


这是第四篇文章由多部分组成的系列如何处理复杂的问题流分析使用Apache Spark。
连续应用程序通常需要对实时聚合统计数据进行近乎实时的决策,例如物联网设备的健康状况和读数,或检测异常行为。在这篇博客中,我们将探讨如何轻松地在结构化流中表示流聚合,以及如何自然地处理延迟和无序的数据。
流媒体聚合
结构化流允许用户表示与批处理查询相同的流查询,Spark SQL引擎会递增查询并在流数据上执行。例如,假设您有一个流DataFrame有来自物联网设备的信号强度事件,并且你想要计算每个设备的运行平均信号强度,那么你将编写以下Python代码:
# DataFrame w/ schema [eventTime: timestamp, deviceId: string, signal: bigint] eventsDF =…avgSignalDF = eventsDF.groupBy("deviceId").avg("signal")如果eventsDF是静态数据上的DataFrame,这段代码也没有什么不同。但是,在这种情况下,随着新事件的到来,平均值将不断更新。你选择不同的输出模式用于将更新后的平均值写入外部系统,如文件系统和数据库。此外,您还可以使用Spark的实现自定义聚合用户定义聚合函数.
事件时间在Windows上的聚合
在许多情况下,不是在整个流上运行聚合,而是希望对按时间窗口划分的数据进行聚合(例如,每5分钟或每小时)。在我们前面的例子中,如果设备开始表现异常,查看最近5分钟的平均信号强度是很有见解的。此外,这5分钟的窗口应该基于嵌入在数据中的时间戳(aka。事件时间),而不是在它被处理的时间(aka。处理时间)。
早期的Spark Streaming DStream API很难表达这样的事件时间窗口,因为API仅设计为处理时间窗口(即数据到达Spark时的窗口)。在结构化流中,在事件时间上表示此类窗口只是使用窗口()函数。例如,事件中的eventTime列上超过5分钟滚动(非重叠)窗口的计数如下所示。
from pyspark.sql.functions import * windowedAvgSignalDF = \ eventsDF \ .groupBy(window("eventTime", "5分钟"))\ .count()在上面的查询中,每个记录将被分配给一个5分钟的滚动窗口,如下所示。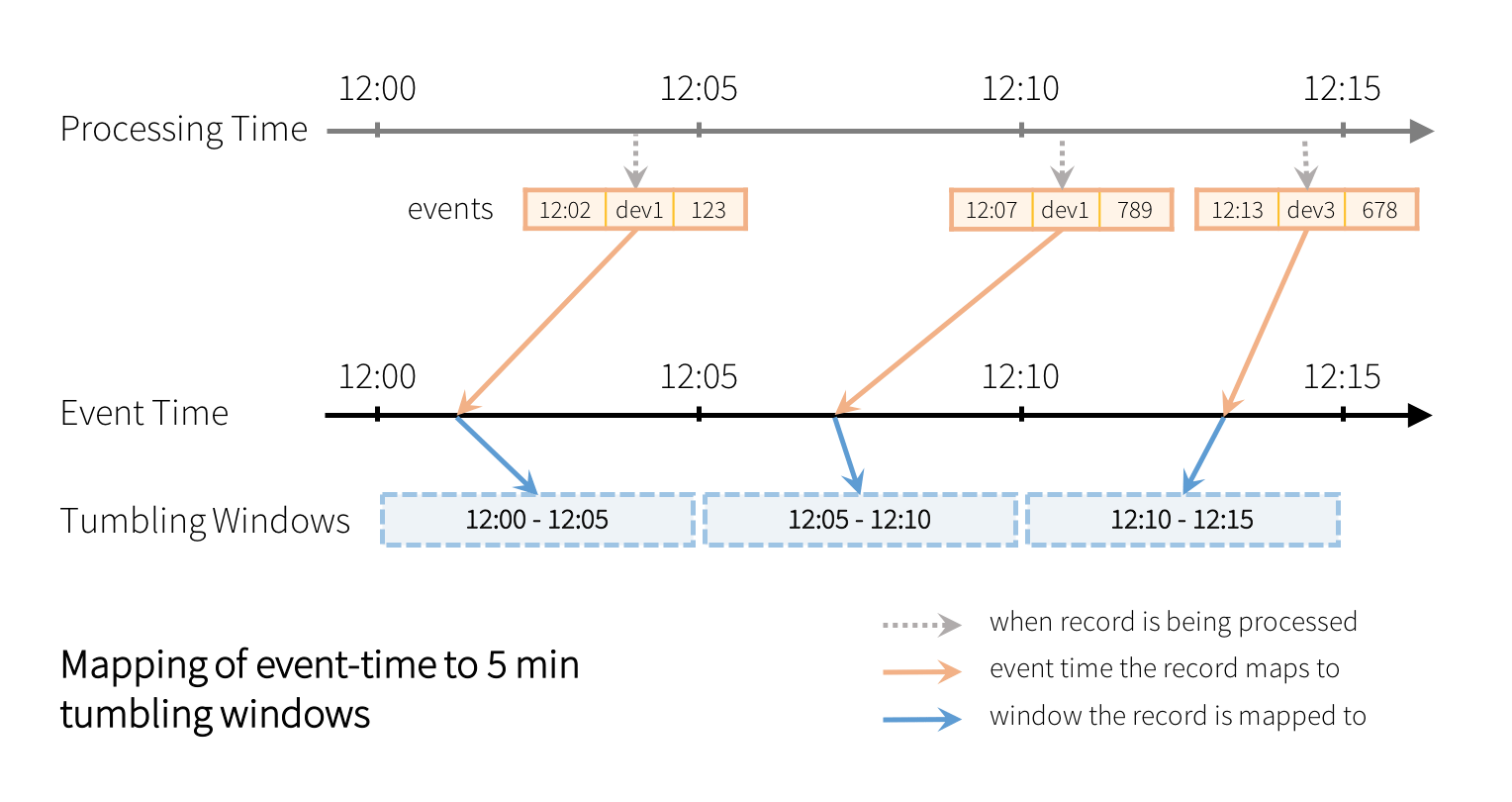
