



Delta Lake生产机器学习
在Databricks中尝试这个笔记本系列-第1部分(Delta Lake),第2部分(Delta Lake + ML)对于许多数据科学家来说,…
试试这个笔记本系列在Databricks -第一部分(三角洲湖),第二部分(Delta Lake + ML)
对于许多数据科学家来说,构建和调优机器学习模型的过程只是他们每天工作的一小部分。他们的绝大多数时间都花在执行ETL、构建数据管道和将模型投入生产等不那么光鲜(但至关重要)的工作上。
在本文中,我们将逐步介绍构建生产数据科学管道的过程。在此过程中,我们将演示Delta Lake如何成为机器学习生命周期的理想平台,因为它提供了统一数据科学、数据工程和生产工作bob体育客户端下载流的工具和功能,包括:
Delta Lake的这些特性使数据工程师和科学家能够比以往更快地设计可靠、有弹性的自动化数据管道和机器学习模型。
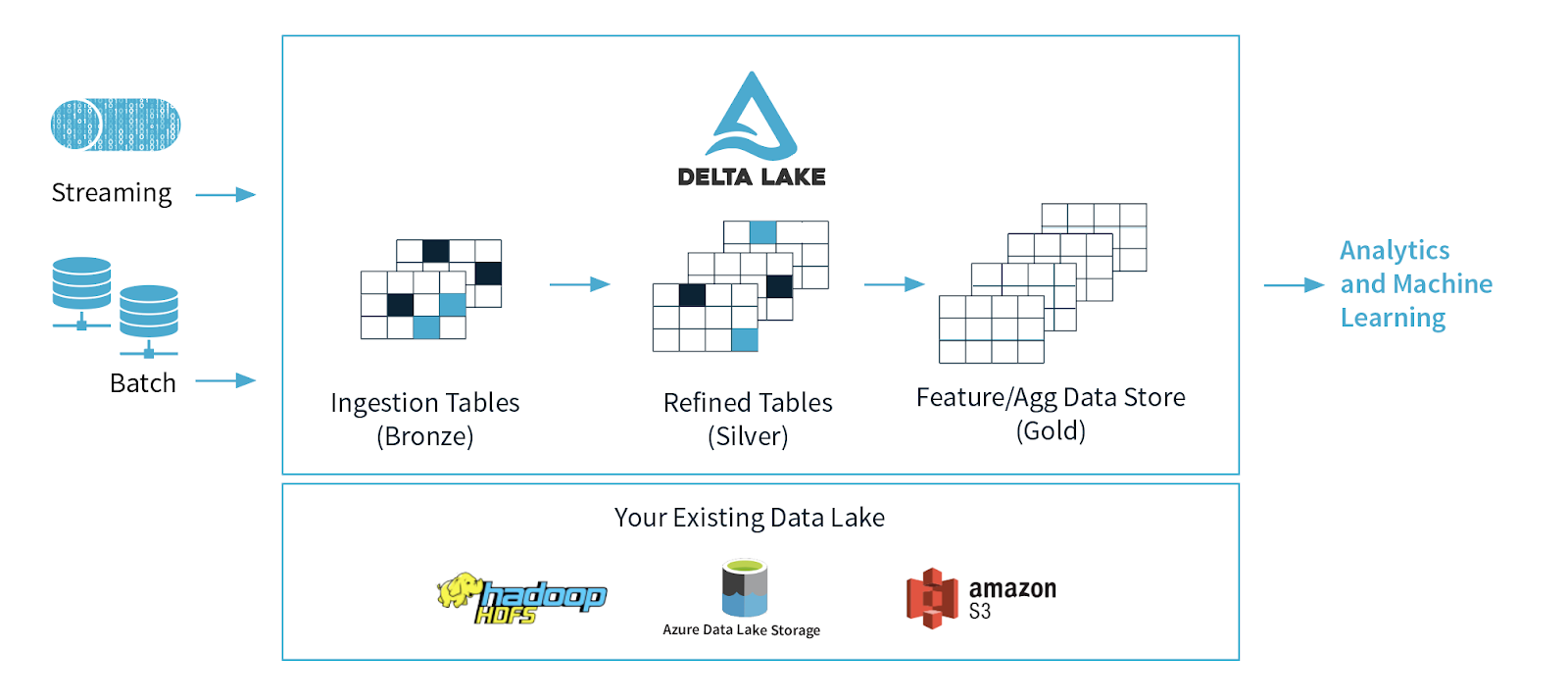
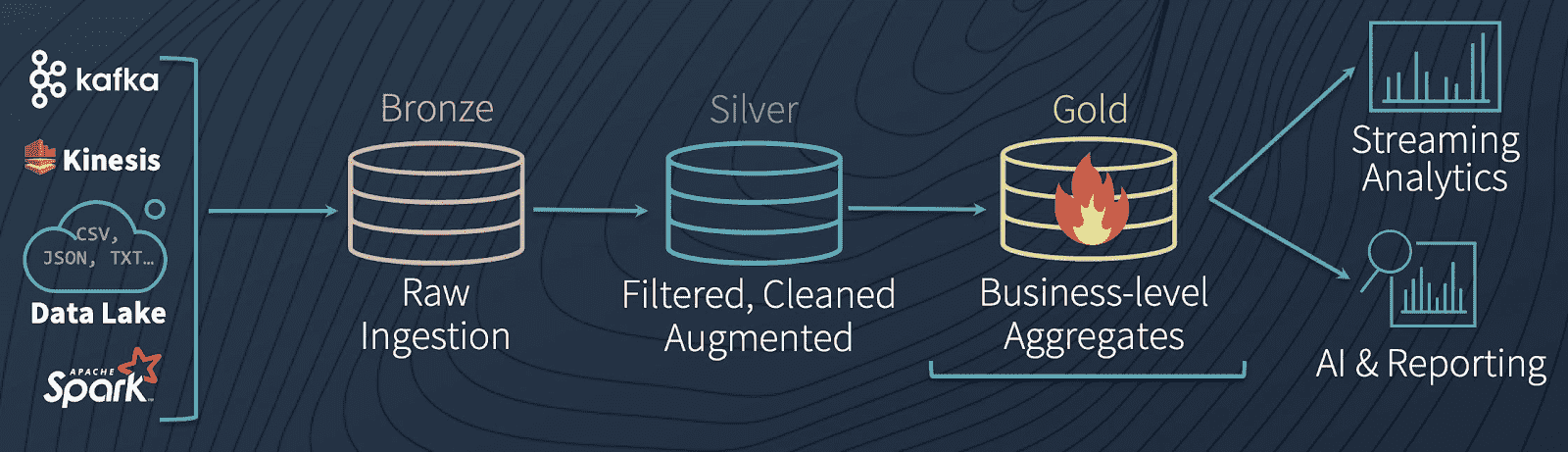
一个常见的架构使用对应于数据工程管道中不同质量级别的表,逐步向数据添加结构:数据摄取(“青铜”表),转换/特征工程(“银”表),以及机器学习训练或预测(“金”表)。结合起来,我们将这些表称为“多跳”体系结构。它允许数据工程师构建以原始数据为起点的管道“单一的真相来源”一切都源于此。后续的转换和聚合可以重新计算和验证,以确保业务级聚合表仍然反映底层数据,即使下游用户细化数据并引入特定于上下文的结构。
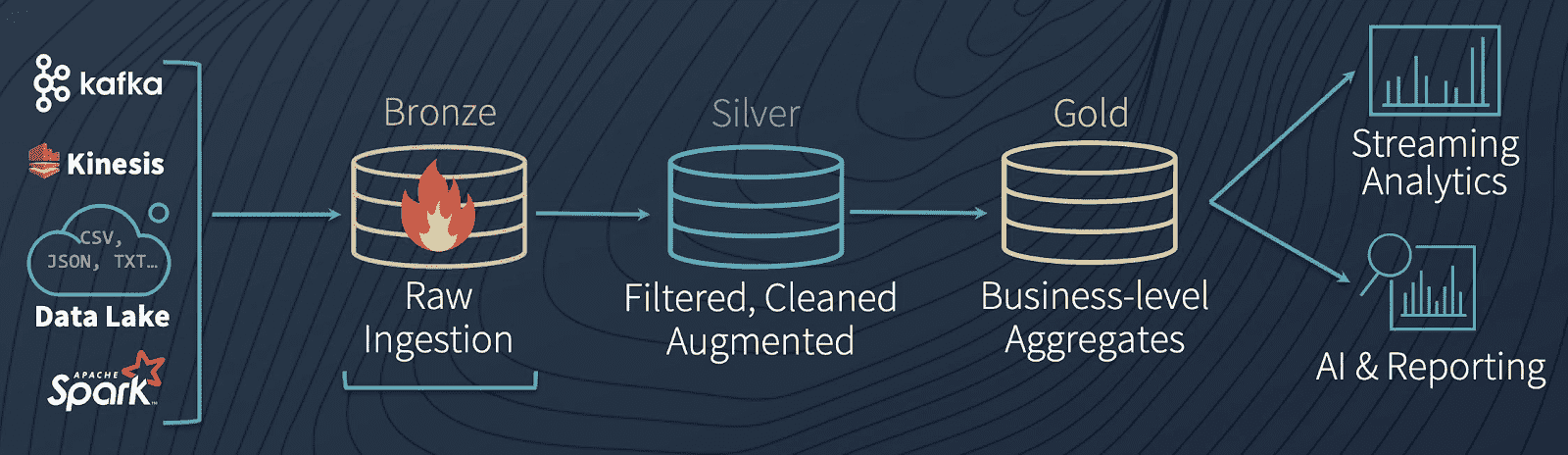
为了理解Delta Lake管道是如何工作的(如果您允许我们使用扩展的示例),有必要深入研究将数据比作水的类比。Delta Lake允许数据像水一样流动,而不是调度一系列不同的批处理作业,使数据在管道中分阶段移动:无缝、持续、实时。
青铜桌子作为原型湖,大量的水(数据)不断流入。当它到达时,它是脏的,因为它来自不同的来源,其中一些并不那么干净。从那里,数据不断地流入Silver表,就像一条河流的源头连接到湖泊,快速移动,不断流动。当水(在我们的例子中是数据)流向下游时,它会被河流的曲折所净化和过滤,在流动的过程中变得更加纯净。当它到达下游的水处理厂(我们的金表)时,它会接受一些最终的净化和严格的测试,以便为消费做好准备,因为消费者(在这种情况下,ML算法)非常挑剔,不会容忍被污染的水。最后,从净化工厂,它被输送到每个下游消费者的水龙头(无论是ML算法,还是BI分析师),准备以最纯净的形式消费。
