
Azure云实时分布式监控和日志记录


你怎么能观察到难以察觉的?在砖我们从内部服务依赖于详细的指标保持高可用性和可靠性。然而,砖Apache火花™平台管理集群的客户,自bob体育客户端下载己部署到Azure账户和私有虚拟网络,我们的监视基础设施无法轻易观察。
这个博客描述我们得到实时指标构建的解决方案到我们中央监控基础设施从这些“不可见的”环境。我们提出的架构是独特的监控不仅Apache火花™集群,但可以用来刮指标和日志从任何分布式架构部署到Azure云或私人VPN。
设置
砖为云服务提供了一个全球架构,操作各种云服务,区域,和部署模型。这种独特的复杂性带来了挑战,强调有适当的可见性的重要性我们的服务。砖的可观测性团队是负责提供一个平台来处理数据在三个支柱:指标、日志和跟踪。bob体育客户端下载这篇文章主要关注如何提供一种更好的体验的2 3数据源:指标(测量记录服务或健康状况)和日志(发出不同的事件服务)。
我们的指标监测基础设施由部署普罗米修斯一个开源的bob下载地址监控系统,运行在区域Kubernetes集群。每个组复制服务负责收集所有托管服务的遥测数据,摄取和储存指标定期采样间隔。我们利用Grafana和Alertmanager构建仪表盘和实时报警,以便我们的工程师能保持了解砖的健康服务。
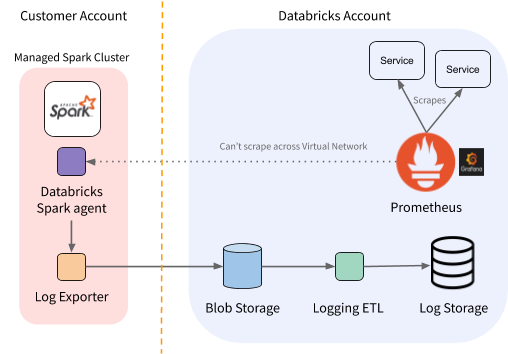
图1所示。每个区域都砖监控体系结构的观点。
此体系结构适用于服务运行在相同的Kubernetes集群,正如上面所讨论的,但客户部署不能刮。这些服务被我们遥不可及的普罗米修斯部署意味着我们不收集度量数据和见解失去有价值的服务。
然而,我们有一个内部log-exporter代理运行在这些环境。我们决定利用,也收集指标和代理他们回到我们中央集群。
需求
与其他接口工程师聊天后,我们收集以下这个系统要求:
- 过程的高吞吐量每分钟10的GBs,灵活扩展预测未来负荷
- 实现sub-minute延迟
- 确保高可用性和容错
我们可以利用log-exporter时,我们不能用我们现有的日志ETL管道时对对象存储操作,并有明显的延迟。主要用例度规管道实时报警,和后期数据抑制能力减少事件的响应时间。
此外,我们希望这个系统是可扩展的,等用例改善我们现有的延迟日志管道。日志管道有一个略微宽松的要求延迟时间(分钟),但明显更高的吞吐量。
运输
我们决定使用Apache卡夫卡数据传输。卡夫卡是一个常见的解决方案构建实时事件日志管道,并使用各种方法来实现水平的吞吐量,延迟和容错,使其对该用例的吸引力。
另外我们利用Azure的活动中心云端数据摄入服务可以公开卡夫卡的表面。这意味着我们可以开始迅速部署和管理基础设施的投资,而迁移到自我管理的可能性,卡夫卡在未来以最少的代码更改。
建立一个实时的管道
一旦我们选定了传输层和部署活动中心,我们继续实现实际的收集管道。
收集度量标准
我们的log-exporter(毫无疑问)造成的。因此我们修改我们的主要服务循环转储所有服务的度量每30秒到一个文件。普罗米修斯客户端库使这很容易,我们可以简单地遍历默认注册和发现写出所有的指标。这是将返回相同的数据直接通过普罗米修斯如果服务被取消。我们选择因为这三十秒模拟刮间隔直接刮时我们使用的服务。
我们log-exporter已经支持一个“流”模式,文件可以“尾随”和写入到流端点。我们简单地配置log-exporter治疗指标应该流日志转储文件。
