



三个故事Apache火花api:抽样vs DataFrames和数据集
所有的开发者的喜悦,不是更有吸引力,一组api使开发者生产力,这是易于使用的……
所有的开发者的喜悦,不是更有吸引力,一组api使开发者生产力,容易使用,这是直观的和富有表现力。之一Apache火花的吸引开发人员一直是易于使用的api,对大型数据集操作,跨语言:Scala, Java、Python和R。
在这个博客中,我探索三套APIs-RDDs, DataFrames, Datasets-availableApache 2.2火花和超越;为什么当你使用每组;概述他们的性能和优化优势;和列举场景何时使用DataFrames代替抽样和数据集。大多数情况下,我将关注DataFrames和数据集,因为Apache 2.0火花,这两个api是统一的。
我们这一统一背后的主要动机是为了简化火花通过限制数量的概念,你必须学习和通过提供过程结构化数据的方法。并通过结构、火花可以提供更高级别的抽象和api作为特定于域的语言结构。
抽样是主要面向用户的API引发自成立以来。核心,一个抽样是一个不可变的分布式数据的元素集合,跨中节点集群,可以并行操作的底层API,它提供了转换和行动。
考虑这些场景或常见用例使用抽样时:
你可能会问:抽样被降级为二等公民?他们是被弃用吗?
答案是一个响亮的不!
更重要的是,你会注意到下面,可以无缝地DataFrame之间移动或数据集和抽样将简单的API方法调用和DataFrames和数据集是建立在抽样。
像一个抽样,aDataFrame是一个不可变的分布式数据收集。与一个抽样不同,数据被组织成命名列,就像一个表在关系数据库中。为了让大型数据集处理更简单,DataFrame允许开发人员对结构在分布式数据集合,允许更高级别的抽象;它提供了一个领域特定语言API来操纵你的分布式数据;使火花融入更广泛的受众,除了专门的数据工程师。
在我们的预览Apache 2.0引发网络研讨会和后续的博客火花2.0中,我们提到,DataFrame api将合并数据集在库api,统一的数据处理功能。由于这种统一,开发人员现在有更少的概念来学习或记忆,并使用一个单一的高层和类型安全的API调用的数据集。
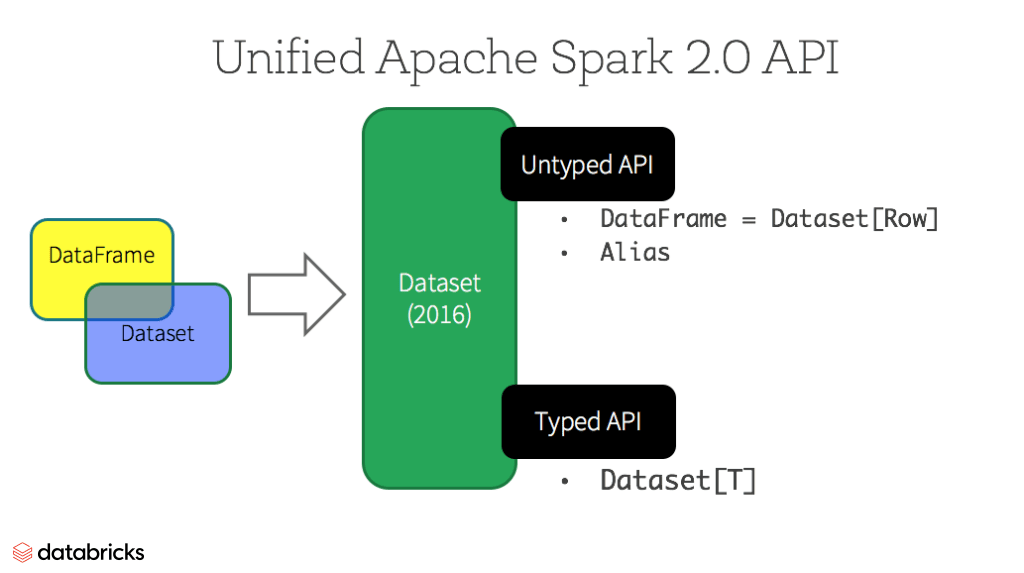
在火花2.0开始,数据集呈现两种截然不同的api特点:a强类型API和一个无类型API,如下表所示。从概念上讲,考虑DataFrame作为别名对于一个通用的对象的集合数据集(行),一个行是一个通用的无类型JVM对象。数据集,相比之下,是一个集强类型JVM对象,由类定义在Scala中或在Java类。
| 语言 | 主要的抽象 |
|---|---|
| Scala | 数据集[T] & DataFrame(数据集(行)别名) |
| Java | 数据集[T] |
| Python * | DataFrame |
| R * | DataFrame |
注意:因为Python和R没有编译时类型安全,我们只有无类型的api,即DataFrames。
作为火花开发人员,您受益与火花DataFrame和数据集统一api 2.0在很多方面。
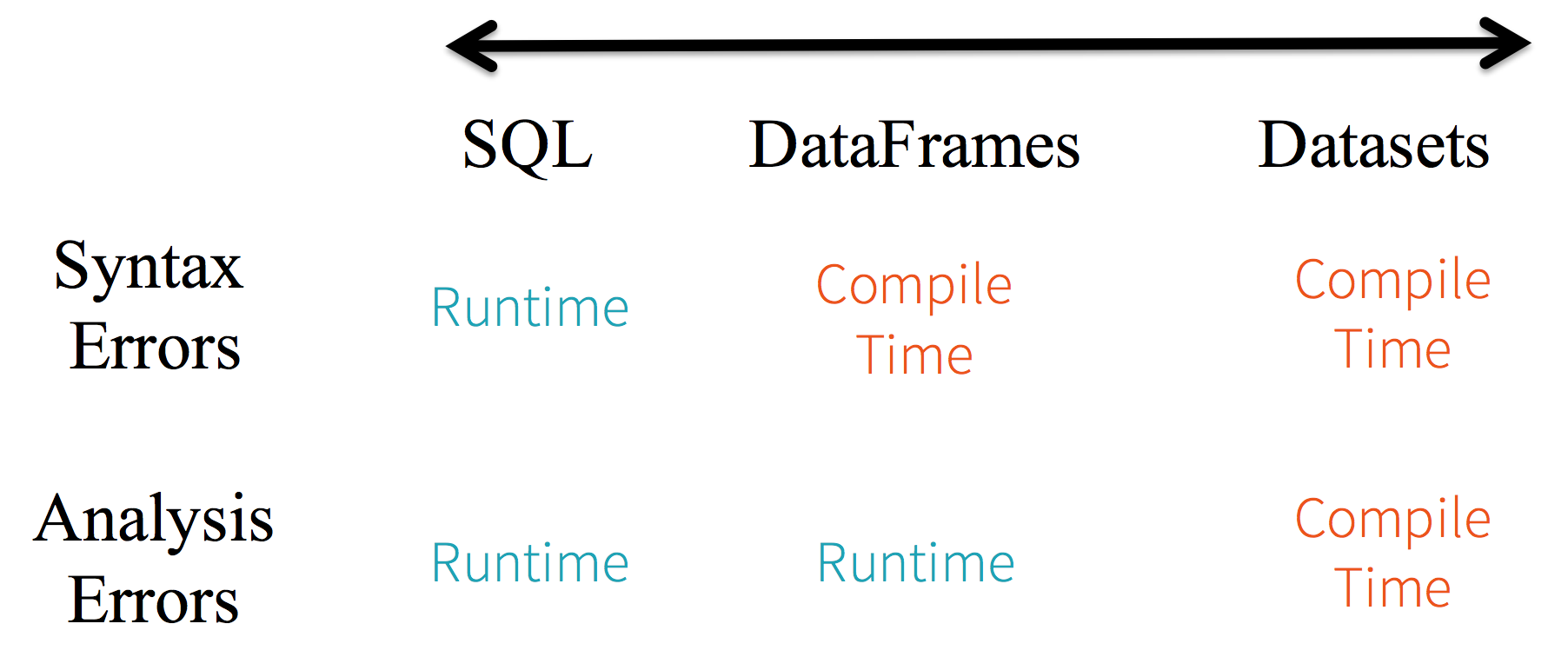
考虑静态类型和运行时安全频谱,SQL限制最小数据集最严格。例如,在你的火花SQL字符串查询,你才知道一个语法错误运行时(它可以是昂贵的),而在DataFrames和数据集可以捕获错误在编译时(这可以节省开发人员的时间和成本)。也就是说,如果您调用一个函数在DataFrame不是API的一部分,编译器会赶上它。然而,它不会直到运行时检测到一个不存在的列名。
在光谱的远端数据集,最严格的。因为数据集api都是表示lambda函数和JVM类型对象,任何不匹配的类型参数将在编译时被发现。同时,分析误差也可以在编译时被发现,当使用数据集,因此节省开发人员的时间和成本。
所有这些翻译是类型安全以及语法和分析误差的频谱在火花代码中,与数据集作为一个开发人员最严格的生产。
DataFrames的集合数据集(行)呈现一个结构化的自定义视图到你的半结构化数据。例如,让我们说,你有一个巨大的物联网设备事件数据集,表示为JSON。从JSON是一种半结构化的格式,它非常适用于使用数据集强烈typed-specific的集合数据集(DeviceIoTData)。
{“device_id”:198164年,“device_name”:“传感器-板- 198164 owomcjz”,“知识产权”:“80.55.20.25”,“cca2”:“PL”,“cca3”:“波尔”,“cn”:“波兰”,“人肉搜索”:53.080000,“经”:18.620000,“规模”:“摄氏度”,“临时”:21,“湿度”:65年,“battery_level”:8,“c02_level”:1408年,“液晶”:“红色”,“时间戳”:1458081226051}你可以表达每一个JSON条目DeviceIoTData自定义对象,Scala类。