每个窗口都是一个组,为其计算运行计数。还可以通过指定窗口长度和滑动间隔来定义重叠窗口。例如:
from pyspark.sql.functions import * windowedAvgSignalDF = \ eventsDF \ .groupBy(window("eventTime", "10分钟","5分钟"))\ .count()在上面的查询中,每个记录将被分配给多个重叠的窗口,如下所示。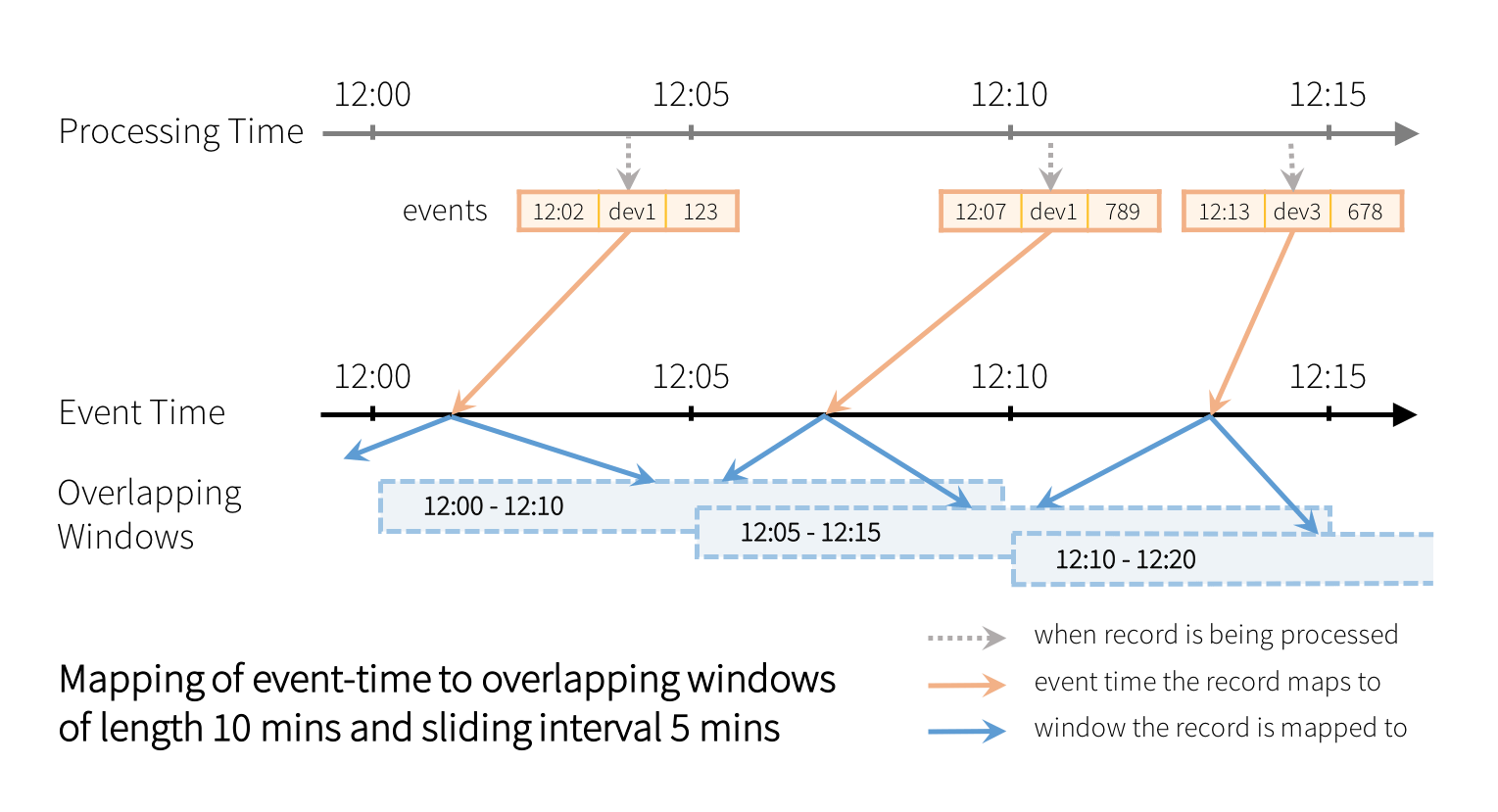
这个分组策略会自动处理延迟和无序的数据——late事件只会更新旧的窗口组而不是最新的窗口组。属性对查询进行分组的端到端说明的deviceId还有重叠的窗户。下面的插图显示了在使用5分钟触发器处理新数据后,当您根据两者进行分组时,查询的最终结果是如何变化的的deviceId滑动窗口(为简洁起见,省略了“signal”字段)。
windowedCountsDF = \ eventsDF \ .groupBy("deviceId", window("eventTime", "10分钟","5分钟"))\ .count()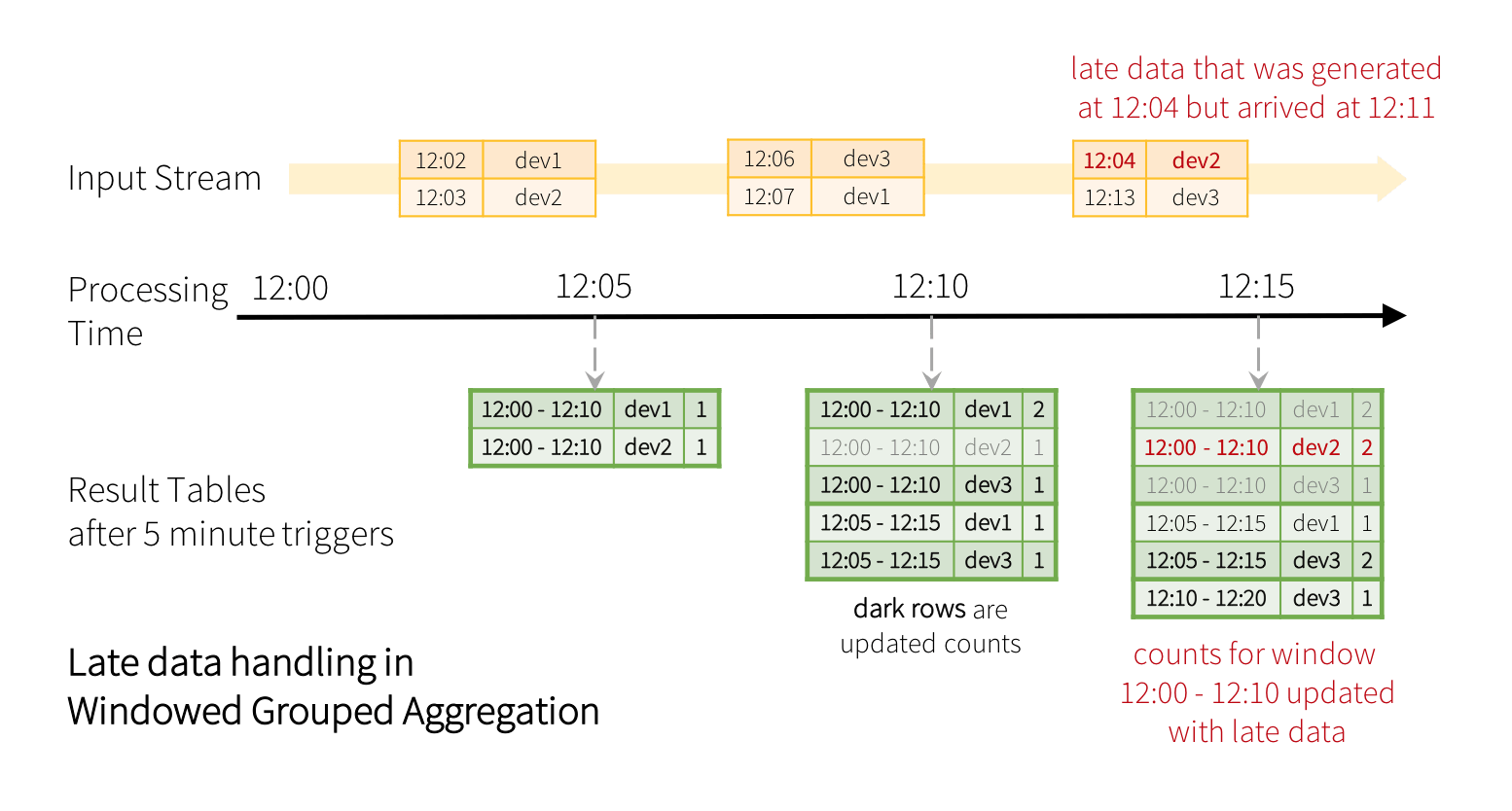
