



Apache火花作为编译器:加入每秒十亿行上一台笔记本电脑
当我们的团队在砖计划即将到来的Apache 2.0版本,我们贡献我们设定了一个雄心勃勃的目标,…
2016年5月23日 在工程的博客
当我们的团队在砖计划即将到来的Apache 2.0版本,我们贡献我们设定了一个雄心勃勃的目标,问自己:Apache火花已经很快,但我们能让它快10倍吗?
这个问题让我们从根本上重新思考我们建立了火花身体执行层。当你看到在现代数据引擎(例如火花或其他MPP数据库),大多数CPU周期的花在无用的工作,如制作虚拟函数调用或阅读或写作中间数据CPU缓存或内存。通过减少CPU周期的数量优化性能浪费在无用的现代编译器的工作已经长期关注。
Apache 2.0火花将船第二代钨引擎。建立在思想与现代编译器和MPP数据库和应用于数据处理查询,钨发出(火花- 12795)在运行时优化字节码,瓦解整个查询到一个单一的功能,消除虚函数调用和中间数据利用CPU寄存器。由于这种简化策略,称为“舞台代码生成”我们显著改善CPU效率和增益性能。
之前我们深入了解舞台代码生成的细节,让我们重新审视目前火花(和大多数数据库系统)是如何工作的。让我们用一个简单的查询,说明这个扫描单个表和计算元素的数量与给定属性值:

评估这个查询,旧版本(1. x)的火花杠杆流行经典查询评估策略基于迭代器模式(通常被称为火山模型)。在这个模型中,一个查询包含多个运营商,并且每个运营商提供了一个接口,next ()一次,返回一个元组中的下一个算子树。例如,过滤操作符大约在上面的查询转化为下面的代码:
类滤波器(孩子:运营商谓词:= >布尔(行)
扩展操作符{
def next():行= {
当前var = child.next ()
而(当前= null & & !谓词(当前)){
当前= child.next ()
}
返回当前
}
}
在每个操作符实现迭代器接口允许查询执行引擎的优雅组合任意组合运营商,而不必担心每个运营商都提供不透明的数据类型。因此,火山模型成为了标准数据库系统在过去的二十年,也是架构用于火花。
跑题了一点,如果我们问一个大学新生,给她十分钟在Java中实现上面的查询?很可能她会想出迭代循环遍历输入的代码,将计算谓词和计数的行:
var计算= 0
(在store_sales ss_item_sk) {
如果(ss_item_sk = = 1000) {
数+ = 1
}
}
上面的代码编写专门回答一个给定的查询,显然不是“可组合。“但如何two-Volcano生成和手写代码比较性能?一方面,我们有选择的体系结构可组合性的火花和大多数数据库系统。另一方面,我们有一个简单的程序由一个新手在10分钟内写的。我们运行了一个简单的基准测试,比较了“大学新生”版本的程序和火花程序执行上面的查询对镶木地板使用单个线程数据在磁盘上:

如您所见,“大学新生”手写版本是一个数量级的速度比火山模型。原来的6行Java代码进行了优化,有以下原因:
next ()函数至少一次。这些函数调用编译器实现的虚函数分派(通过vtable)。手写代码,另一方面,没有一个函数调用。虽然虚函数调度集中的优化在现代计算机体系结构中,它仍然成本可以将多个CPU指令和非常缓慢,特别是当调度数十亿倍。这里的关键论点是,手写代码被编写具体运行查询并没有别的,因此它可以利用已知的所有信息,导致优化代码,消除虚函数分派,在CPU寄存器保存中间数据,可以通过底层硬件进行优化。