生产信息
下一步是修改我们的原木出口国卡夫卡作为协议的支持。这是简单的建造使用OSS卡夫卡生产国。我们有一些关于如何选择积极试图保证交货时。我们决定增加吞吐量降低的贸易担保记录确认的酒吧。失去一轮指标并不太坏,因为我们将只发送一个更新的度量值三十秒后。
消费信息
更复杂的消费方面。移动日志从卡夫卡ETL管道是自然的,但过程指标尚不明朗。如前所述,普罗米修斯操作拉模型,擦伤的服务。不能刮(即为服务。,短时间运行的工作),他们提供Pushgateway。服务可以把指标Pushgateway缓存,以及共存普罗米修斯将刮他们从那里。
我们采用这个模型暴露的代理指标普罗米修斯与服务命名Kafka2Prom (K2P)。所有的K2P豆荚属于单个卡夫卡消费者团体。每个吊舱被分配分区的一个子集,然后使用相应的指标发出托收Prometheus-compatible指标端点。我们只提供交付担保承诺补偿回卡夫卡一旦指标被暴露出来。
在这一点上我们的度量标准收集管道看起来像下图:
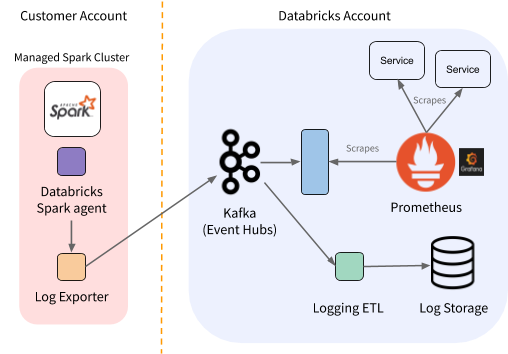
图2。砖监控架构的每个区域都视图(与卡夫卡和Kafka2prom服务)。
有一点需要注意:普罗米修斯摄食指标并将它们存储使用时间戳设置为刮时间(而不是上传时间或事件)。这是一个很好的假设为当地服务,对K2P但是有一些影响。K2P需要保证一旦暴露于某种度量普罗米修斯的豆荚,没有旧的价值指标会受到后来因为普罗米修斯将给它一个时间戳。所有值的度量发表同样的卡夫卡的话题,所以保证这一个豆荚内很简单。这有点难以保证在一个分区平衡:如果新的度量值出现在新的豆荚而老豆荚还前面的值,普罗米修斯可以刮他们的秩序。为了避免这种情况,我们的缓存同步驱逐老豆荚允许新仓前收到任何指标的重新平衡的话题。
另一个考虑是如何解决“吵闹的邻居”。因为我们需要订购在豆荚,跨分区的分布记录不一定是统一的。虽然我们可以选择扩展的数量K2P豆荚分区的数量,我们也可以将多个分区分配给一个圆荚体,利用多个cpu。我们都保持在一个线程处理一个分区,因为否则很难保持要求担保。在此设置中,我们不希望一个备份在一个分区来阻止其他线程处理。异步多线程处理,我们需要通过记录从消费者(s)到处理器。为此,我们在每个分区使用一小积压队列。这允许隔离分区:如果一个线程落后和队列满了,我们可以暂停这个分区,而其他线程继续不受影响。这也给了我们一些如何处理背压的灵活性。例如,在紧急情况下我们可以停止暂停分区,而是从队列的前面。 We would have less granular metrics data, but we could catch up to the current metrics without skipping directly to the latest record and losing all insight about what happened in between.
结论
这个项目启用实时可见性的“不可见的”在Azure引发工人。这提高了监控(仪表板和警报)和工程师数据驱动决策的能力来提高我们产品的性能和稳定性。
这个系统的各个组件可以规模水平和独立,使砖的能力继续适应不断增长的遥测数据规模的用例。此外,我们希望继续扩大的用例生成额外的见解和利用这个log-centric架构。