问题
s3数据通过分区存储时,分区列值用于命名源目录结构中的文件夹但如果使用SQS队列流出源码,S3-SQS源码无法检测分区列值
举例说,如果以JSON格式将下列DataFrame保存S3
scalavaldf=spark.range/json
文件底层结构为 :
scalas3a/bucket/json/sUCCESSs3a/bucket-name/json/date=2018-10-25/
假设你用队列配置 S3-SQS输入流直接从S3-SQS输入流装入数据时使用下列代码:
scala导入org.ache.sql类型.#valsema/struct-1.mazonaws.com/82676605/sqs-quee
输出为 :
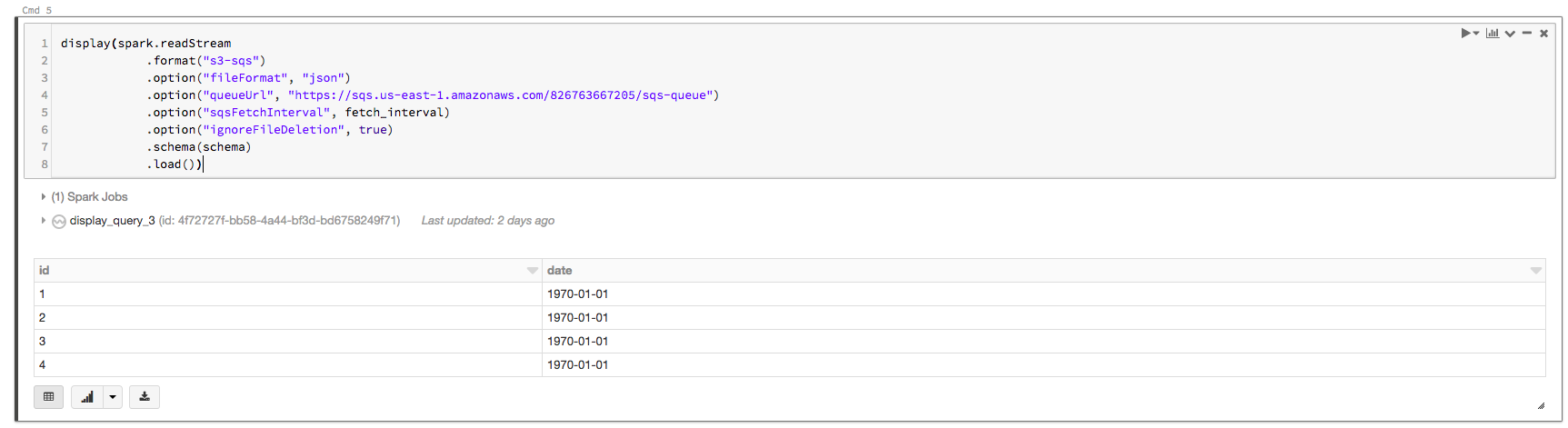
可见日期列值没有正确配置
求解
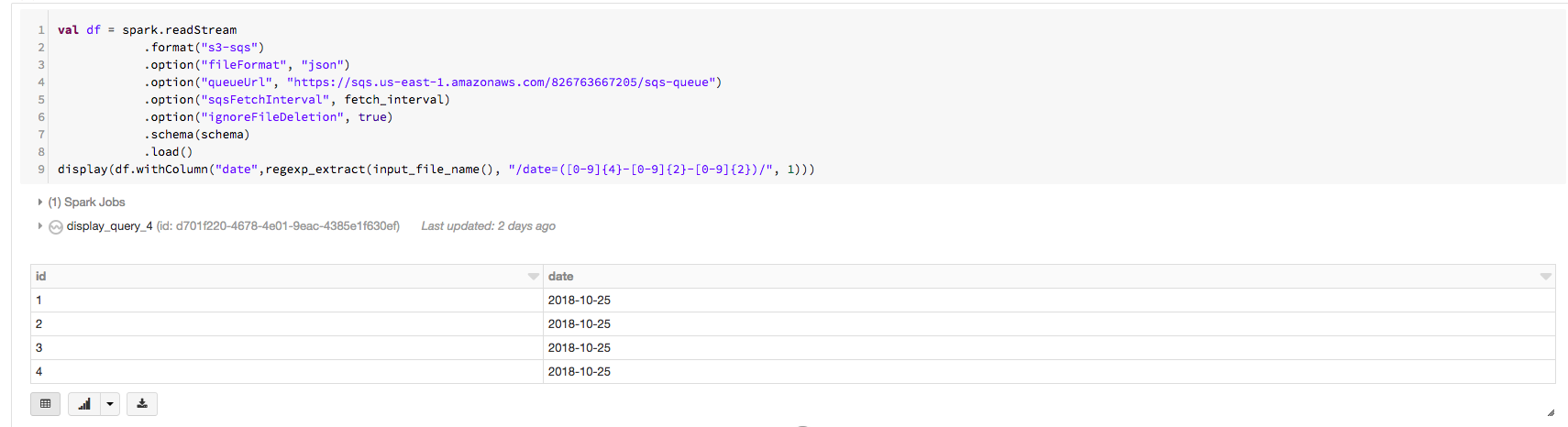
可组合使用input_file_name()并regexp_extract()UDFs正确提取日期值,如下列代码片段
scali导入s.ache.sql.format.schema/
可见日期列正确值如下输出: