



实时流ETL与结构化流在Apache Spark 2.1
火花峰会将于2017年2月7日至9日在波士顿举行。查看完整的日程安排,在票卖出去之前买到你的票。
火花峰会将于2017年2月7日至9日在波士顿举行。请查看排满日程和拿到你的票在卖完之前!
我们已经进入了大数据时代,各个组织都在不断地收集大量数据。然而,这种数据洪流的价值取决于能否及时提取可操作的见解。因此,对……的需求越来越大连续应用程序它可以从海量数据摄取管道中获得实时可操作的见解。
然而,构建生产级连续应用程序可能具有挑战性,因为开发人员需要克服许多障碍,包括:
Apache Spark中的结构化流构建在Spark SQL的强大基础之上,利用其强大的api提供无缝的查询接口,同时优化其执行引擎以实现低延迟,不断更新的答案。这篇博文是一个系列的开始,在这个系列中,我们将探讨如何使用Apache Spark 2.1的新特性来克服上述挑战并构建我们自己的生产管道。
在第一篇文章中,我们将重点关注转换raw格式的ETL管道AWS CloudTrail审计日志成一个JIT数据仓库用于更快的临时查询。我们将展示利用现有的批处理ETL作业并随后使用Databricks中的结构化流将其产品化为实时流管道是多么容易。使用这个管道,我们进行了转换380万年JSON文件包含79亿年记录到Parquet表中,这允许我们对每分钟更新的Parquet表进行特别查询,比对原始JSON文件进行查询快10倍。
提取、转换和加载(ETL)管道将原始的、非结构化的数据准备成可以轻松有效地查询的表单。具体来说,他们需要能够做到以下几点:
传统上,ETL是作为周期性批处理作业执行的。例如,实时转储原始数据,然后每隔几个小时将其转换为结构化形式,以实现高效查询。我们最初是这样设置系统的,但这种技术产生了很高的延迟;我们不得不等上几个小时才得到任何消息。对于许多用例,这种延迟是不可接受的。当一个账户出现可疑情况时,我们需要能够立即提出问题。等待几分钟到几个小时可能会导致对事件的响应出现不合理的延迟。
幸运的是,结构化流可以很容易地将这些周期性批处理作业转换为实时数据管道。流式作业使用与批处理数据相同的api表示。此外,该引擎提供与定期批处理作业相同的容错和数据一致性保证,同时提供更低的端到端延迟。
在接下来的文章中,我们将深入探讨我们如何转换的细节AWS CloudTrail审计日志做成高效的、分隔的镶木地板数据仓库。通过将压缩后的JSON日志文件传送到S3存储桶,AWS CloudTrail允许我们跟踪各种AWS账户中执行的所有操作。这些文件支持各种业务和关键任务情报,例如成本归属和安全监视。然而,在其原始形式中,查询它们的成本非常高,即使使用Apache Spark的功能也是如此。为了实现快速洞察,我们运行一个连续应用程序,将原始JSON日志文件转换为优化的Parquet表。让我们深入了解一下如何编写这个管道。如果你想看完整的代码,这里是Scala和Python笔记本。将它们导入Databricks你们自己来管理。
我们首先定义基于的JSON记录的模式CloudTrail文档。
val cloudTrailSchema=新StructType ()。添加(“记录”,ArrayType (新StructType ()。添加(“additionalEventData StringType)。添加(“apiVersion StringType)。添加(“awsRegion StringType)//…请参阅附带的笔记本以获取完整的模式。有了这个,我们可以定义一个流DataFrame,它表示从CloudTrail文件中写入S3 bucket的数据流。
val rawRecords = spark.readStream. schema (cloudTrailSchema). json (“s3n: / / mybucket / AWSLogs / * / CloudTrail / * / 2017 / * / *”)这是理解这个的好方法rawRecordsDataFrame表示的是首先理解的结构化流编程模型。关键思想是将任何数据流视为无界表:添加到流中的新记录就像添加到表中的行一样。
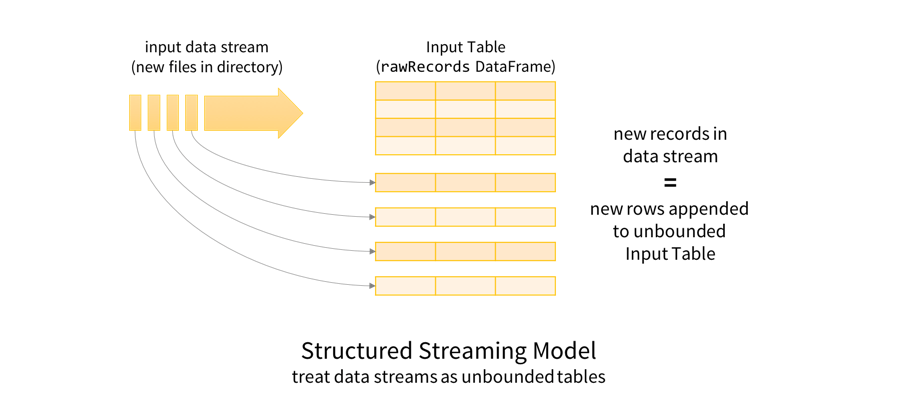
这允许我们将批处理和流数据都视为表。由于表和数据框架/数据集在语义上是同义的,同样的类似批处理的DataFrame/Dataset查询可以应用于批处理和流数据。在这种情况下,我们将转换原始JSON数据,以便使用Spark SQL对操作复杂嵌套模式的内置支持更容易进行查询。下面是这个转换的删节版。
val cloudtrailEvents=rawRecords。选择(爆炸(美元“记录”)作为的记录).select (unix_timestamp (“record.eventTime”美元,“yyyy-MM-ddT'hh:mm:ss ').cast("timestamp")为'时间戳“记录。*”美元)在这里,我们爆炸(拆分)从每个文件加载的记录数组到单独的记录。我们还将每条记录中的字符串事件时间字符串解析为Spark的时间戳类型,并将嵌套列扁平化以方便查询。注意,如果cloudtrailEvents是固定文件集上的批处理DataFrame,那么我们将编写相同的查询,并且我们将只将结果写入一次parsed.write.parquet (" / cloudtrail”)。相反,我们将开始StreamingQuery它会持续运行,在新数据到达时进行转换。
val streamingETLQuery=cloudtrailEvents.withColumn(“日期”、“时间戳”。投(“日期”)//推导出日期.writeStream。触发(ProcessingTime(10秒))//检查为文件每一个10年代.format(“铺”)//写作为镶木地板分区通过日期.partitionBy(“日期”).option(“路径”、“/ cloudtrail”).option(“checkpointLocation”、“cloudtrail.checkpoint /”)。开始()这里,我们在启动StreamingQuery之前为它指定以下配置。
/ cloudtrail。检查点/ cloudtrail用于容错(稍后将在博客中解释)就结构化流模型而言,这就是执行该查询的方式。
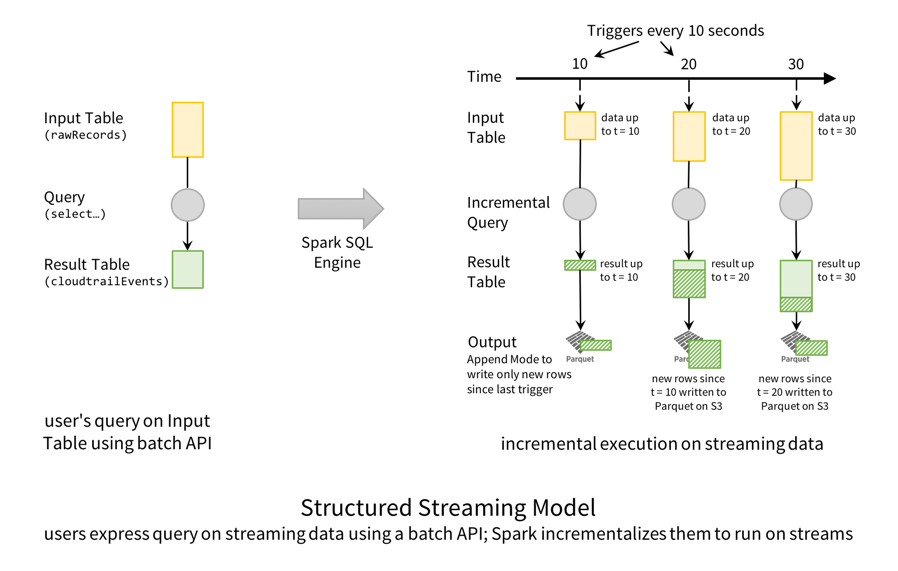
从概念上讲,rawRecordsDataFrame是只能追加的输入表,和cloudtrailEventsDataFrame是转换后的结果表。换句话说,当新行追加到输入(rawRecords)、结果表(cloudtrailEvents)将有新的转换行。在这种特殊情况下,每10秒,Spark SQL引擎触发器检查新文件。当它发现新数据(即输入表中的新行)时,它将数据转换为在结果表中生成新行,然后将其作为Parquet文件写出来。
此外,当这个流查询运行时,您可以使用Spark SQL同时查询Parquet表。流查询以事务方式写入Parquet数据,这样并发交互式查询处理将始终看到最新数据的一致视图。这种强有力的保证被称为prefix-integrity它使结构化流管道与更大的持续应用程序很好地集成在一起。
您可以阅读更多关于结构化流模型的详细信息,以及它相对于其他流引擎的优势以前的博客。
前面,我们强调了在生产环境中运行流ETL管道必须解决的一些挑战。让我们看看运行在Databricks平台上的结构化流是如何解决这些问题的。bob体育客户端下载
长时间运行的管道必须能够容忍机器故障。使用结构化流,实现容错就像为查询指定检查点位置一样简单。在前面的代码片段中,我们在下一行中这样做了。
.option (“checkpointLocation”,“cloudtrail.checkpoint /”)这个检查点目录是针对每个查询的,当查询处于活动状态时,Spark会不断地将处理过的数据的元数据写入检查点目录。即使整个集群失败,也可以在新集群上重新启动查询,使用相同的检查点目录,并始终恢复。更具体地说,在新集群上,Spark使用元数据在失败的查询停止的地方启动新的查询,从而确保端到端只执行一次的保证和数据一致性(参见故障恢复部分).
此外,只要输入源和输出模式保持不变,这种相同的机制允许您在重新启动之间升级查询。从Spark 2.1开始,我们将检查点数据编码为JSON,以保证未来的兼容性。因此,即使更新了Spark版本,也可以重新启动查询。在所有情况下,您都将获得相同的容错性和一致性保证。
请注意,Databricks使它非常容易设置自动恢复,我们将在下一节中展示。
