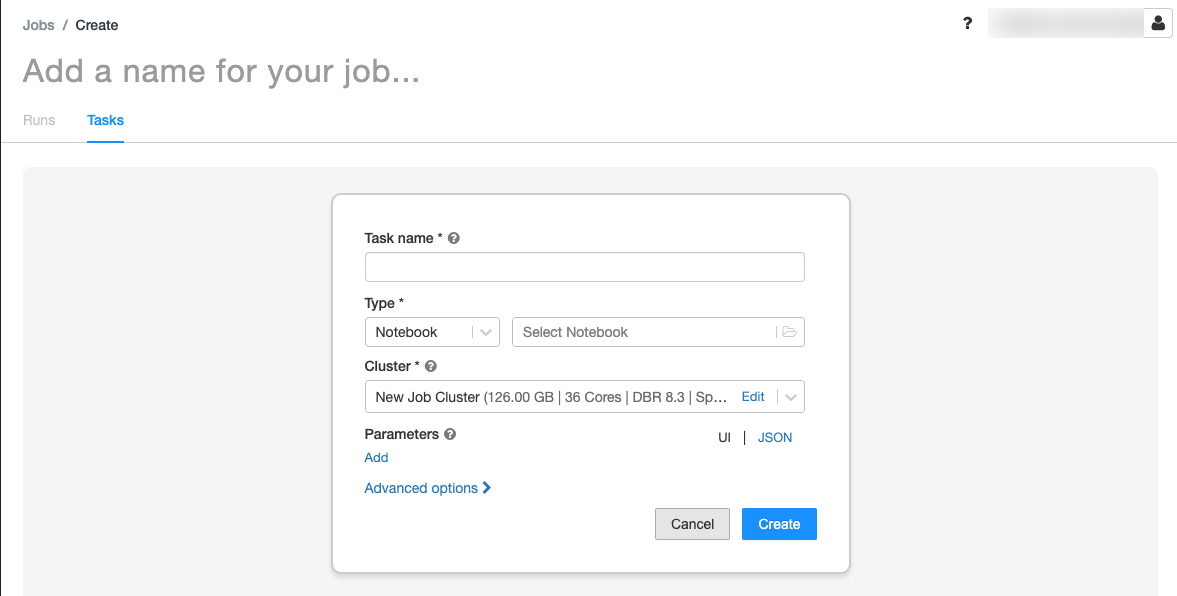
取代添加一个名称为你的工作…对你的工作名称。
在任务名称字段中,输入一个名称的任务;例如,retrieve-baby-names。
在类型下拉,选择笔记本。
使用文件浏览器来找到您创建第一个笔记本,点击笔记本名称,点击确认。
点击创建任务。
点击
 下面您刚才创建的任务添加另一个任务。
下面您刚才创建的任务添加另一个任务。在任务名称字段中,输入一个名称的任务;例如,filter-baby-names。
在类型下拉,选择笔记本。
使用文件浏览器找到创建第二个笔记本,点击笔记本名称,点击确认。
点击添加下参数。在关键字段中,输入
一年。在价值字段中,输入2014年。点击创建任务。
 。
。
 下面您刚才创建的任务添加另一个任务。
下面您刚才创建的任务添加另一个任务。 在右上角。您还可以通过单击运行工作运行选项卡并单击现在运行在活跃的运行表。
在右上角。您还可以通过单击运行工作运行选项卡并单击现在运行在活跃的运行表。