
Databricks Connect:将托管的Apache Spark™功能引入应用程序和微服务

在这篇博文中,我们将介绍砖连接,这是一个新的库,允许您从任何Notebook、IDE或自定义应用程序中利用本机Apache Spark api。
概述
在过去的几年中,已经为Apache Spark编写了许多自定义应用程序连接器。这包括spark-submit、REST作业服务器、笔记本网关等工具。这些工具受到许多限制,包括:
- 它们不是一刀切的:许多只适用于特定的ide或笔记本电脑。
- 它们可能要求您的应用程序在Spark集群中托管运行。
- 您必须在Spark之上集成另一组编程接口。
- 除非重新启动集群,否则无法更改库依赖项。
将此与连接到SQL数据库服务的方式进行比较,后者只涉及导入库并连接到服务器:
< span风格="颜色:# ff0000;“>进口< / span > pymysqlConn = pymysql.connect()conn.execute (< span =风格”颜色:# ff6600;“>“选择销售日期,产品”< / span >) < / connection_conf > Spark的结构化数据api的等效程序如下:
< span风格="颜色:# ff0000;“>从< / span > pyspark。SQL "颜色:# ff0000;“>进口< / span > SparkSessionspark = SparkSession.builder.config().getOrCreate()火花。表(< span =风格”颜色:# ff6600;“>“销售”< / span >)。selectExpr (< span =风格”颜色:# ff6600;“>“日期”, ”颜色:# ff6600;“>“产品”< / span >),告诉()< / connection_conf > 但是,在Databricks Connect之前,上面的代码片段只能用于单机Spark集群—防止您轻松扩展到多台机器或云,而无需额外的工具,如Spark -submit。
Databricks连接客户机
Databricks Connect通过提供一个通用的Spark客户端库来完成Spark连接器的故事。这使您可以从笔记本应用程序(例如,Jupyter, Zeppelin, CoLab), ide(例如,Eclipse,PyCharm、Intellij、RStudio)和自定义Python / Java应用程序。
这意味着任何你可以“导入!pyspark或“导入org.apache。”spark”,您现在可以在Databricks集群上无缝运行大规模作业。作为一个例子,我们展示了一个CoLab笔记本电脑使用Databricks Connect远程执行Spark作业。需要注意的是,这里没有特定于应用程序的集成——我们只是安装了databicks -connect库并导入了它。我们还从GCP读取S3数据集,这是可能的,因为Spark集群本身托管在AWS区域:
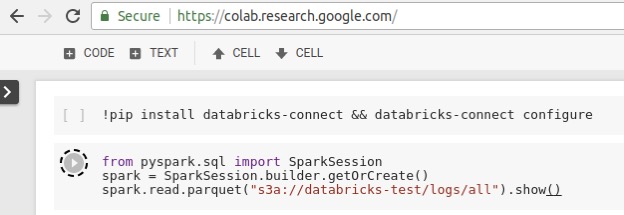
从Databricks Connect启动的作业在Databricks集群上远程运行,以利用它们的分布式计算,并且可以使用Databricks Spark UI进行监控:

客户用例
目前有超过100个客户正在积极使用Databricks Connect。一些值得注意的用例包括:
开发与CI/CD:
- 在与Databricks托管集群交互时使用本地ide调试代码
- 在CI/CD管道中针对生产环境测试Spark应用程序
互动分析:
- 许多用户使用Databricks Connect,因此他们可以使用自己喜欢的shell(例如Jupyter、bash)或studio环境(例如RStudio)对Databricks集群发出交互式查询
应用程序开发:
- 医疗保健领域的一个大客户使用Databricks Connect部署了一个基于python的微服务,用于提供交互式用户查询。查询服务使用Databricks Connect库对多个Databricks集群远程运行Spark作业,每天处理数千个查询。
Databricks如何连接
为了构建一个通用的客户端库,我们必须满足以下需求:
- 从应用程序的角度来看,客户端库的行为应该完全像完整的Spark(也就是说,你可以使用SQL、DataFrames等等)。
- 诸如物理规划和执行等重量级操作必须在云中服务器上运行。否则,如果客户端没有与集群在同一位置运行,就会在广域网上读取大量的数据。
为满足这些需求,当应用程序使用火花api, Databricks Connect库运行作业的计划,一直到分析阶段.这使得Databricks Connect库的行为与Spark相同(需求1)。当任务准备执行时,Databricks Connect将逻辑查询计划发送到服务器,在那里发生实际的物理执行和IO(需求2):
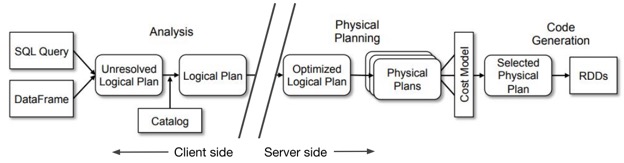
图1。Databricks Connect将Spark作业的生命周期分为客户端阶段(包括逻辑分析)和服务器阶段(在远程集群上执行)。
Databricks Connect客户端被设计为跨各种用例良好工作。它通过REST与服务器通信,通过平台直接进行身份验证和授权bob体育客户端下载API的令牌.会话在多个用户之间隔离,以实现安全、高并发的集群共享。结果以有效的二进制格式流回,以实现高性能。所使用的协议是无状态的,这意味着您可以轻松地构建容错应用程序,即使集群重新启动也不会丢失工作。
可用性
Databricks Connect从DBR 5.4发行版开始正式可用,并支持Python、Scala、Java和R工作负载。你可以从PyPI对于所有带有“pip install databicks -connect”的语言,都有文档可用在这里.