为机器学习准备数据的第一步是创建一个Bronze表,在这个表中可以以最原始的形式捕获和保留数据。让我们来看看如何做到这一点-但首先,让我们谈谈为什么三角洲湖是你的明显选择数据湖.
如今,我们看到的最常见的模式是公司使用Azure Event Hubs或AWS Kinesis收集实时流数据(例如客户在网站上的点击行为),并将其保存到廉价、丰富的云存储中,如Blob存储或S3存储桶。公司通常希望用历史数据(比如客户过去的购买历史)来补充这些实时流数据,以获得过去和现在的完整情况。
因此,公司往往会有大量从各种来源收集的原始、非结构化数据停滞在数据湖中。如果没有办法可靠地将历史数据与实时流数据结合起来,并为数据添加结构,以便将其输入机器学习模型,这些数据湖可能很快就会变得错综复杂、杂乱无章,从而产生了“数据沼泽”一词。
在单个数据点被转换或分析之前,数据工程师已经遇到了他们的第一个难题:如何将历史数据(“批处理”)和实时流数据处理结合在一起。传统上,人们可能会使用aλ架构为了弥补这一差距,但这也带来了自身的问题,这些问题源于lambda的复杂性,以及它导致数据丢失或损坏的倾向。
“数据湖困境”的解决方案是利用三角洲湖.Delta Lake是一个位于数据湖之上的开源存储层。它是为分布式计算而构建的,并且与Apache Spark 100%兼容,因此您可以轻松地将现有数据表从当前存储的任何格式(CSV, Parquet等)转换为Delta Lake格式的Bronze表,并使用您最喜欢的格式将其保存为Bronze表火花api,如下图所示。
#读取loanstats_2012_2017.parquetloan_stats_ce = spark.read.parquet(PARQUET_FILE_PATH)#保存为Delta Lake表loan_stats_ce.write。格式(“δ”) .mode (“覆盖”) .save (DELTALAKE_FILE_PATH)#重读为三角洲湖Loan_stats = spark.read。格式(“δ”) .load (DELTALAKE_FILE_PATH)一旦为原始数据构建了Bronze表,并将现有表转换为Delta Lake格式,就已经解决了数据工程师的第一个难题:结合过去和现在的数据。怎么做?Delta Lake表可以无缝地处理来自历史和实时流数据源的连续数据流。由于它使用Spark,它几乎可以与不同的流数据输入格式和源系统兼容,无论是Kafka、Kinesis、Cassandra还是其他系统。
