Photon是Databricks Lakehouse平台上的下一代引擎,以低成本提供极快的查询性能-从数据摄取,ETL,流媒体,bob体育客户端下载数据科学和交互式查询-直接在您的数据湖上。Photon与Apache Spark™api兼容,因此启动它就像打开它一样简单——无需更改代码,也无需锁定。

![]()
更便宜更快
为了以更低的成本实现最快的性能,Photon提供高达80%的TCO节省,同时加速数据和分析工作负载-高达12倍的加速。
![]()
为所有用例构建
Photon是第一个使数据团队能够在一组api上标准化所有工作负载的引擎——ETL、分析和数据科学——批处理或流处理。
![]()
没有代码更改
Photon是一个兼容ansi的引擎,旨在与现代Apache Spark api兼容,只与您现有的代码- SQL, Python, R, Scala和Java -不需要重写。
为什么光子?
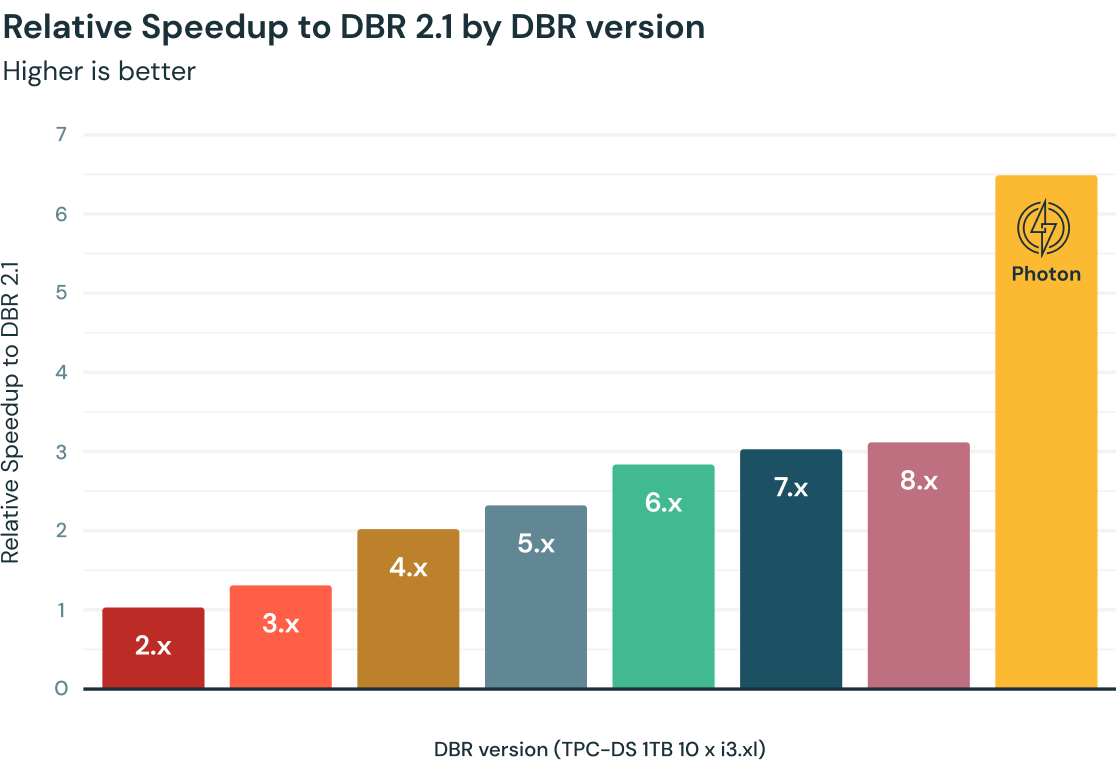
在Apache Spark的支持下,Databricks上的查询性能多年来稳步提高,Databricks运行时(DBR)中封装了数千个优化。Photon——一个完全用c++编写的全新原生向量化引擎——在TPC-DS 1TB基准测试中提供了额外的2倍加速,与最新的DBR版本相比,根据客户的工作负载,他们已经观察到平均3 - 8倍的加速。