情况下类DeviceIoTData (c02_level battery_level:长:长,cca2:字符串,cca3:字符串,cn:字符串,device_id:长,device_name:字符串,湿度:长,ip:字符串,纬度:双液晶显示器:字符串,经度:双规模:字符串,临时:长,时间戳:长)接下来,我们可以从JSON文件读取数据。
/ /读取json文件并创建的数据集/ / case类DeviceIoTData/ / ds现在DeviceIoTData JVM Scala对象的集合val ds = spark.read.json (“databricks-public-datasets /数据/物联网/ iot_devices.json”)。作为(DeviceIoTData)三件事发生下罩在上面的代码:
我们中的大多数人使用结构化数据是谁习惯了查看和处理数据柱状方式或访问特定属性在一个对象中。与数据集的集合数据集应用类型对象,无缝地得到编译时安全性和JVM强类型对象的自定义视图。和你的结果强类型数据集[T]从上面的代码可以很容易地显示或处理的高级方法。
虽然在你的火花结构可能会限制控制程序可以处理数据,介绍了丰富的语义和一组简单的领域特定的操作可以表示为高层结构。然而,大多数计算可以实现数据集的高级api。例如,它执行的简单得多gg,选择,总和,avg,地图,过滤器,或groupBy通过访问数据集类型对象的操作DeviceIoTData比使用抽样行数据字段。
表达你的计算在一个领域特定的API更简单和容易的关系代数表达式类型(抽样)。例如,下面的代码过滤器()和map ()创建另一个不可变的数据集。
/ /使用过滤器(),地图(),groupBy(),并计算avg ()/ /温度和湿度。这个操作的结果/ /另一个不可变的数据集。查询更容易阅读,/ /和富有表现力val dsAvgTmp = ds.filter (d= >{d。临时>25}). map (d= >(d。临时,d。湿度、d.cca3) .groupBy(美元)“_3”).avg ()/ /显示结果数据集显示器(dsAvgTmp)