要演示Delta Lake表如何同时处理批处理数据和流数据,请查看以下代码。在从文件夹中加载初始数据集之后DELTALAKE_FILE_PATH输入Delta Lake表(如前面的代码块所示),我们可以使用友好的SQL语法对当前数据运行批量查询,然后再将新数据输入到表中。
%sql选择addr_state,总和(“计数”)作为贷款从loan_by_state_delta集团通过addr_state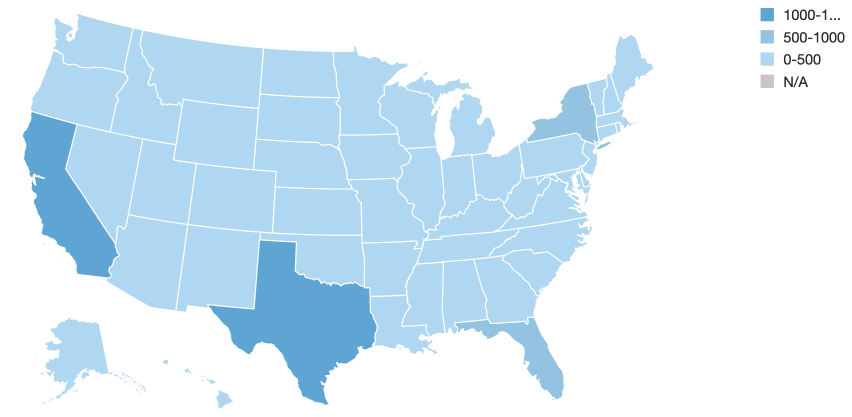
如上图所示,最初,加州和德克萨斯州的贷款数量最高。
现在我们已经演示了Delta Lake运行批处理查询的能力,下一步是展示它同时对流数据运行查询的能力。
我们将创建一个流数据源,它不断地向Delta Lake表添加新数据,并结合之前绘制的现有批处理数据。注意loan_by_state_readStream从相同的位置读取,DELTALAKE_FILE_PATH,就像批处理查询在前面的代码块中所做的那样。
loan_by_state_readStream = spark.readStream。格式(“δ”) .load (DELTALAKE_FILE_PATH)loan_by_state_readStream.createOrReplaceTempView (“loan_by_state_readStream”)实际上,批处理数据和流数据可以落在相同的位置(即。DELTALAKE_FILE_PATH), Delta Lake可以同时响应对这两种类型数据的查询——因此Delta Lake表提供了“统一的批处理和流源和接收器”。
当三角洲湖处理河流时,可视化在我们眼前更新,我们开始看到不同的模式出现。
https://www.youtube.com/watch?v=NqqIYccrjzw
正如你所看到的,由于最近的数据流,爱荷华州(中西部越来越黑的州)拥有最多的贷款。的loan_by_state_delta表被更新,即使新数据流到表并发使用loan_by_state_readStream.
现在我们已经看到Delta Lake如何让我们同时可靠地分析批处理和流数据源,下一步是进行一些数据清理、转换和特征工程,为机器学习工作做好准备。
