



Project Tungsten:让Apache Spark更接近裸金属
在之前的一篇博客文章中,我们回顾并调查了Apache Spark在过去一年中所做的性能改进。在这篇文章中…
在之前博客,我们回顾并调查了过去一年Apache Spark的性能改进。在这篇文章中,我们期待并与你分享下一章,我们称之为项目钨。2014年见证了Spark在大规模排序方面创造了世界纪录,并见证了从Python到SQL再到机器学习的整个引擎的重大改进。然而,性能优化是一个永远不会结束的过程。
项目钨这将是Spark项目启动以来对执行引擎的最大改动。它着重于大幅提高的效率内存和CPU为火花的应用程序,将性能推向现代硬件的极限。这项工作包括三项举措:
对CPU效率的关注是由于Spark工作负载越来越多地受到CPU和内存使用的瓶颈,而不是IO和网络通信的瓶颈。最近对大数据工作负载性能的研究显示了这一趋势(Ousterhout等),作为我们正在进行的调优和优化工作的一部分,我们也得到了类似的发现砖云客户。
为什么CPU是新的瓶颈?原因有很多。一是硬件配置提供越来越大的IO聚合带宽,例如网络中的10Gbps链路和用于存储的高带宽SSD或条纹HDD阵列。从软件的角度来看,Spark的优化器现在允许许多工作负载通过删除给定作业中不需要的输入数据来避免大量的磁盘IO。在Spark的shuffle子系统中,序列化和散列(受CPU限制)已被证明是关键的瓶颈,而不是底层硬件的原始网络吞吐量。所有这些趋势都意味着Spark目前经常受到CPU效率和内存压力的限制,而不是IO。
JVM上的应用程序通常依赖于JVM的垃圾收集器来管理内存。JVM是一项令人印象深刻的工程壮举,它被设计为许多工作负载的通用运行时。然而,随着Spark应用程序不断突破性能边界,JVM对象和GC的开销变得不可忽略。
Java对象具有很大的固有内存开销。考虑一个简单的字符串“abcd”,使用UTF-8编码需要4个字节来存储它。然而,JVM的本机String实现以不同的方式存储这些数据,以方便更常见的工作负载。它使用2个字节的UTF-16编码对每个字符进行编码,并且每个String对象还包含一个12字节的头和8字节的散列代码,如下面的输出所示Java对象布局工具。
. lang。字符串对象内部:偏移量大小类型描述值04(对象标题)…44(对象标题)…84(对象标题)…124char []字符串value []164int字符串.hash020.4int字符串.hash320实例大小:24bytes(由Instrumentation API报告)一个简单的4字节字符串在JVM对象模型中总共超过48字节!
JVM对象模型的另一个问题是垃圾收集的开销。在较高的级别上,分代垃圾收集将对象分为两类:具有高分配/回收率的对象(年轻代)和保留的对象(老代)。垃圾收集器利用年轻代对象的瞬态特性来有效地管理它们。当GC可以可靠地估计对象的生命周期时,这种方法工作得很好,但如果估计错误(即一些瞬态对象溢出到老一代中),则效果就不佳了。由于这种方法最终基于启发式和估计,因此要想获得性能可能需要GC调优的“黑魔法”数十个参数给JVM更多关于对象生命周期的信息。
