

理解动态时间扭曲
使用动态时间翘曲和MLflow检测销售趋势系列的第1部分


2019年4月30日 在工程的博客
这篇博客是我们两部分系列文章的第一部分使用动态时间翘曲和MLflow检测销售趋势。若要转到第2部分,请转到使用动态时间翘曲和MLflow检测销售趋势。
“动态时间扭曲”这个词,乍一读,可能会让人联想到马蒂·麦克弗莱(Marty McFly)驾驶着他的德罗宁(DeLorean)以88英里/小时的速度行驶在纽约回到未来系列。唉,动态时间扭曲并不涉及时间旅行;相反,它是一种用于在比较数据点之间的时间指数不能完美同步时动态比较时间序列数据的技术。
正如我们将在下面探讨的那样,动态时间扭曲最突出的用途之一是在语音识别中-确定一个短语是否与另一个短语匹配,即使这个短语说得比它的比较快或慢。你可以想象,这在识别用于激活谷歌Home或亚马逊Alexa设备的“唤醒词”时很方便——即使你的说话速度很慢,因为你还没有喝每天的一杯咖啡。
动态时间翘曲是一种有用的、功能强大的技术,可以应用于许多不同的领域。一旦理解了动态时间扭曲的概念,就很容易看到它在日常生活中的应用实例,以及它令人兴奋的未来应用。考虑以下用途:
- 金融市场-比较相似时间范围内的股票交易数据,即使它们并不完全匹配。例如,比较2月(28天)和3月(31天)的月度交易数据。
- 可穿戴健身追踪器-更准确地计算步行者的速度和步数,即使他们的速度随时间变化。
- 路径计算-如果我们了解司机的驾驶习惯(例如,他们在直道上开得很快,但左转的时间比平均时间要长),就可以计算出更准确的司机的预计到达时间。
数据科学家、数据分析师和任何与时间序列数据打交道的人都应该熟悉这种技术,因为完全对齐的时间序列比较数据与完全“整齐”的数据一样罕见。
在本系列博客中,我们将探讨:
- 动态时间翘曲的基本原理
- 对采样音频数据进行动态时间扭曲