到目前为止,我们已经成功地将数据转换为Delta Lake格式,并创建了一个青铜表,作为无缝处理历史数据和实时数据的着陆区。目前,数据处于正确的位置,但在目前的形式下远非有用:在可以用于机器学习模型之前,它需要大量的清理、转换和结构。ML建模库在数据类型、空值和缺失数据方面没有提供太多的灵活性(如果有的话!),因此数据工程师的下一个工作是清理和处理原始数据。由于Delta Lake与Apache Spark 100%兼容,我们可以使用Spark熟悉的API在Delta Lake表上执行我们想要的数据修改,如下所示。
打印(“将多个级别映射为一个因素级别,用于verification_status…”)loan_stats = loan_stats. withcolumn (“verification_status”的削减(regexp_replace (loan_stats.verification_status“源验证”,“验证”)))打印(“计算每笔贷款赚到或损失的总金额……”)loan_stats = loan_stats. withcolumn (“净”,轮(loan_stats。Total_pymnt - loan_stats.loan_amnt,2))
在执行ETL之后,我们可以将清理过的、处理过的数据保存到一个新的Delta Lake Silver表中,这允许我们将结果保存为一个新表,而无需修改原始数据。
中间的Silver表很重要,因为它可以作为多个下游金表,由不同的业务部门和用户控制。例如,您可以想象一个表示“产品销售”的Silver表流入几个用途非常不同的Gold表:例如,更新供应链仪表板,计算销售人员的工资奖金,或为董事会成员提供高级kpi。
我们没有简单地将Gold表直接连接到Bronze表中保存的原始数据的原因是,这会导致大量重复工作。这将要求每个业务单元对其数据执行相同的ETL。相反,我们可以只执行一次。作为附带的好处,这一步避免了由于数据分歧而造成的混乱,比如不同的业务单位计算相同的度量略有不同。
通过遵循这个蓝图,我们可以确信保存到最终Gold表中的数据是干净的、一致的和一致的。
现在我们已经转换了数据,下一步是通过强制执行模式向Delta Lake Silver表引入结构。模式强制对于数据科学家和工程师来说是一个重要的特性,因为它可以确保我们能够保持表的干净整洁。如果没有模式强制,单个列中的数据类型可能会混合在一起,从而严重影响数据的可靠性。例如,如果我们不小心引入StringType数据成一列FloatType数据,我们可能会无意中让我们的机器学习模型无法读取列,破坏我们宝贵的数据管道。