从上面观察,自然为我们下一步是探讨自动生成的可能性手写的代码在运行时,我们称之为“舞台代码生成。“这想法是受托马斯·诺伊曼的开创性VLDB 2011年的论文现代硬件有效编制高效的查询计划。为更多的细节在纸上,阿德里安鼠鸟协调出版晨报博客上的评论今天。
我们的目标是利用舞台代码生成引擎可以实现手写代码的性能,但提供了一个通用引擎的功能。而不是依靠运营商处理数据在运行时,这些操作符生成代码在运行时和崩溃的每个片段的查询,在可能的情况下,成一个单一的函数并执行生成的代码。
例如,在上面的查询中,整个查询是一个单级,火花将生成以下JVM字节码(在Java代码的形式说明)。更复杂的查询将导致多个阶段,因此多个不同的功能所产生的火花。
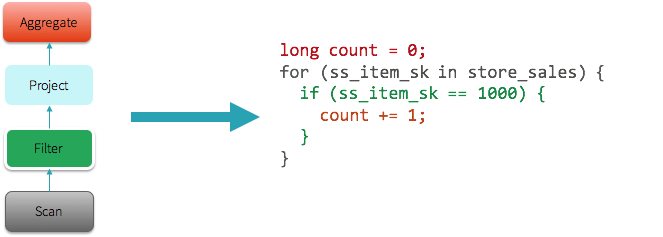
的解释()下面的表达式功能扩展了舞台代码生成。在解释输出,当操作员(*)有一个明星,舞台启用代码生成。在下列情况下,范围、过滤和舞台的两个总量都是运行代码生成。交流,然而,没有实现舞台代码生成,因为它是通过网络发送数据。
火花。范围(1000年)。过滤器(“id > 100”).selectExpr (“总和(id)”).explain ()
= = = =物理计划*总(函数= (总和(id# 201 l)))+ - SinglePartition交换,没有一个+ - *总(函数= (总和(id# 201 l)))+ - *过滤器(id# 201 l > 100)+ - *范围0,1,3,1000年,(id# 201 l)你们已经密切关注火花的发展可能会问以下问题:“我听说过代码生成自Apache 1.1火花这篇博客。这次怎么不同呢?“过去,类似于其他MPP查询引擎,火花只应用代码生成表达式求值和仅限于少数运营商(如项目,过滤器)。代码生成,在过去只有加快评估表达式如“1 +”,而今天舞台代码生成整个查询计划的生成代码。
舞台代码生成技术对大型特别有效的执行简单的查询,可预见的操作大型数据集。然而,这是不可行的情况下生成代码来查询整个熔合成一个单一的函数。操作可能太复杂(例如解析CSV或镶花解码),或者可能有情况下当我们结合第三方组件,不能将他们的代码集成到我们生成的代码(例子的范围可以从调用Python / R卸载GPU计算)。
以提高性能在这些情况下,我们采用另一种方法称为“向量化。“这里的想法是,而不是一次处理一行数据,引擎批次倍数行柱状的格式,和每个操作符使用简单的循环来遍历数据在一个批处理。每一个next ()调用将返回一个元组批,掩盖了虚函数分派的成本。这些简单的循环也会使编译器和cpu与前面提到的好处更有效地执行。
作为一个例子,对于一个表有三个列(id、名称、分数),以下说明row-oriented格式和用于格式的内存布局。
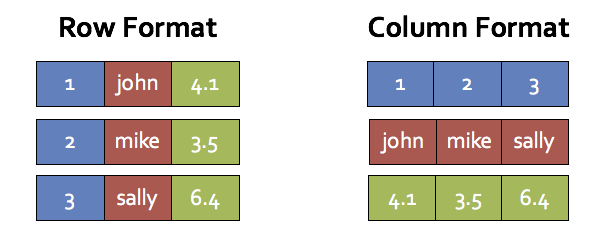
这种风格的处理,由柱状数据库系统如MonetDB C-Store,将实现两个前面提到的三个点(几乎没有虚函数分派和自动循环展开/ SIMD)。然而,它仍然需要把中间数据内存而不是让他们在CPU寄存器。因此,我们使用向量化只有当舞台代码生成是不可能的。