- 使用MLflow对样例销售数据运行动态时间扭曲
动态时间翘曲
时间序列比较方法的目的是产生一个距离度量在两个输入时间序列之间。两个时间序列的相似性或不相似性通常是通过将数据转换为向量并计算向量空间中这些点之间的欧氏距离来计算的。
动态时间翘曲是一种开创性的时间序列比较技术,自20世纪70年代以来一直以声波为源用于语音和单词识别;一篇经常被引用的论文是基于有序图搜索技术的动态时间翘曲孤立词识别。
背景
这种技术不仅可以用于模式匹配,还可以用于异常检测(例如,在两个不相交的时间段之间重叠时间序列,以了解形状是否发生了显著变化,或检查异常值)。例如,当查看下图中的红色和蓝色线时,请注意传统的时间序列匹配(即欧几里得匹配)具有极大的限制性。另一方面,动态时间翘曲允许两条曲线均匀匹配,即使x轴(即时间)不一定同步。另一种方法是将其视为一个稳健的不相似分,其中数字越低意味着序列越相似。
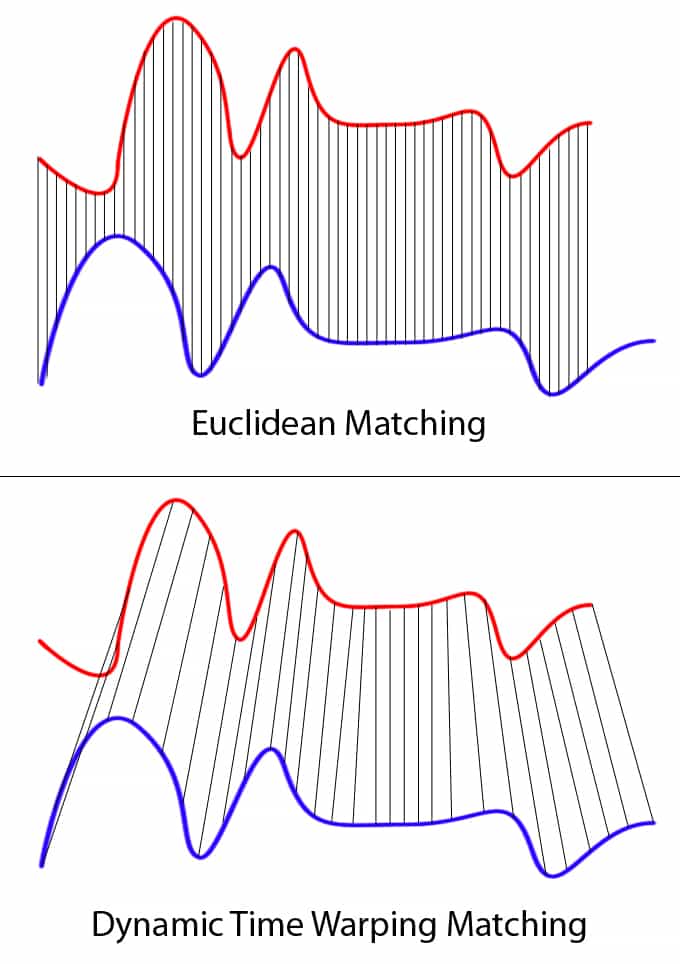
来源:维基共享资源:文件:Euclidean_vs_DTW.jpg
当两个时间序列(基本时间序列和新时间序列)可以根据以下规则与函数f(x)进行映射,以便使用最优(扭曲)路径匹配幅度时,则认为它们相似。
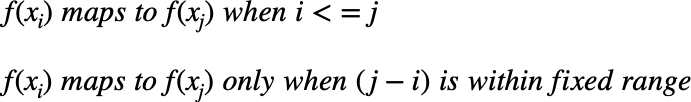
声音模式匹配
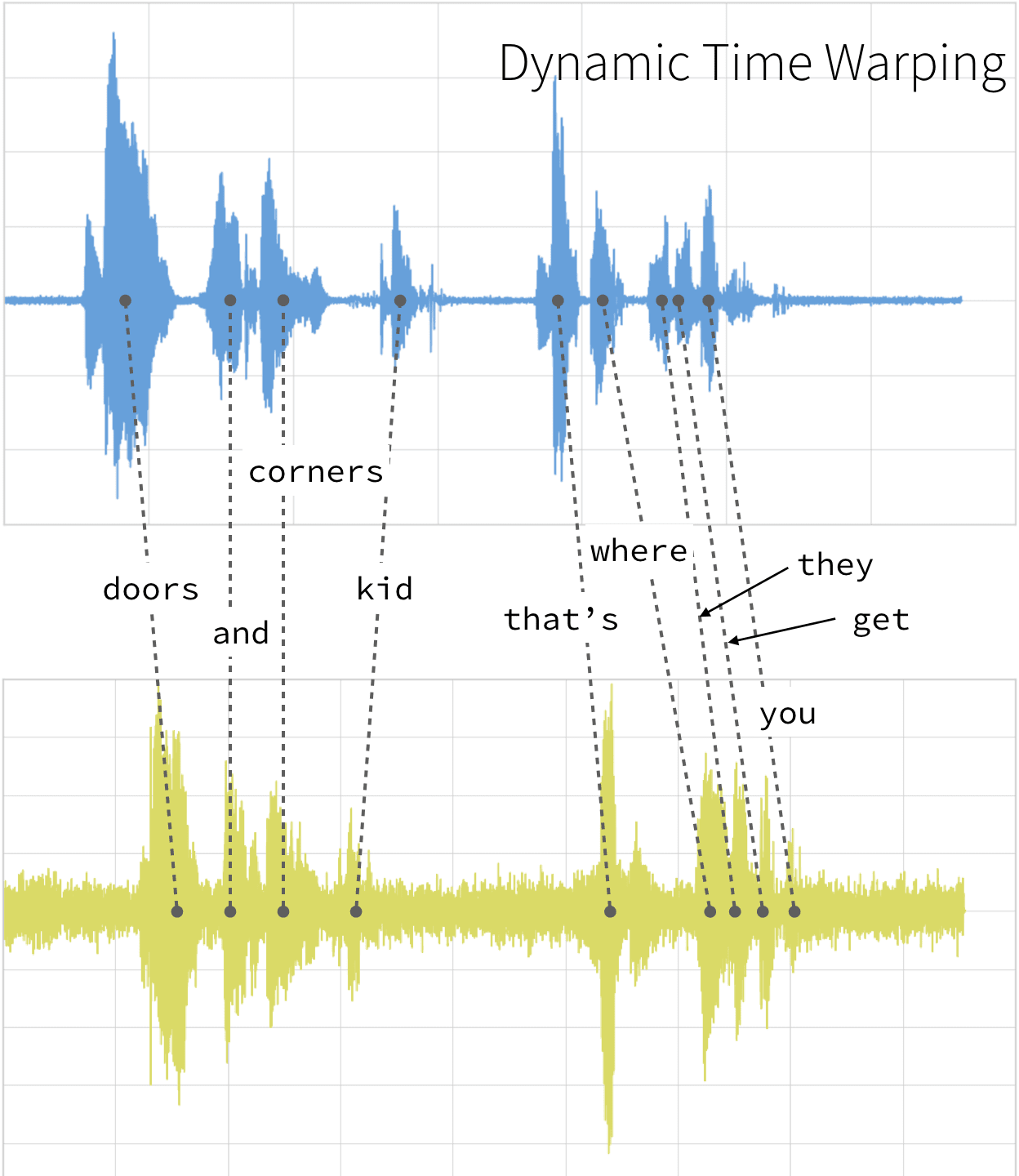
传统上,动态时间翘曲应用于音频剪辑,以确定这些剪辑的相似性。在我们的例子中,我们将使用四个不同的音频剪辑,这些音频剪辑基于一个名为宽阔的。有四个音频片段(你可以在下面听,但这不是必须的)-其中三个(剪辑1、2和4)是基于引用的:
“门和角落,孩子。这就是他们找你的地方。”
其中一个片段(片段3)是引用
“你走得太快,房间就会把你吃掉。”