三角洲湖优惠模式验证在写,这意味着当它向表写入新记录时,Delta Lake会检查以确保这些记录与表的预定义模式匹配。如果记录与表的模式不匹配,Delta Lake将引发一个异常,以防止不匹配的数据用冲突的数据类型污染列。这种方法比模式验证更可取在阅读,因为一旦不正确的数据类型已经污染了一个列,就很难“把精灵放回瓶子里”。
Delta Lake可以很容易地定义模式,并使用以下代码强制执行它。请注意,传入的数据是如何因为不匹配表的模式而被拒绝的。
#生成以美元为单位的贷款样本贷款= sql(“select addr_state, cast(rand(10)*count as bigint) as count, cast(rand(10)* 10000 *count as double) as amount from loan_by_state_delta”)显示器(贷款)#让我们把这些数据写到Delta表中loans.write.format (“δ”) .mode (“添加”) .save (DELTALAKE_SILVER_PATH)< span风格=“颜色:红色;>// AnalysisException:写入Delta表时检测到模式不匹配如果错误不是由于包含错误类型数据的列造成的,而是由于我们(有意地)添加了一个没有反映在当前模式中的新列,那么我们可以添加该列并使用模式进化来纠正错误,稍后我们将对此进行解释。
一旦数据通过模式强制达到这个阶段,我们就可以将其以最终形式保存在Delta Lake Gold表中。现在它已经被彻底清洗、转换,并准备好供我们的机器学习模型使用——这些模型对数据的结构相当挑剔!通过将数据从原始状态流到Bronze和Silver表,我们已经建立了一个可重复的数据科学管道,可以接收所有新数据并将其转换为ml就绪状态。这些流可以是低延迟的,也可以手动触发,无需像传统管道那样管理日程和作业。
现在我们已经转换了数据,并使用模式强制添加了结构,现在可以开始运行实验并使用数据构建模型了。这就是数据科学中的“科学”真正发挥作用的地方。我们要创建零假设和替代假设,建立和测试我们的模型,并衡量我们的模型预测因变量的能力。的确,这个舞台是我们许多人发光的地方!
数据科学家需要能够进行可重复的实验。可重复性是所有科学探究的基石:如果观察结果不能被测试、再测试和再现,就不可能更接近真理。然而,当有这么多不同的方法来解决同一个问题时,我们中谁能取得严格的线性进展呢?