然而,Spark不仅仅是一个通用应用程序。Spark理解数据如何在计算的各个阶段以及作业和任务的范围中流动。因此,Spark比JVM垃圾收集器了解更多关于内存块生命周期的信息,因此应该能够比JVM更有效地管理内存。
为了解决对象开销和GC效率低下的问题,我们引入了显式内存管理器,将大多数Spark操作转换为直接针对二进制数据而不是Java对象进行操作。这是建立在sun.misc.UnsafeJVM提供的高级功能,公开c风格的内存访问(例如显式分配,释放,指针算术)。此外,不安全的方法内在,这意味着每个方法调用都被JIT编译成一条机器指令。
在某些领域,Spark已经开始使用显式托管内存。去年,Databricks提供了一种新的基于net的网络传输,使用类似jemalloc的内存管理器显式管理所有网络缓冲区。这对于扩大Spark的shuffle操作并赢得排序基准测试至关重要。
第一部分将出现在Spark 1.4中,其中包括一个哈希表,它直接对二进制数据进行操作,内存由Spark显式管理。与标准Java相比HashMap,这个新的实现减少了间接开销,并且对垃圾收集器是不可见的。
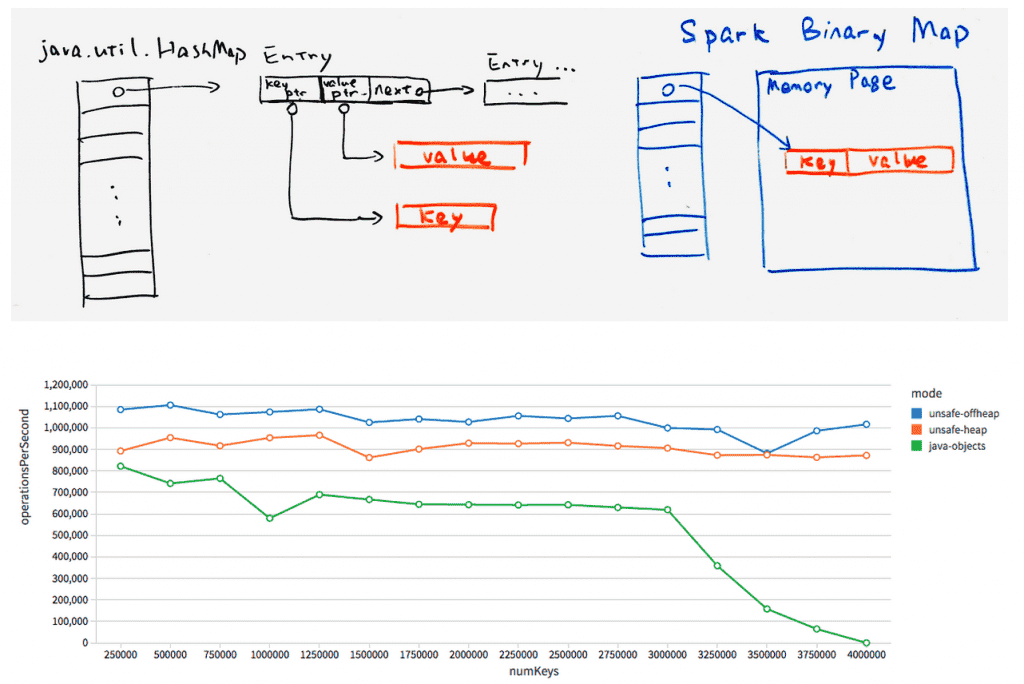
这项工作仍在进行中,但最初的性能结果令人鼓舞。如上所示,我们比较了使用不同哈希映射的聚合操作的吞吐量:一个使用新哈希映射的堆模式,一个使用堆外模式,一个使用java.util.HashMap。新的哈希表在单个线程中支持每秒超过100万次聚合操作,大约是java.util.HashMap吞吐量的2倍。更重要的是,在不调优任何参数的情况下,当内存利用率增加时,它几乎没有性能下降,而JVM默认的内存利用率最终会因为GC而崩溃。
在Spark 1.4中,这个散列映射将用于dataframe和SQL的聚合,在1.5中,我们将为大多数其他操作(如排序和连接)准备好数据结构。在许多情况下,这将消除调优GC以实现高性能的需要。
在解释缓存感知计算之前,让我们回顾一下“内存中”计算。Spark是众所周知的内存计算引擎。这个术语的真正含义是Spark可以有效地利用集群上的内存资源,以比基于磁盘的解决方案高得多的速度处理数据。然而,Spark也可以处理比可用内存大的数据数量级,透明地溢出到磁盘并执行排序和散列等外部操作。
类似地,缓存感知计算通过更有效地使用L1/ L2/L3 CPU缓存来提高数据处理的速度,因为它们比主存快几个数量级。在分析Spark用户应用程序时,我们发现很大一部分CPU时间都花在了等待从主存中提取数据上。作为Project Tungsten的一部分,我们正在设计缓存友好的算法和数据结构,这样Spark应用程序将花更少的时间等待从内存中获取数据,而花更多的时间做有用的工作。
以记录排序为例。一个标准的排序过程将存储一个指向记录的指针数组,并使用快速排序来交换指针,直到所有记录都被排序。由于顺序扫描访问模式,排序通常具有良好的缓存命中率。然而,对指针列表排序的缓存命中率很低,因为每个比较操作都需要对指向内存中随机位置记录的两个指针进行解引用。