请注意,晚期、无序记录[12:04,dev2]如何更新旧窗口的计数。
有状态增量执行
在执行任何流聚合查询时,Spark SQL引擎在内部将中间聚合维护为容错状态。此状态以键-值对的形式构成,其中键是组,值是中间聚合。这些对存储在内存中,版本控制,键值“状态存储”在Spark执行器中,该执行器是检查点,使用在hdfs兼容的文件系统(在配置检查点位置).在每次触发时,状态都在状态存储区中读取和更新,所有更新都保存到预写日志中。在发生任何失败的情况下,将从检查点信息恢复状态的正确版本,并且从它失败的点开始查询。与可重玩源和幂等接收器一起,结构化流确保了有状态流处理的精确一次保证。
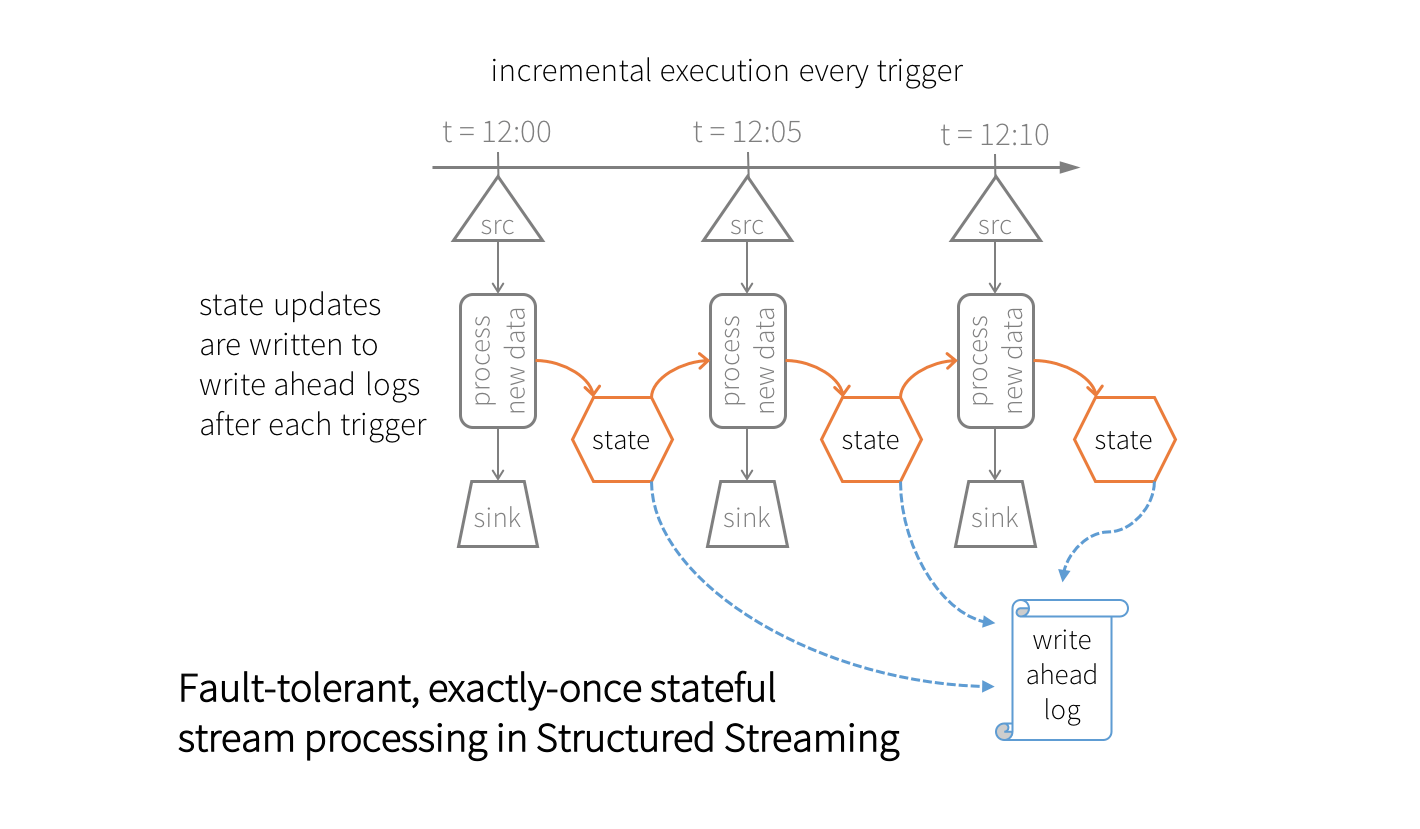
这种容错状态管理自然会引起一些处理开销。为了将这些开销限制在可接受的范围内,状态数据的大小不应该无限增长。然而,使用滑动窗口,窗口/组的数量将无限增长,状态的大小也会无限增长(与组的数量成正比)。为了限制状态大小,我们必须能够删除不再更新的旧聚合,例如7天前的平均值。我们使用水印.
在处理后期数据时限制状态的水印