门与角,孩子。 这就是他们找你的地方。(v1) |
门与角,孩子。 这就是他们找你的地方。(v2) |
你走进房间太快了, 房间吃了你。 |
门与角,孩子。 这就是他们给你的[v3] |
引用来自宽阔的
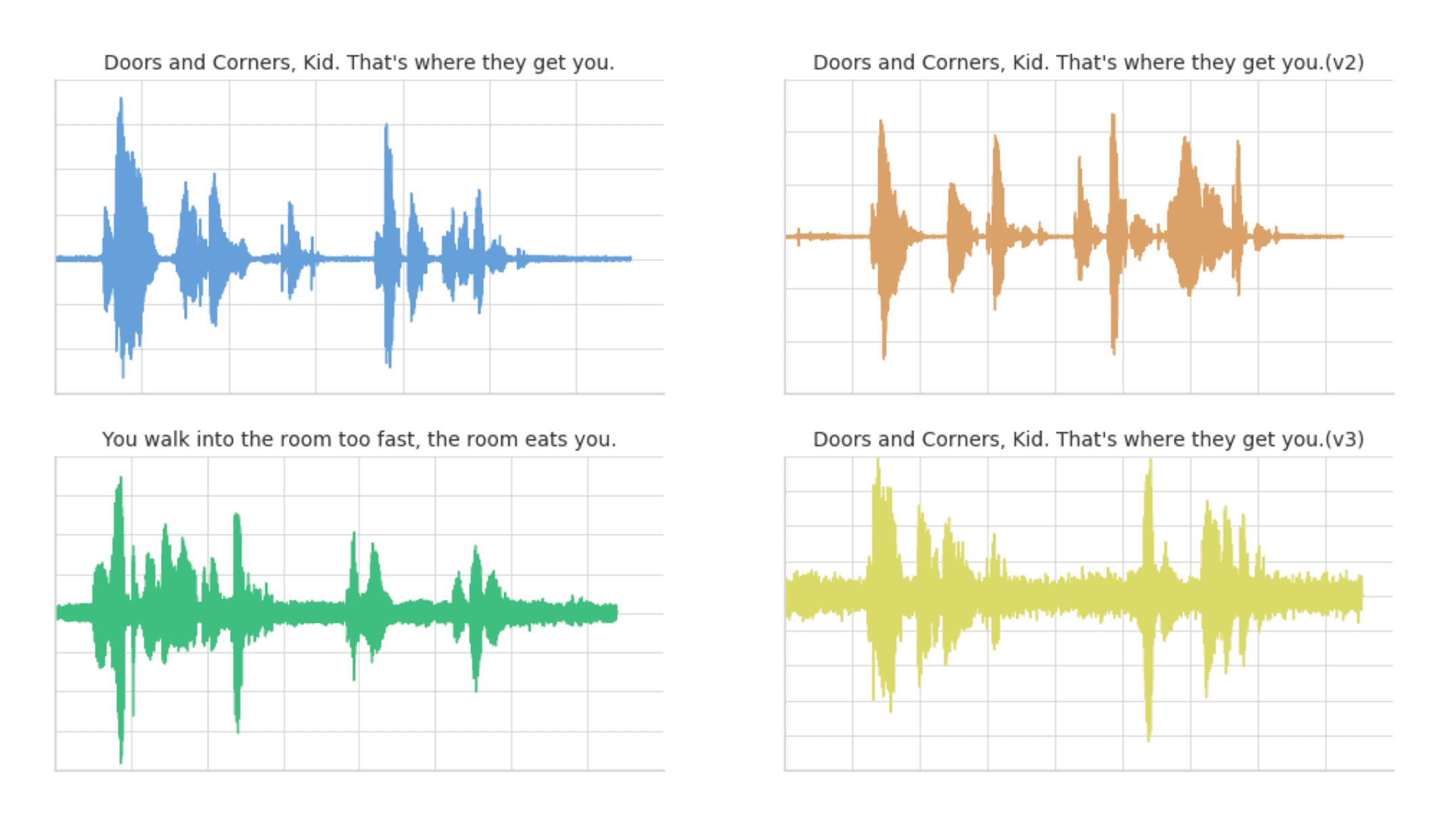
下面是可视化使用matplotlib在四个音频片段中:
- 夹1:这是我们的基准时间序列,基于引用“门和角落,孩子。这就是他们要找你的地方。”。
- 片段2:这是一个基于剪辑1的新的时间序列[v2],其中语调和语音模式被极度夸张。
- 片段3:这是另一个基于引文的时间序列“你走得太快,房间就会把你吃掉。”用与片段1相同的语调和速度。
- 剪辑4:这是基于剪辑1的一个新的时间序列[v3],语调和语音模式与剪辑1相似。
下面的代码片段总结了读取这些音频片段并使用matplotlib将其可视化的代码。