那么我们如何提高排序的缓存局部性呢?一种非常简单的方法是将每个记录的排序键与指针并排存储。例如,如果排序键是一个64位整数,那么我们使用128位(64位指针和64位键)将每条记录存储在指针数组中。这样,每个快速排序比较操作只以线性方式查找指针键对,而不需要随机内存查找。希望上面的插图能让您了解如何重新设计基本操作以实现更高的缓存位置。
这一点如何应用于Spark呢?大多数分布式数据处理可以归结为一小部分操作,如聚合、排序和连接。通过提高这些操作的效率,我们可以从整体上提高Spark应用程序的效率。我们已经构建了一个感知缓存的sort版本,比以前的版本快3倍。这种新的排序将用于基于排序的洗牌、高基数聚合和排序合并连接运算符。到今年年底,大多数Spark的最低级别算法将升级为缓存感知,提高从机器学习到SQL的所有应用程序的效率。
大约一年前,Spark推出了表达式求值的代码生成SQL和DataFrames。表达式求值是计算表达式值的过程(例如“年龄> 35岁”)。在运行时,Spark动态生成用于计算这些表达式的字节码,而不是为每一行逐个执行较慢的解释器。与解释相比,代码生成减少了原始数据类型的装箱,更重要的是避免了昂贵的成本多态函数分派.
在一个之前的博客文章,我们演示了代码生成可以将许多TPC-DS查询的速度提高几乎一个数量级。我们现在正在将代码生成的范围扩大到大多数内置表达式。此外,我们还计划提高代码生成的级别record-at-a-time表达式求值到矢量化表达式求值,利用JIT的能力在现代cpu中开发更好的指令管道,这样我们就可以一次处理多条记录。
我们还将代码生成应用于表达式计算以外的领域,以优化内部组件的CPU效率。对于应用代码生成,我们非常兴奋的一个方面是加快数据从内存二进制格式到用于shuffle的有线协议的转换。如前所述,shuffle经常受到数据序列化而不是底层网络的限制。通过代码生成,我们可以提高序列化的吞吐量,进而提高shuffle网络的吞吐量。

上面的图表比较了使用Kryo序列化器和代码生成的自定义序列化器在一个线程中排列800万复杂行的性能。代码生成的序列化器利用了这样一个事实,即单个shuffle中的所有行都具有相同的模式,并为此生成专门的代码。这使得生成的版本比Kryo版本快2倍。
Project Tungsten是一个广泛的计划,它将在接下来的几个版本中影响Spark核心引擎的设计。第一部分将登陆Spark 1.4,其中包括显式管理内存聚合操作在Spark的DataFrame API中定制的序列化器.扩展的二进制内存管理和缓存感知数据结构将出现在Spark 1.5中。项目的几个部分利用了DataFrame模型。我们也会在任何可能的情况下对Spark的RDD API进行改进。
钨也有一些长期的可能性。特别是,我们计划研究LLVM或OpenCL的编译,这样Spark应用程序就可以利用现代cpu和gpu中的广泛并行性来加速机器学习和图计算的操作。
Spark的目标一直是提供一个单一平台,用户可以为任何数据处理任务获得最佳的分布式算法。bob体育客户端下载性能是实现这一目标的关键部分,Project Tungsten旨在让Spark应用程序以裸机提供的速度运行。请继续关注Databricks博客,以获得有关Project Tungsten组件的长期文章。