如前所述,延迟数据的到来可能导致旧窗口的更新。这使得定义哪些旧聚合不会被更新(因此可以从状态存储中删除以限制状态大小)的过程变得复杂。在Apache Spark 2.1中,我们已经介绍了水印这样就可以自动删除旧的状态数据。
水印是事件时间中的一个移动阈值,它落后于处理数据中查询看到的最大事件时间。尾随间隔定义了我们等待延迟数据到达的时间。通过知道给定组中没有更多数据到达的点,我们可以限制查询所需维护的状态总量。以配置的最大延迟时间为10分钟为例。这意味着延迟10分钟以内的事件将被允许聚合。如果观察到的最大事件时间是12:33,那么所有事件时间大于12:23的未来事件都将被认为“太晚”而被丢弃。此外,所有早于12:23的窗口的状态将被清除。您可以根据应用程序的需求设置此参数——该参数的值越大,数据到达的时间就越晚,但代价是增加状态大小,即内存使用量,反之亦然。
这是前面的例子,但是有水印。
windowedCountsDF = \ eventsDF \ .withWatermark("eventTime", "10分钟")\ .groupBy("deviceId", window("eventTime", "10分钟","5分钟"))\ .count()执行此查询时,Spark SQL将自动跟踪eventTime列的最大观测值,并更新水印和清除旧状态。如下图所示。