从scipy.io进口wavfile从matplotlib进口pyplot作为plt从matplotlib.pyplot进口数字#读取存储的音频文件进行比较Fs, data = wavfile.read(“dbfs /文件夹/ clip1.wav”)设定剧情风格plt.style.use (“seaborn-whitegrid”)#创建子图Ax = plt.subplot(2,2,1)斧子。情节(data1、颜色=“# 67 a0da”)...#显示创建的图形无花果= plt.show ()显示(图)完整的代码库可以在笔记本中找到动态时间扭曲背景。
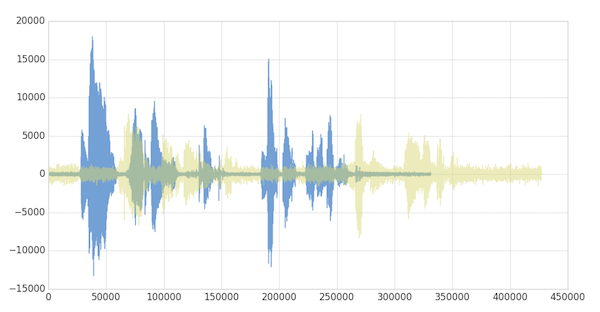
如下所述,当两个剪辑(在本例中,剪辑1和4)对同一引用具有不同的语调(振幅)和延迟时。
