
问题
您正在尝试阅读JSON文件
文件内有数据 但ApachesparkJSON阅读器返回空号值.
示例代码
可使用示例代码复制问题
- 创建测试JSON文件
bob体育客户端下载%python dbutils.fs.rm("dbfs:/tmp/json/parse_test.txt") dbutils.fs.put("dbfs:/tmp/json/parse_test.txt", """ {"data_flow":{"upstream":[{"$":{"source":"input"},"cloud_type":""},{"$":{"source":"File"},"cloud_type":{"azure":"cloud platform","aws":"cloud service"}}]}} """) - 读JSON文件
Pythonjsontest=spark.read.opt
- 结果为空值
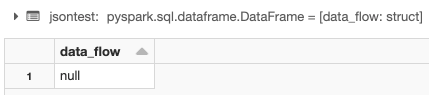
因果
- spark 2.4和下方JSON解析器允许空字符串仅某些数据类型,例如整数组视之为空号空时
- spark3.0和3.0以上,JSON解析器不允许空字符串excepted所有数据类型二进制类型并字符串类型.
获取更多信息,审查SparkSQL迁移指南.
示例代码
示例JSON显示错误,因为数据有两个完全相同的分类域
上首云型项为空字符串 。二次云型项有数据
bob体育客户端下载"cloud_type":"" "cloud_type":{"azure":"cloud platform","aws":"cloud service"}
因JSON解析器不允许spark3.0以上空字符串空号值返回输出
求解
设置spark配置高山市AWS系统|休眠|GCP)值spark.sql.legacy.json.allowEmptyString.enabled至真实性.配置spark3.0JSON解析器允许空字符串
可设置集群级配置或笔记本级配置
示例代码
%python spark.conf.set("spark.sql.legacy.json.allowEmptyString.enabled", True) jsontest1 = spark.read.option("inferSchema","true").json("dbfs:/tmp/json/parse_test.txt") display(jsontest1)