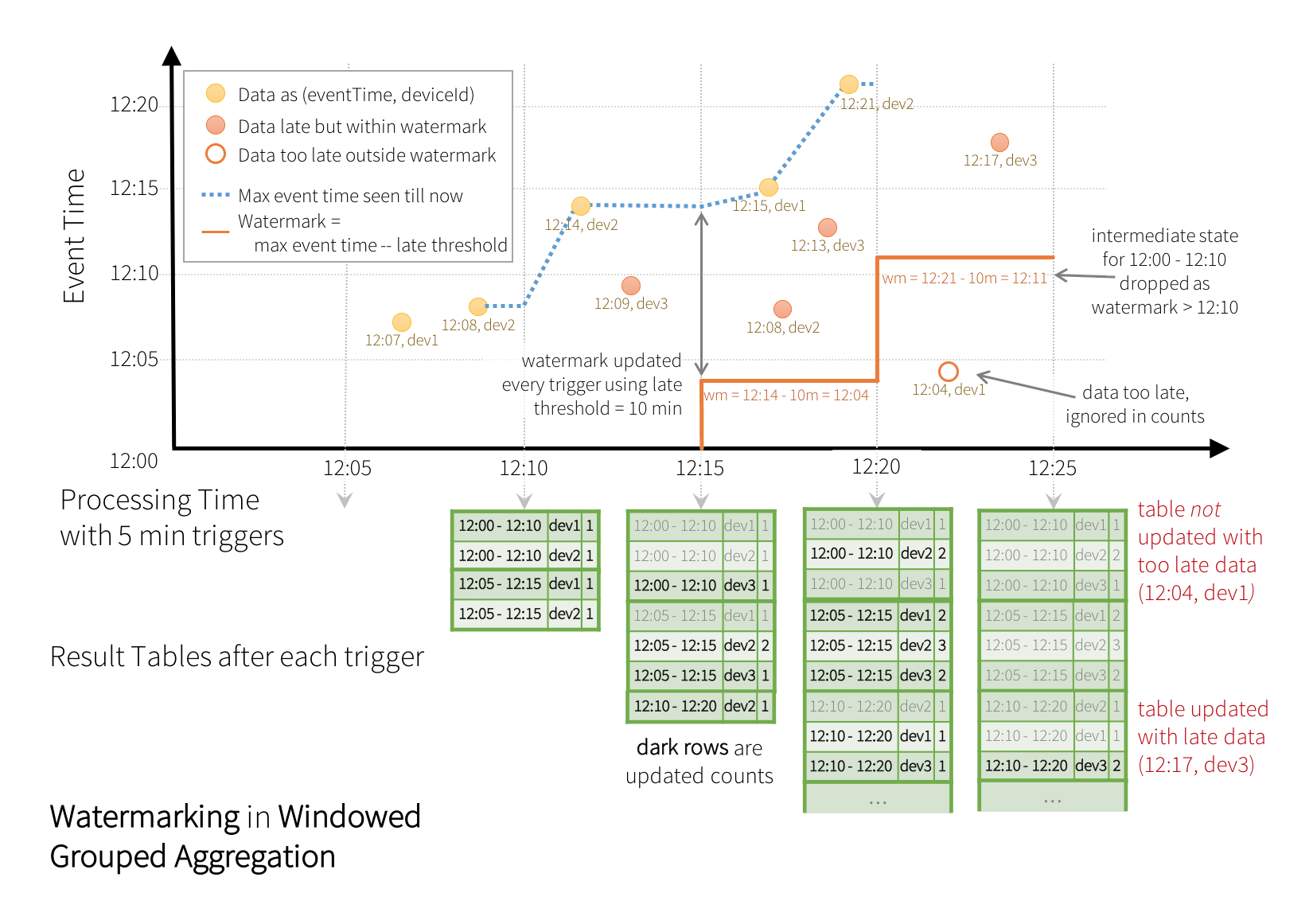
注意在处理时间12:20和12:25之间到达的两个事件。水印用于区分晚事件和“太晚”事件,并相应地处理它们。
结论
简而言之,我介绍了结构化流处理关键流聚合的窗口策略:事件时间上的窗口以及延迟和无序数据。使用这种窗口策略允许结构化流引擎实现水印,其中后期数据可以被丢弃。通过这种设计,我们可以管理状态存储的大小。
在即将到来的Apache Spark 2.2版本中,我们为流式数据帧/数据集添加了更高级的有状态流处理操作。请继续关注本博客系列以获取更多信息。如果您想了解更多关于结构化流的BOB低频彩知识,请阅读我们之前的系列文章。
- Apache Spark中的结构化流
- 实时流ETL与Apache Spark 2.1中的结构化流
- 在Apache Spark 2.1中使用结构化流处理复杂数据格式
- 在Apache Kafka中使用结构化流处理数据
要尝试Apache Spark 2.0中的结构化流,今天就试试Databricks吧.