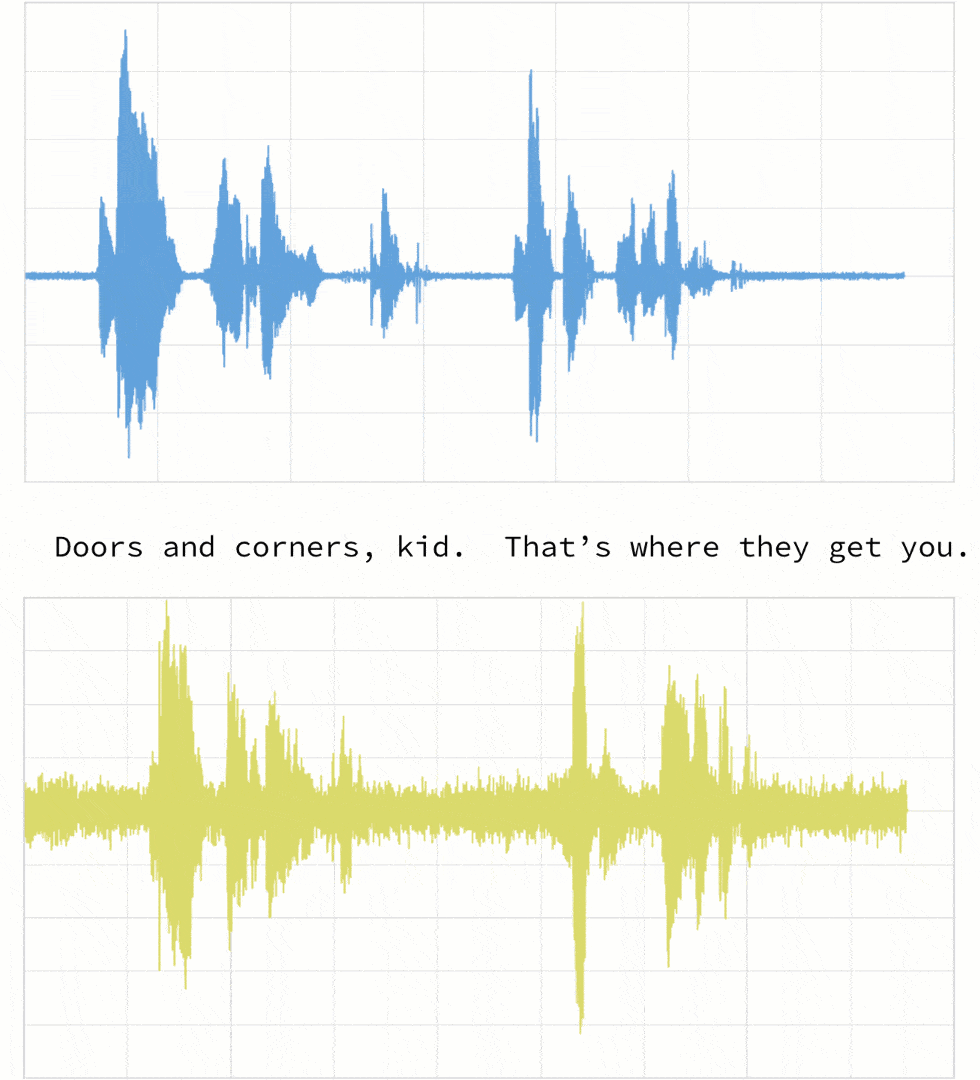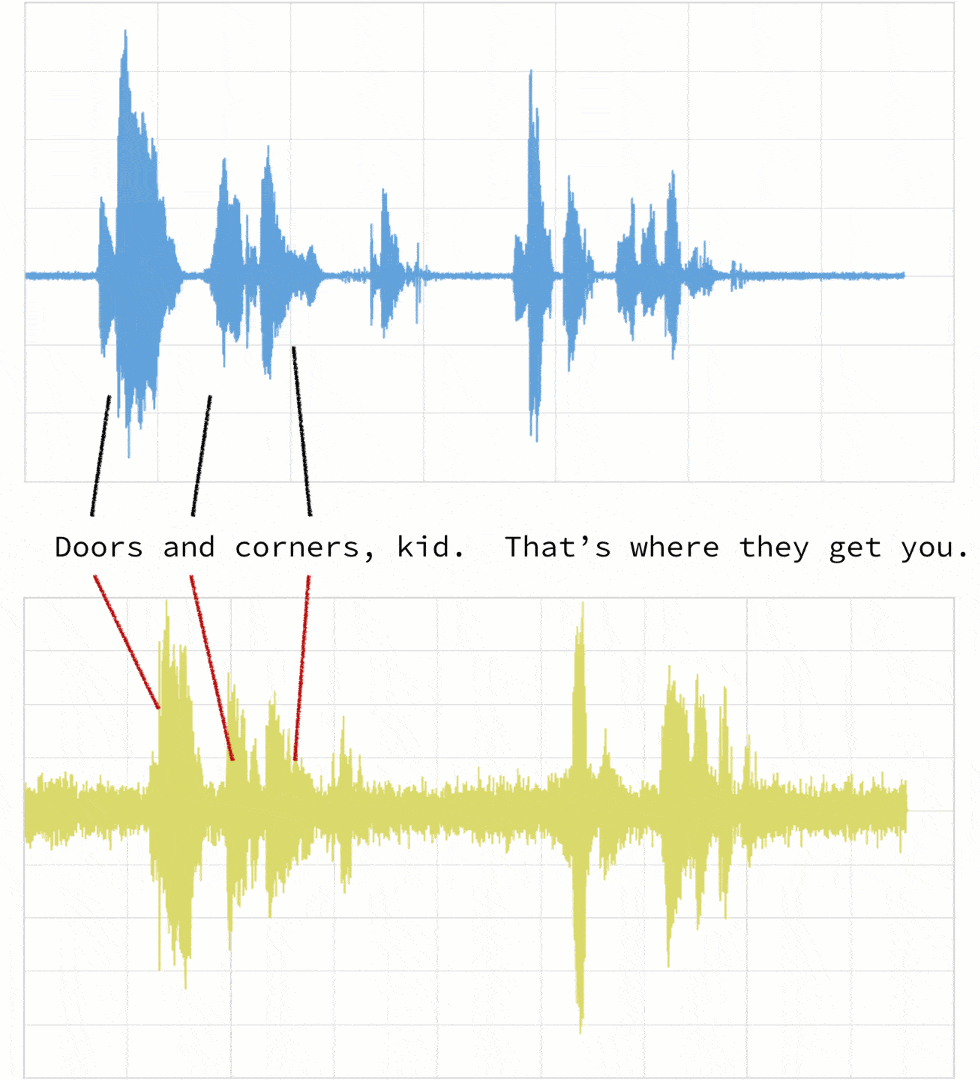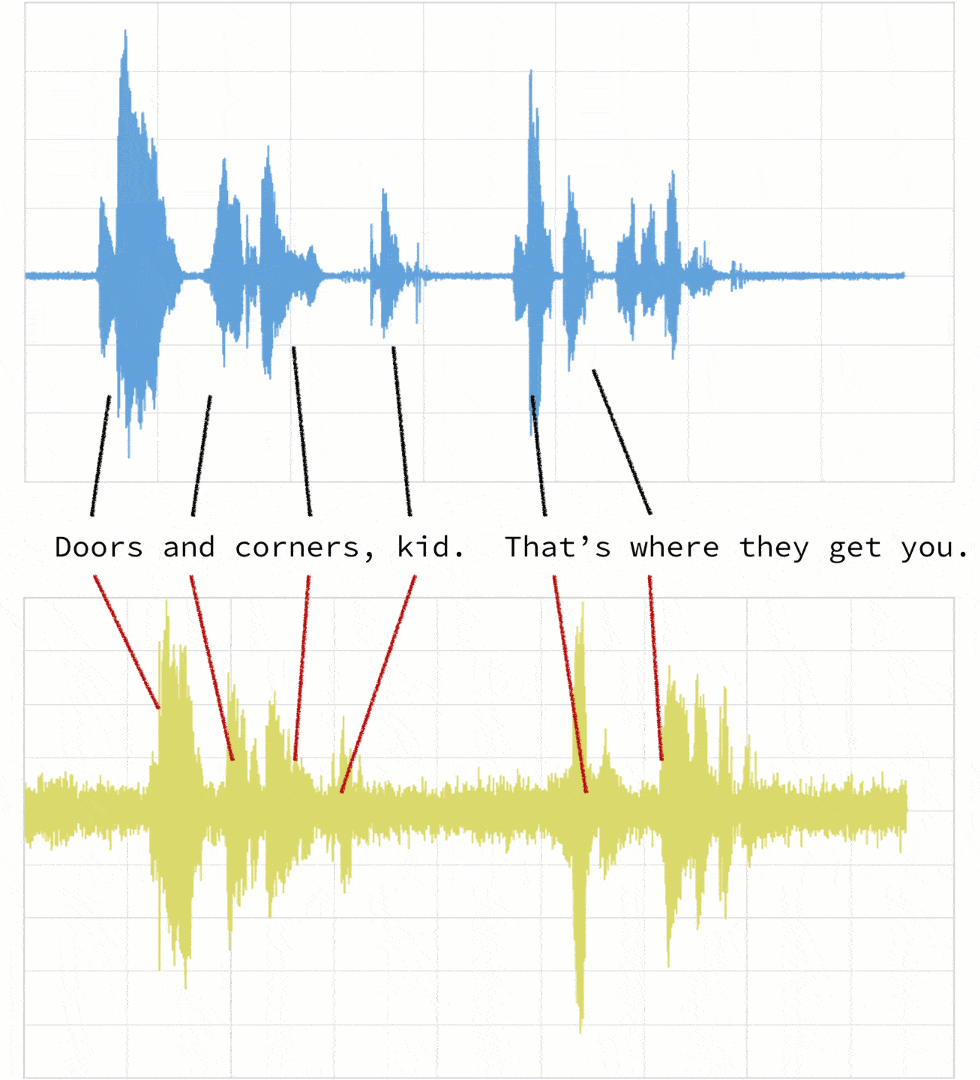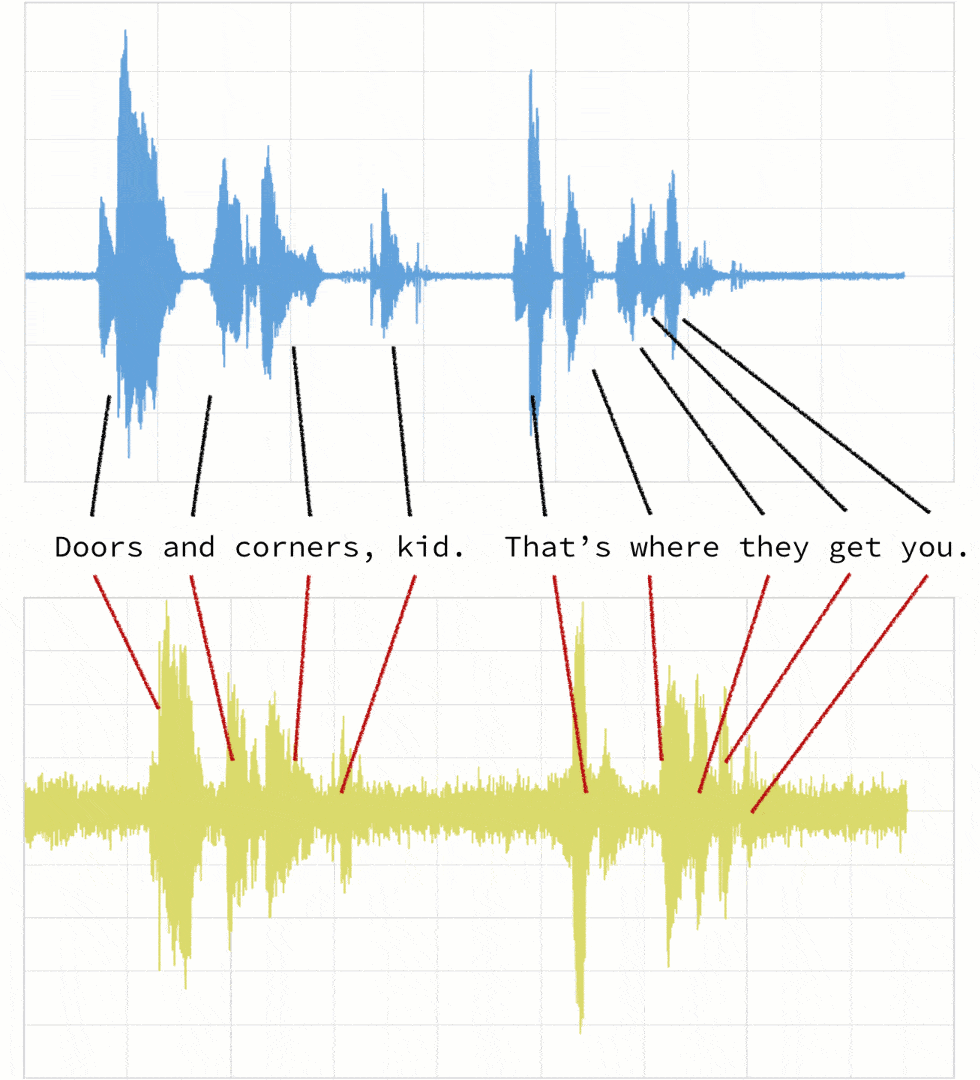
如果我们遵循传统的欧几里得匹配(如下图所示),即使我们对振幅进行折现,原始剪辑(蓝色)和新剪辑(黄色)之间的时间不匹配。
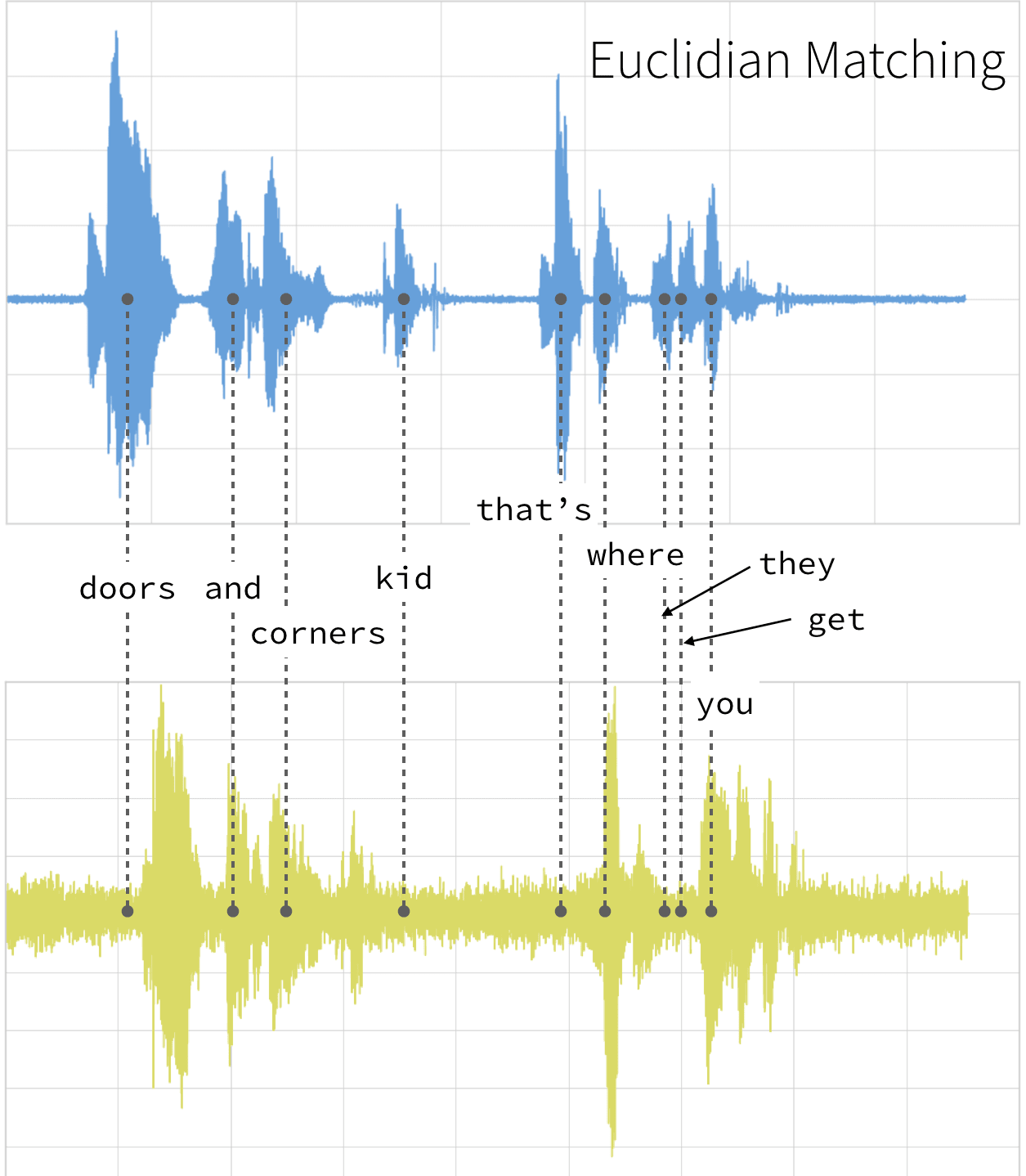
使用动态时间扭曲,我们可以改变时间,以便在这两个剪辑之间进行时间序列比较。
对于我们的时间序列比较,我们将使用fastdtwPyPi库;在Databricks工作区中安装PyPi库的说明可以在这里找到:Azure|AWS。通过fastdtw,我们可以快速计算出不同时间序列之间的距离。
从fastdtw进口fastdtw#剪辑1和剪辑2之间的距离距离= fastdtw(data_clip1, data_clip2)[0]打印(“两个夹子之间的距离是%s " %距离)完整的代码库可以在笔记本中找到动态时间扭曲背景。
| 基地 | 查询 | 距离 |
|---|---|---|
| 夹1 | 片段2 | 480148446.0 |
| 片段3 | 310038909.0 | |
| 剪辑4 | 293547478.0 |
一些简单的观察:
- 如上图所示,片段1和4的距离最短,因为音频片段有相同的单词和语调
- 片段1和片段3之间的距离也很短(虽然比片段4长),尽管他们使用不同的单词,但他们使用相同的语调和速度。
- 片段1和片段2虽然使用了同一句话,但由于语调和语速极其夸张,两者之间的距离最长。
如您所见,使用动态时间扭曲,可以确定两个不同时间序列的相似性。
下一个
既然我们已经讨论了动态时间扭曲,让我们将这个用例应用于检测销售趋势。
免费试用Databricks
相关的帖子