
新特性MLflow v0.5.2释放


今天,我们很高兴宣布MLflow v0.5.0, MLflow v0.5.1,和MLflow v0.5.2,上周公布了一些新特性。MLflow 0.5.2已经可以在PyPI和文档更新。如果你做pip安装mlflow按照MLflow快速入门指南,你会得到最近的版本。

在这篇文章中,我们将描述这些版本新特性和修复。
Keras PyTorch模型集成
作为MLflow 0.5.2以及持续努力的一部分提供一系列的机器学习框架,我们扩展支持保存和加载Keras PyTorch模型使用log_modelapi。这些模型口味api出口他们的模型在各自的格式,所以Keras或PyTorch应用程序可以重用他们,不仅从本地MLflow但Keras或PyTorch代码。
使用Keras模型api
一旦你已经定义了,训练,和评估Keras模型,您可以记录模型作为MLflow工件的一部分以及导出模型Keras HDF5格式为他人为预测负载或服务。例如,这个Keras片段代码说明:
从keras进口密集,层进口mlflow进口mlflow.keras#构建、编译和训练你的模型keras_model =…keras_model。编译(优化器= rmsprop,损失= mse的指标(“准确性”))结果= keras_model。符合(x_train、y_train时代=20.batch_size =128年validation_data = (x_val y_val))…#对数指标和模型与mlflow.start_run ()作为运行:…mlflow.keras。log_model(keras_model, “keras-model”)#加载模型Keras模型或pyfunc和利用其预测()方法
keras_model = mlflow.keras。load_model (“keras-model run_id =“96771 d893a5e46159d9f3b49bf9013e2”)预测= keras_model.predict (x_test)…使用PyTorch模型api
类似地,您可以使用该模型api在PyTorch对数模型,。例如,下面的代码片段PyTorch很相似,与小变化PyTorch公开其方法。然而,随着pyfunc方法都是一样的:预测():
进口mlflow进口mlflow.pytorch进口火炬#构建、编译和训练你的模型pytorch_model =…pytorch_model.train ()pytorch_model。eval()…y_pred = pytorch_model.model (x_data)#对数指标和模型与mlflow.start_run ()作为运行:…mlflow.pytorch。log_model(pytorch_model, “pytorch-model”)#加载模型pytorch模型或pyfunc和利用其预测()方法
pytorch_model = mlflow.pytorch.load_model (“pytorch-model”)y_predictions = pytorch_model.model (x_test)Python api用于实验和运行管理
查询过去的运行和实验中,我们添加了新的公共api的一部分mlflow.tracking模块。在这个过程中,我们也重构旧的apimlflow模块记录当前运行参数和指标。例如,记录当前运行的基本参数和指标,可以使用mlflow.log_xxxx ()调用。
进口mlflow…与mflow.start_run ()作为运行:mlflow.log_param(“游戏”,1)mlflow.log_metric(“分数”,25)…然而,访问这个运行的结果,说在另一个应用程序的一部分,您可以使用mflow.trackingapi是这样的:
进口mlflow.tracking#让服务;默认本地URI或从“mlruns”run_uuid = ' 96771 d893a5e46159d9f3b49bf9013e2”运行= mlflow.tracking.get_service () .get_run (run_uuid)分数= run.data.metrics [0]前者处理坚持指标、参数和工件当前活动来看,后者允许管理实验和运行(尤其是历史运行)。
有了这个新的api,开发者可以访问Python CRUD接口MLflow实验和运行。因为它是一个低级的API,它地图REST调用。这样你可以在你的实验运行构建基于rest的服务。
UI的改进来比较
由于卡通Baeyens (问题# 268@ToonKBC)MFlow跟踪界面我们可以比较两个运行一个散点图。例如,这张图片显示了大量的树木和其相应的rmse度量。
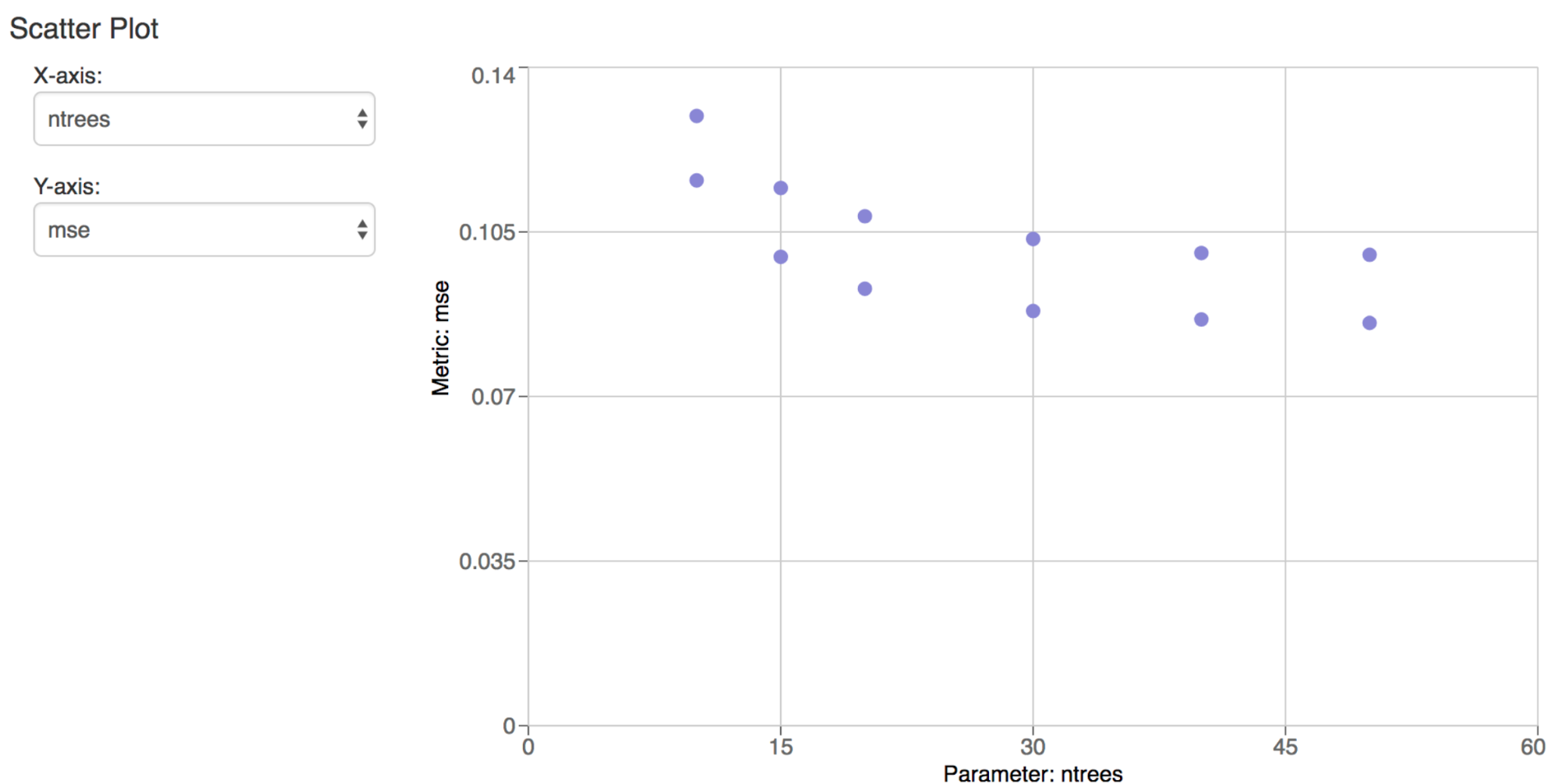
同时,柱状和板状表示和组织实验运行,度量,和参数,您可以很容易地想象结果和比较。面包屑导航,整个遇到更好的UI体验。
其他功能和错误修正
除了这些特性外,其他物品,修复bug和文档都包含在这个版本。有些东西值得注意的是:
- (Sagemaker)用户可以指定一个自定义VPC当部署Sagemaker模型(# 304,@dbczumar)
- (工件)SFTP artifactory商店添加(# 260,@ToonKBC)
- [Pyfunc] Pyfunc序列化现在包括Python版本和警告说如果主版本(可以抑制使用不同
load_pyfunc (suppress_warnings = True))@dbczumar (# 230) - [Pyfunc] Pyfunc服务/预测将激活储存在MLModel conda环境。这可以通过添加禁用
——no-conda来mlflow pyfunc服务或mlflow pyfunc预测@0wu (# 225) - (CLI)
mlflow运行现在可以运行在项目没有conda.yaml指定。默认情况下,将创建一个空conda环境——以前,它就会失败。你仍然可以通过——no-conda为了避免进入conda环境完全(# 218,@smurching) - 修复mlflow.start_run()实际运行设置为创建跑(在此之前,没有一个)(# 322,@tomasatdatabricks)
- [许多]修复DBFS artifactory抛出一个异常,如果日志工件失败(# 309)和模拟FileStore的行为日志目录(# 347,@andrewmchen)
- [许多]修复火花。load_model不删除DFS tempdir (# 335, @aarondav)
- [许多]使Python API兼容性与更新的服务器版本的原型(# 348,@aarondav)
- [许多]修复一个缺陷与ECR客户创建导致
mlflow.sagemaker.deploy ()失败时寻找一个部署码头工人形象(# 366,@dbczumar) - (UI)改进的API文档(# 305,# 284,@smurching)
变化的完整列表和贡献的社区中可以找到0.5.2更新日志。我们欢迎更多的输入(电子邮件保护)或通过申请的问题或提交补丁在GitHub上。关于MLflow实时问题,我们最近还创建了一个松弛的通道对于MLflow以及可以效仿@MLflow在Twitter上。
学分
MLflow 0.5.2包括补丁、bug修复和医生从亚伦戴维森,阿德里安壮族,亚历克斯·亚当森,安德鲁·陈酿成Murdopo,科里Zumar,朱尔斯Damji,马泰Zaharia @RBang1,哈斯默奇,斯蒂芬妮Bodoff,托马斯Nykodym, Tingfan Wu卡通Baeyens, Yassine Alouini。