
新特性MLflow v0.6.0


今天,我们很高兴宣布MLflow v0.6.0在本周早些时候发布新特性。现在可以在PyPI和Maven,文档更新。你可以安装最近发布的pip安装mlflow中描述的那样MLflow快速入门指南。

MLflow v0.6.0介绍一些主要的特点:
在这篇文章中,我们将描述新功能,增强,并在这个版本错误修复。特别是,我们将关注两个特性:一个新的Java MLflow客户机API和火花MLlib MLeap模型集成。
Java客户机API
给开发人员一个编程语言的选择,包括Java客户机跟踪API类似的功能Python客户机跟踪API。两者都提供CRUD接口MLflow实验和运行。这个Java客户机上可用Maven。
通过主要的Java类的构造函数MlflowClient ()和它的实例方法,创建列表,删除日志或访问运行及其构件。默认情况下,它连接到跟踪服务器设置的环境变量MLFLOW_TRACKING_URI,除非显式实例化MlflowClient (tracking_server_ui)构造函数。
如果你使用了新的MLflow Python API跟踪和实验,介绍了MLflow v0.5.2,它在功能上没有区别。像往常一样,一些代码片段将说明其用法。一个完整的示例,可以在示例Java客户端源代码的目录:QuickStartDriver.java
进口java.util。列表;进口java.util。可选;进口org.apache.log4j.Level;进口org.apache.log4j.LogManager;进口org.mlflow.api.proto.Service。*;进口org.mlflow.tracking.MlflowClient;
/ * **这是一个示例应用程序使用MLflow跟踪API来创建和管理*实验和运行。* /公共类QuickStartDriver{公共静态无效主要(String[]参数)抛出异常{(新QuickStartDriver ())。过程(arg游戏);}无效过程(String[]参数)抛出异常{MlflowClient客户端;如果(arg游戏。长度exp = client.listExperiments ();System.out.println (“#实验:”+ exps.size ());exps.forEach (e - > System.out.println (“妳”+ e));/ /创建一个新的实验createRun (客户端,expId);System.out.println (“= = = = = =再getExperiment”);GetExperiment。响应exp2 = client.getExperiment (expId);System.out.println (”getExperiment:“+ exp2);System.out.println (“= = = = = = getExperiment的名字”);可选<实验> exp3 = client.getExperimentByName (expName);System.out.println (”getExperimentByName:“+ exp3);}空白createRun (expId MlflowClient客户,长){System.out.println (“= = = = = = createRun”);/ /创建运行字符串源文件=“MyFile.java”;RunInfo runCreated = client.createRun (expId,源文件);System.out.println (”CreateRun:“+ runCreated);字符串runId = runCreated.getRunUuid ();/ /日志参数client.logParam (runId,“min_samples_leaf”,“2”);client.logParam (runId,“max_depth”,“3”);/ /日志指标client.logMetric (runId,“auc”,2.12F);client.logMetric (runId,“accuracy_score”,3.12F);client.logMetric (runId,“zero_one_loss”,4.12F);/ /更新完成client.setTerminated (runId, RunStatus.FINISHED);/ /运行的细节运行运行= client.getRun (runId);System.out.println (”GetRun:“+运行);}}> < /实验火花MLlib MLeap模型集成
真正MLflow设计目标的“开放平台”,支持流行的口味毫升库和模型,我们添加了另一个bob体育客户端下载模型的味道:mlflow.mleap。可以选择保存在火花MLlib模型MLeap格式。这个新的MLeap格式允许部署火花MLlib模型低延迟生产服务。
实时服务的MLeap框架的性能远高于火花MLlib原因很多。首先,它使用较轻的重量,高性能DataFrame表示。第二,与火花MLlib管道模型不同,它不需要SparkContext同时评估MLlib管道在Scala中。最后,它已序列化和反序列化机制将PySpark管道模型转换为Scala对象。
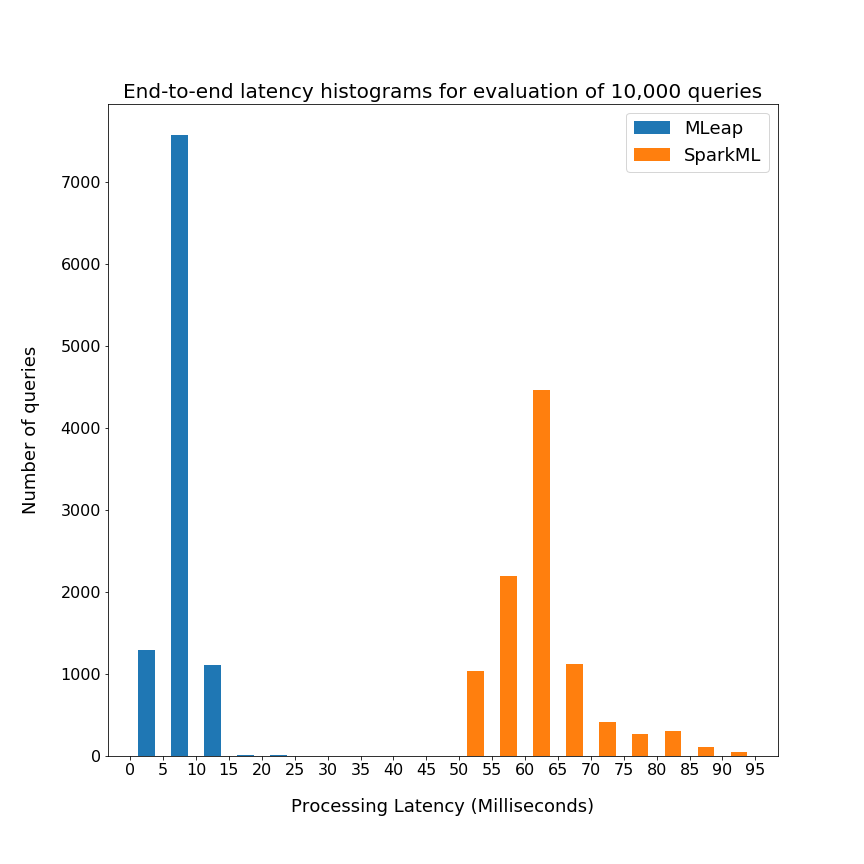
从上面的图中,您可以看到MLeap可以预测在个位数毫秒范围,而火花MLlib达到100 -毫秒范围。
储蓄火花MLib模型MLeap味道