除了以上优点,你不能忽视的空间效率和性能在使用DataFrames和数据api有两个原因。
首先,因为DataFrame和数据api之上构建火花的SQL引擎,它使用催化剂来生成一个优化的逻辑和物理查询计划。在R、Java、Scala或Python api DataFrame /数据集,所有关系类型查询进行相同的代码优化,提供空间和速度效率。而数据集[T]数据类型的API是优化工程任务,无类型数据集(行)(别名DataFrame)是更快,适合互动分析。

其次,由于火花是一个编译器理解你的数据集类型JVM对象,它将您的JVM特定类型对象映射到钨使用的内存表示编码器。作为一个结果,钨JVM编码器可以有效地序列化/反序列化对象以及产生紧凑的字节码,可以执行以优越的速度。
注意,您总是可以无缝互操作或从DataFrame转换和/或数据集抽样,通过简单的方法调用.rdd。例如,
//选择具体的字段从数据集,应用谓词//使用的在哪里()方法,转换来一个抽样,和显示第一个10//抽样行val deviceEventsDS=ds。选择(“device_name”、“cca3”美元,美元“c02_level”)。在哪里(美元“c02_level”>1300年)//转换来抽样和取第一个10行val eventsRDD=deviceEventsDS.rdd.take (10)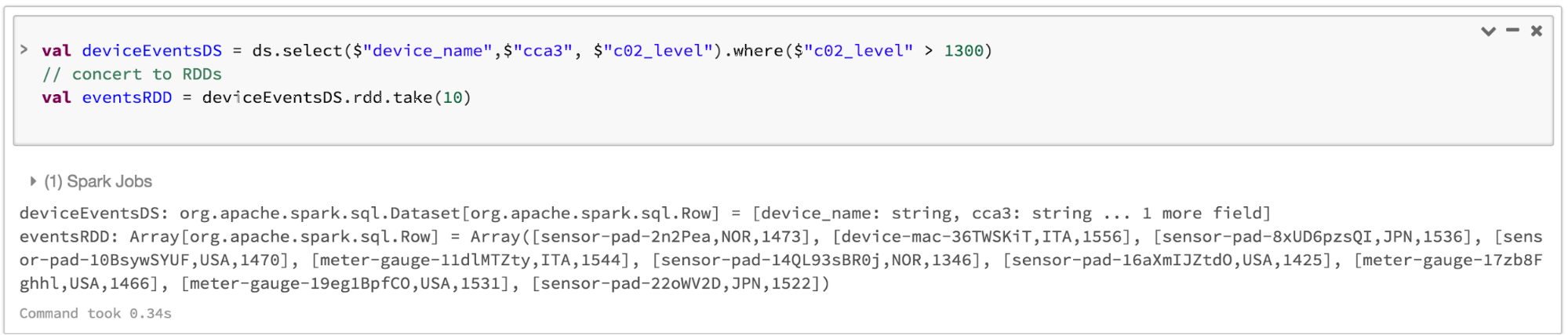
在求和,选择何时使用抽样或DataFrame和/或数据集似乎显而易见。前者提供你低级的功能和控制,后者允许自定义视图和结构,提供了高层和领域特定操作,节省了空间,在优越的执行速度。
当我们检查我们的教训从早期版本的Spark-how简化引发对于开发人员来说,如何优化,使其performant-we决定提升低级抽样api作为DataFrame高层抽象和数据集,建立跨库在这个统一的数据抽象催化剂优化器和钨。
选择one-DataFrames和/或数据集或抽样api,满足您的需求和用例,但我不会感到惊讶,如果你属于大多数开发人员使用的阵营结构和半结构化数据。
你可以Apache 2.2引发数据砖。
你也可以看火花峰会介绍三个故事Apache火花api:抽样vs DataFrames和数据集
如果你还没有注册,现在试着砖。
在未来的几周内,我们将有一系列的博客结构化流。请继续关注。