


在Apache Spark™上介绍Databricks优化的自动伸缩
Databricks激动地宣布我们新的优化自动缩放功能。新的Apache Spark™感知资源管理器利用Spark洗牌和执行器统计数据来实现…
2018年5月2日 在公司博客上
Databricks激动地宣布我们新的优化自动缩放功能。新的Apache Spark™感知资源管理器利用Spark shuffle和执行器统计数据智能地调整集群大小,提高资源利用率。当我们测试长时间运行的大数据工作负载时,我们发现云计算节省了高达30%的成本。
如今,每个大数据工具都可以自动扩展计算以降低成本。但是,大多数这些工具都期望为单个作业分配静态资源大小,这没有利用云的弹性。像YARN这样的资源调度程序负责不同作业之间的“粗粒度”自动伸缩,只有在Spark作业完成后才释放资源。
/ bin / spark-submit\
——类org.apache.spark.examples.SparkPi\
——主纱\
——deploy-mode集群\#可以是客户端模式
——num-executors 50 \
/ / examples.jar /路径
Spark -submit命令示例,该命令将Spark作业所需的执行器数量作为参数。
这就引出了两个主要问题:
为了克服上述问题,Apache Spark提供了一个动态分配选项在这里.但这需要在同一集群中的每个工作节点上设置一个执行程序外部的shuffle服务,以允许在不删除它们所写的shuffle文件的情况下删除执行程序。虽然可以删除执行程序,但工作节点仍然保持活动状态,以便外部shuffle服务可以继续提供文件。这使得不可能通过减小集群的大小来利用云的弹性。
新的优化的计算资源自动伸缩服务允许集群更积极地根据负载进行伸缩,并自动提高集群资源的利用率,而不需要用户进行任何复杂的设置。
传统的粗粒度自动伸缩算法不能在Spark作业运行时完全缩小分配给该作业的集群资源。主要原因是缺乏有关执行程序使用情况的信息。删除具有活动任务或正在使用的shuffle文件的工作者将触发中间数据的重新尝试和重新计算,这将导致更差的性能,更低的有效利用率,从而为用户带来更高的成本。然而,在集群上只有少量活动任务运行的情况下,例如Spark作业出现倾斜,或者作业的特定阶段对资源的需求较低时,无法扩展将导致较低的利用率,从而为用户带来更高的成本。这对于传统的自动缩放来说是一个巨大的错失机会。
Databricks优化的自动伸缩通过定期报告空闲执行程序和集群中中间文件位置的详细统计数据解决了这个问题。Databricks服务使用这些信息来更精确地定位工作人员,以便在利用率较低时减少工作量。特别是,该服务可以缩小并删除未充分利用的集群上的空闲工作者,即使相同的Spark作业在其他执行器上运行。这种行为与传统的自动伸缩不同,传统的自动伸缩需要完成整个Spark作业才能开始缩小。在缩小过程中,Databricks服务仅在工作对象空闲且不包含运行查询所使用的任何shuffle数据时才会删除它。因此,在降级期间,作业和查询的运行不会受到影响。
由于Databricks可以在低利用率的情况下精确地针对工作人员进行缩小,因此可以更积极地调整集群的大小以响应负载。特别是,在低利用率的情况下,Databricks集群可以大幅缩减没有终止任务或重新计算中间结果。这将浪费的计算资源降至最低,同时还保持了集群的响应性。由于Databricks可以大幅降低集群的规模,因此它也可以扩展集群向上积极响应需求,在不牺牲效率的情况下保持高响应速度。
下面一节将说明在Databricks中运行作业时使用新的自动伸缩特性的行为和优点。
我们有一个基因组数据管道,它定期被安排在自己的集群上作为Databricks作业运行。也就是说,管道的每个实例都会周期性地在Databricks中启动一个集群,运行管道,并在完成后关闭集群。
我们在两个具有相同计算配置的独立集群上运行该管道的相同实例。在这两个实例中,集群都运行Databricks Runtime 4.0,并配置为可扩展到1到24个8核心实例。第一个集群被设置为按传统方式伸缩,在第二个集群中,我们启用了新的Databricks优化的自动伸缩。
下图描绘了部署的执行程序的数量以及随着作业的进行实际使用的执行程序的数量(x轴是时间,单位为分钟)。
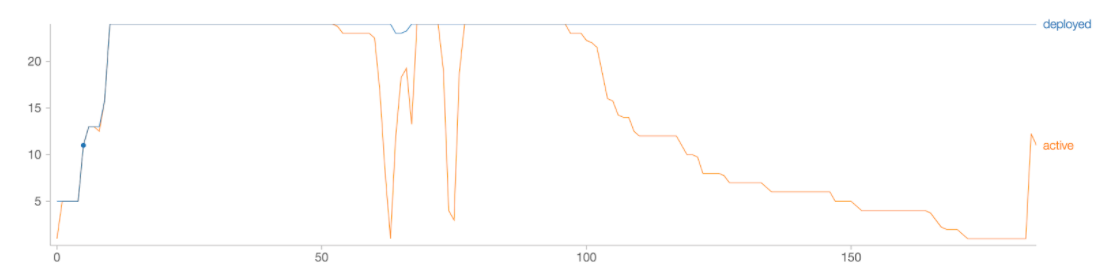
图1。传统的自动伸缩:活动执行器vs全部执行器
显然,部署的工作人员数量只增加到24个,并且在工作负载期间从未减少。也就是说,对于单个Spark作业,传统的自动伸缩并不比简单地分配固定数量的资源好多少。
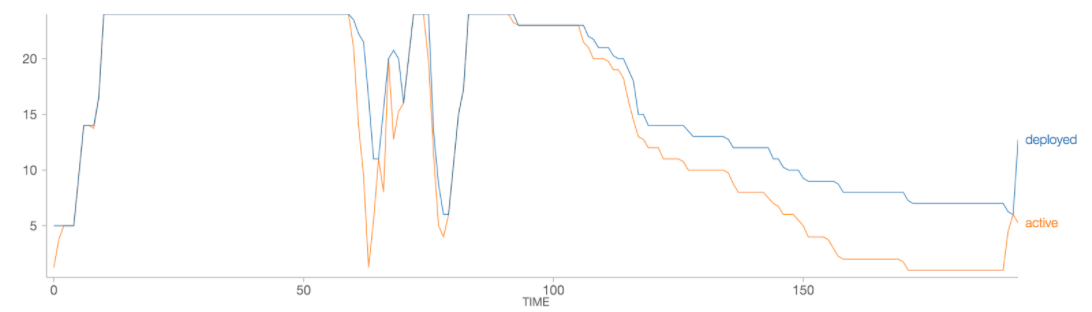
图2。Databricks优化的自动伸缩:活动执行器vs全部执行器
使用Databricks优化的自动伸缩功能,部署工作人员的数量可以更紧密地跟踪工作负载的使用情况。在本例中,优化后的自动伸缩将在工作负载的生命周期内减少25%的资源部署,这意味着为用户节省了25%的成本。工作负载的端到端运行时仅略高(优化自动伸缩后的193分钟vs. 185分钟)。
当您在Databricks Runtime 3.4+集群上运行Databricks作业时,您将获得新的优化的自动伸缩算法,这些集群选择了“启用自动伸缩”标志。请参阅集群大小和自动缩放AWS而且Azure更多信息请参见Databricks文档。
开始在Databricks统一分析平台上运行您的Spark作业,开始节省您的云成本bob体育亚洲版bob体育客户端下载注册一个免费试用.
如果你有任何问题,你可以问如果您有问题,请联系我们.