用例

生产工作
加速SQL和Spark dataframe上的大规模生产作业

物联网应用
与Spark和传统的Databricks Runtime相比,使用Photon进行更快的时间序列分析

数据隐私和遵从性
使用Delta Lake、生产作业和Photon查询pb级数据集,识别和删除记录,无需重复数据

正在向Delta Lake和Parquet加载数据
Photon的向量化I/O加速了Delta Lake和Parquet表的数据加载,降低了总体运行时间和数据工程作业的成本
它是如何工作的?
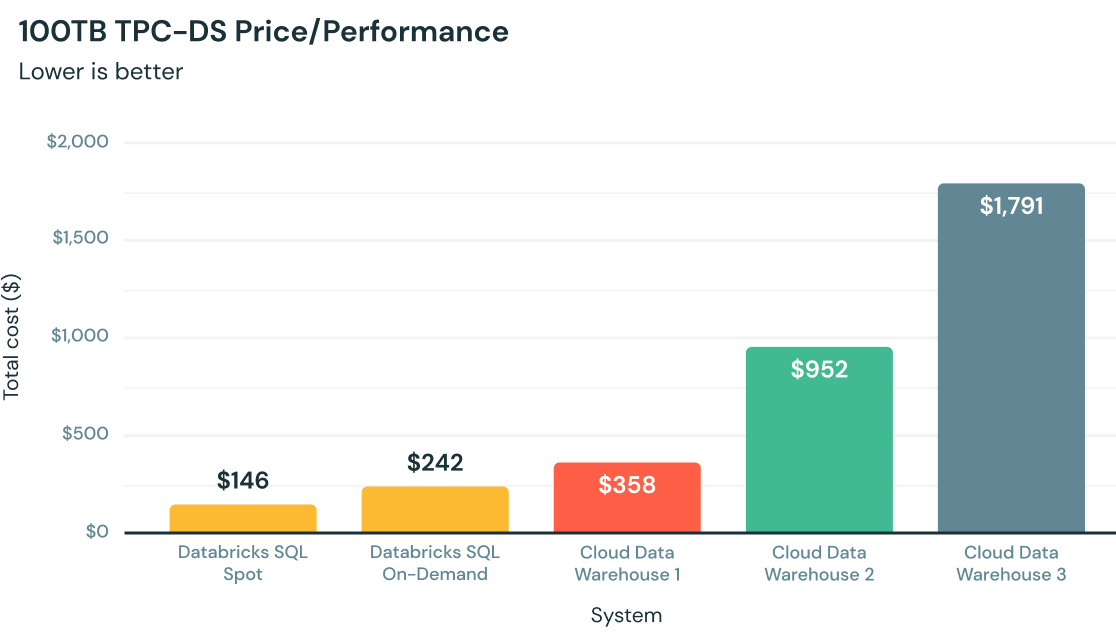
云分析的最佳价格/性能
Photon由c++从头开始编写,利用现代硬件实现更快的查询,与其他云数据仓库相比,提供高达12倍的更好的价格/性能-所有这些都在您的数据湖上。
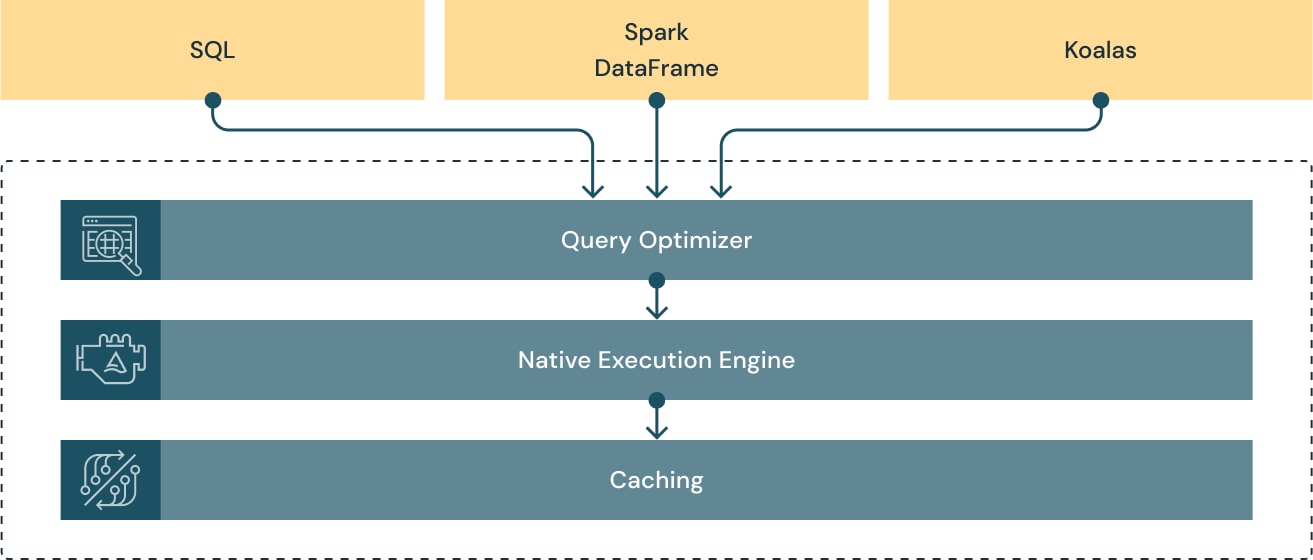
使用现有代码并避免供应商锁定
Photon被设计为与Apache Spark DataFrame和SQL api兼容,以确保工作负载无缝运行而无需更改代码。所有你要做的就是从Photon中受益。Photon将无缝地协调工作和资源,透明地加速SQL和Spark查询的部分。不需要调优或用户干预。

针对所有数据用例和工作负载进行优化
当我们开始Photon时,主要专注于SQL,为客户的数据湖提供世界级的数据仓库性能,从那时起,我们显著增加了Photon支持的输入源、格式、api和方法的范围。因此,客户在所有现代Spark工作负载(例如Spark SQL和DataFrame)上都看到了巨大的基础设施成本节约和Photon的加速。