例如,我们实现了一个新的矢量化铺读者,减压和解码列批次。当解码整数列(在磁盘上),这个新的读者大概是9倍non-vectorized一:

在未来,我们计划使用向量化等更多的代码路径的UDF Python / R的支持。
我们有测量的时间(纳秒)需要处理一个元组在一个核心的一些运营商在Apache 1.6和Apache 2.0火花,火花,下表是一个比较新的钨引擎的力量。火花1.6包含表达式代码生成技术,也在今天使用一些先进的商业数据库。
成本每一行(在纳秒,单线程)
| 原始的 | 火花1.6 | 火花2.0 |
|---|---|---|
| 过滤器 | 15 ns | 1.1 ns |
| 和w / o组 | 14 ns | 0.9 ns |
| 和w /组 | 79纳秒 | 10.7 ns |
| 散列连接 | 115纳秒 | 4.0 ns |
| 排序熵(8位) | 620纳秒 | 5.3 ns |
| 排序熵(64位) | 620纳秒 | 40 ns |
| 分类合并加入 | 750纳秒 | 700纳秒 |
| 镶木地板解码(单个整数列) | 120纳秒 | 13 ns |
我们调查客户的工作负载和舞台实现代码生成最常用的运营商,如过滤、聚合,和散列连接。正如你所看到的,许多核心运营商与舞台代码生成快一个数量级。然而,一些分类合并等运营商加入天生慢,优化更加困难。
需要不到一秒执行散列连接操作10亿元组在砖平台(与英特尔Haswell处理器3芯)以及2013年的Macbook Pro(移动Haswell英特尔i7)。bob体育客户端下载
端到端查询这个新引擎是如何工作的?除了舞台代码生成和向量化,很多工作也进入改善催化剂优化器等通用查询优化nullability传播。我们做了一些初步分析使用TPC-DS查询比较火花1.6和2.0即将到来的火花:
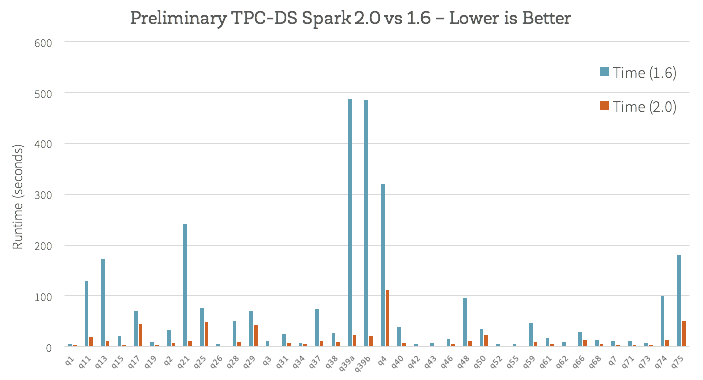
这是否意味着你的工作量会神奇地变成十倍一旦升级到火花2.0吗?不一定。虽然我们相信新的钨引擎实现最好的体系结构在数据处理性能工程,重要的是要理解,不是所有工作负载可以受益到相同的程度。例如,可变长度的数据类型,如字符串是自然更昂贵的操作,和一些工作负载是由其他因素有界从I / O吞吐量元数据操作。以前的工作负载有界通过CPU效率会观察最大的收益,和转向更多的I / O,而以前,I / O工作负载不太可能观察收益。
这篇文章中描述的大部分工作已经提交到Apache火花的代码库,开槽为即将到来的火花2.0版本。舞台的JIRA票代码生成可以在火花- 12795,而向量化的票可以在火花- 12992。
回顾一下,这篇文章描述了第二代钨执行引擎。通过一个称为舞台的技术代码生成引擎将(1)消除虚函数分派(2)中间数据从内存移到CPU寄存器和(3)利用现代CPU通过循环展开和SIMD功能。通过一个称为向量化的技术,发动机也将加快操作过于复杂的代码生成。对于许多核心运营商在数据处理中,新引擎数量级的速度。在未来,考虑到执行引擎的效率,大部分我们的工作将转向性能优化I / O效率和更好的查询计划。
我们对取得的进步感到兴奋,希望你能喜欢这些改进。尝试一些免费,注册一个帐户砖Community Edition。