为了使连续应用程序顺利运行,它必须对单个机器甚至整个集群的故障具有健壮性。在Databricks中,我们开发了与结构化流的紧密集成,允许我们持续监控StreamingQueries的失败(并自动重新启动它们)。您所要做的就是创建一个新的Job,并配置Job重试策略。您还可以将作业配置为发送电子邮件以通知失败。
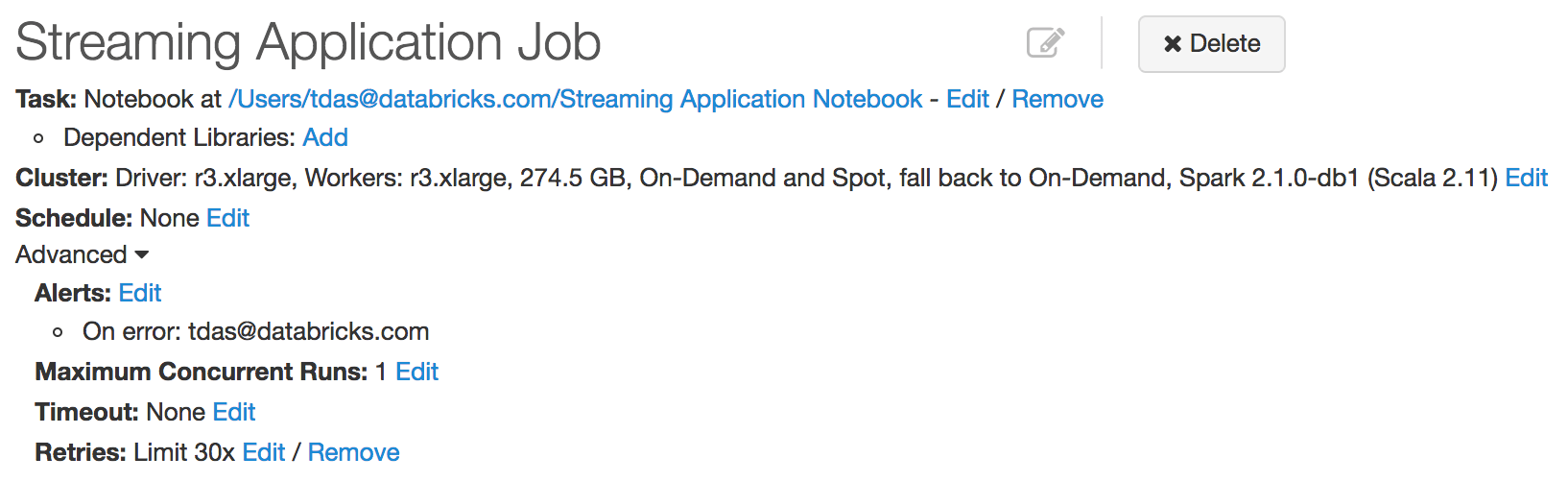
通过更新代码和/或Spark版本,然后重新启动Job,可以轻松地进行应用程序升级。看到我们的在生产中运行结构化流的指南了解更多详情。
机器故障并不是我们需要处理以确保稳健处理的唯一情况。我们将在本系列后面的文章中详细讨论如何监控流量峰值和上游故障。
许多应用程序需要将历史/批处理数据与实时数据结合起来。例如,除了传入的审计日志之外,我们可能已经有大量等待转换的日志积压。理想情况下,我们希望两者都能实现,既能以交互方式尽快查询最新数据,又能访问历史数据,以便将来进行分析。使用大多数现有系统设置这样的管道通常很复杂,因为您必须设置多个进程:转换历史数据的批处理作业,转换实时数据的流管道,以及合并结果的另一个步骤。
结构化流消除了这一挑战。您可以配置上述查询,以便在新数据文件到达时优先处理它们,同时使用空间集群容量处理旧文件。首先,我们设置选项latestFirst将文件源设置为true,以便首先处理新文件。然后,我们设置maxFilesPerTrigger限制每次要处理的文件数量。这将调整查询以更频繁地更新下游数据仓库,以便尽快提供最新的数据用于查询。一起,我们可以定义rawLogsDataFrame如下:
val rawJson = spark.readStream. schema (cloudTrailSchema).option (“latestFirst”,“真正的”).option (“maxFilesPerTrigger”,“20”). json (“s3n: / / mybucket / AWSLogs / * / CloudTrail / * / 2017/01 / *”)通过这种方式,我们可以编写单个查询,轻松地将实时数据与历史数据结合起来,同时确保低延迟、效率和数据一致性。
Apache Spark中的结构化流是编写流ETL管道的最佳框架,Databricks使其易于在生产环境中大规模运行,如上所述。我们分享了建立流ETL生产管道的基本步骤——提取、转换、加载和最后的查询。我们还讨论并演示了结构化流如何克服在生产环境中解决和设置大容量和低延迟流管道的挑战。
在本系列的后续文章中,我们将介绍如何解决其他障碍,包括:
如果你想了解更多关于结构化流,BOB低频彩这里有一些有用的链接。
您可以尝试使用两台带有自己的AWS CloudTrail日志的笔记本。将笔记本导入Databricks。