对于这个功能,我们已经延长了mlflow.sparkAPI的save_model (…)选择保存火花MLib MLeap格式的模型,给你选择部署实时服务的性能模型。一个例子将说明如何拯救这个模型在两种格式。
让我们创建一个简单的火花MLlib模型、对数模型、一些参数,存在火花MLlib和MLeap模型格式。一个额外的参数mlflow.spark.save_model (…)将坚持两种格式:火花MLlib MLeap。
进口mlflow进口mlflow.spark从pyspark.ml进口管道从pyspark.ml.classification进口LogisticRegression从pyspark.ml.feature进口HashingTF,记号赋予器#训练DataFrame培训= spark.createDataFrame ([(0,“一个b c d e火花”,1.0),(1,“b d”,0.0),(2,“火花f g h”,1.0),(3,“hadoop mapreduce”,0.0)]、[“id”,“文本”,“标签”])##测试DataFrametest_df = spark.createDataFrame ([(4,“我火花j k”),(5,“l m n”),(6,“火花hadoop火花”),(7,“apache hadoop”)]、[“id”,“文本”])#创建一个MLlib管道记号赋予器=记号赋予器(inputCol =“文本”outputCol =“单词”)hashingTF = hashingTF (inputCol = tokenizer.getOutputCol (), outputCol =“特征”)lr = LogisticRegression(麦克斯特=10regParam =0.001)管道=管道(阶段=(记号赋予器、hashingTF lr))模型= pipeline.fit(培训)#日志参数mlflow.log_parameter (“max_iter”,10)mlflow.log_parameter (“reg_param”,0.001)#日志mleap格式的模型mlflow.mleap。log_model(模型、test_df“mleap-model”)#这个调用添加test_df参数将节省#在这两种格式。#现在让我们坚持它。这个API调用将节省两种口味#模型:火花MLlib MLeap,都可以使用#在部署pyfunc电话,如果我们提供MLeap味道#参数,如DataFrame输入,它将保存风味
mlflow.spark。save_model(模型、test_df“mleap_models”)其他功能和错误修正
除了这些特性外,其他物品,修复bug和文档都包含在这个版本。有些东西值得注意的是:
- (API)支持与元数据标记运行,在运行过程中和结束后,完成
- (API)实验通过REST API现在可以删除和恢复,Python跟踪API和MLflow CLI (# 340, # 344, # 367, @mparkhe)
- (API)添加list_artifacts和download_artifacts MlflowService与运行的artifactory (# 350, @andrewmchen)
- (API)添加get_experiment_by_name Python跟踪API,并相当于Java API (# 373, @vfdev-5)
- [API / Python]现在版本是通过mlflow暴露。版本。
- (API / CLI) mlflow工件CLI添加到列表,下载,上传工件运行库(# 391,@aarondav)
* (API / CLI) mlflow工件CLI添加到列表,下载,上传工件运行库(# 391,@aarondav) - (API)添加get_experiment_by_name Python跟踪API,并相当于Java API (# 373, @vfdev-5)
- [服务/ SageMaker] SageMaker服务以一个AWS地区参数(# 366,@dbczumar)
- (UI)添加图标源名称MLflow实验UI (# 381, @andrewmchen)
- [医生]添加综合的例子做一个多步骤的工作流,链接MLflow一起运行和重用结果(# 338,@aarondav)
- (文档)添加综合的例子做hyperparameter调优(# 368,@tomasatdatabricks)
- (文档)增加mlflow代码示例。@dmatrix keras API (# 341)
- (文档)显著改善到Python API文档(# 454,@stbof)
- [医生]示例文件夹重构来提高可读性。现在居住在示例的示例/相反的例子,太(# 399,@mparkhe)
变化的完整列表和贡献的社区中可以找到0.6.0更新日志。我们欢迎更多的输入(电子邮件保护)或通过申请的问题或提交补丁在GitHub上。关于MLflow实时问题,我们有一个松弛的通道对于MLflow以及可以效仿@MLflow在Twitter上。
阅读更多
为我们下一步工作的概述,看看路线图幻灯片我们的演讲。
学分
MLflow 0.6.0包括补丁、bug修复和医生改变从亚伦·戴维森,阿德里安壮族,亚历克斯·亚当森,安德鲁·陈科里Zumar, Hamroune查希尔,欢乐Gioa, Jules Damji Krishna Sangeeth马泰Zaharia哈斯默奇,Shenggan,斯蒂芬妮Bodoff,托马斯Nykodym,卡通Baeyens, VFDev。