毫无疑问,我们中的许多人都相信我们做事的方式有一点“魔力”,我们通过遵循不确定和迂回的询问和探索路线到达目的地。这是可以的——只要我们使用的工具允许我们展示我们的工作,回溯我们的步骤,并留下面包屑——如果你愿意的话,在疯狂中添加一点科学方法。有了Delta Lake的时间旅行和MLflow,以上所有和更多都是可能的。
对于数据科学家来说,Delta Lake最有用的功能之一是能够使用数据版本控制回到过去,也就是“时间旅行”。Delta Lake维护在任何Delta Lake表上执行的每个操作的有序事务日志,因此如果您希望恢复到表的早期版本,撤消无意中的操作,甚至只是查看数据在特定时间段的情况,都可以。
可以很容易地使用时间旅行从表的早期版本中选择数据。用户可以查看表的历史,并通过使用版本历史编号(如下面的代码所示)在选择表时查看当时的数据loan_by_state_delta版本的0),或按时间戳。
%sql描述历史loan_by_state_delta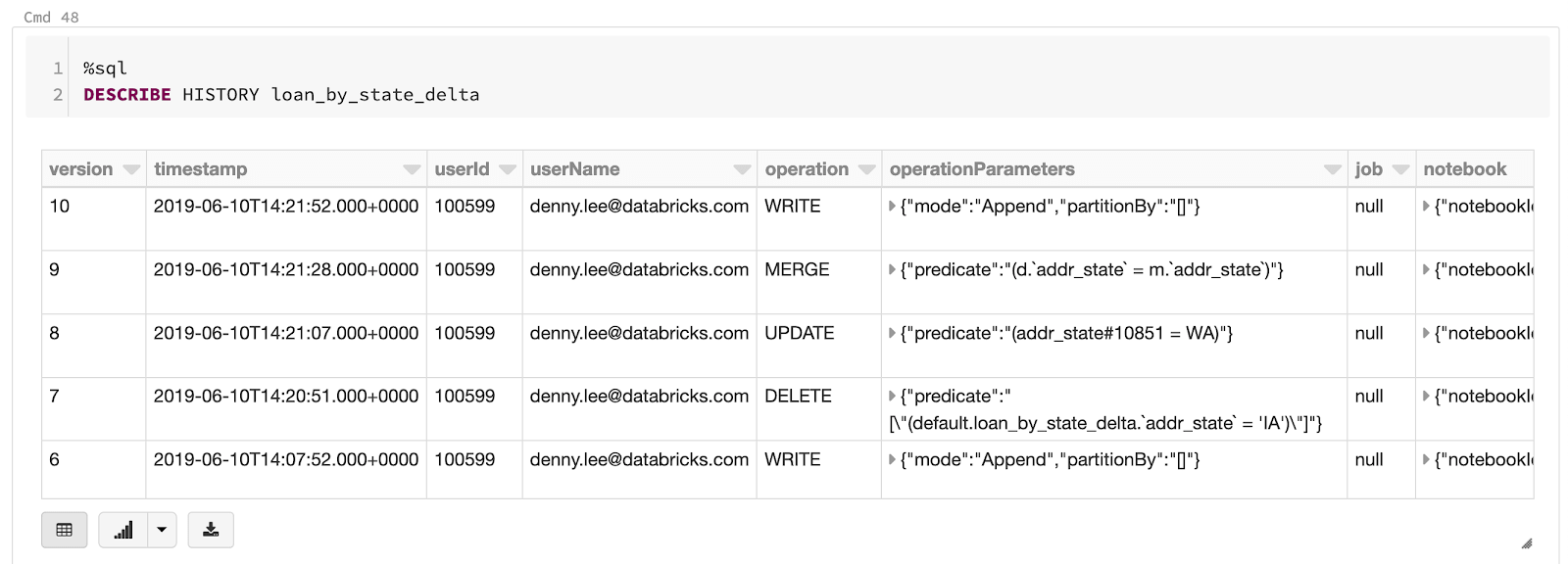
要选择表的旧版本,可以使用熟悉的SQL语法,如下所示。
%sql选择*从loan_by_state_delta版本作为的0除了使用表版本号,还可以使用时间戳来获得数据在特定时间点的“数据快照”。
%sql选择*从loan_by_state_delta时间戳作为的“2019-07-14 16:30:00”与MLflow一起(下面将讨论),Delta Lake的时间旅行确保您对数据执行的所有转换和实验都是可跟踪的、可重复的和可逆的。它可用于:
有序的事务日志创建了可验证的数据沿袭,这对GRC(治理、风险和遵从性)应用程序特别有用。根据GDPR和CCPA等法规,公司需要有能力证明数据被正确删除或匿名化(无论是集体数据还是个人数据)。更新、合并、删除、插入等都可以被确认和验证,以用于审计目的。
最后,数据工程师可以更轻松地入睡,因为他们知道,像无意中遗漏的行或计算错误的列这样的人为错误是可以通过时间旅行100%逆转的。墨菲定律著名地指出,如果任何事情都可能出错,它就会出错,数据管道也不例外——由于人为错误,错误可以而且确实不可避免地发生。丢失数据更有可能是因为有人意外地编辑了一个表,而不是因为硬件故障,而且这些错误是可以恢复的。
事务日志的另一个用处是调试您看到的错误——您可以回到过去,发现问题是如何产生的,然后修复问题或恢复数据集。
![]()
MLflow是一个开源Python库,与Delta Lake携手合作,使数据科学家能够毫不费力地记录和跟踪指标、参数以及文件和图像工件。用户可以进行多个不同的实验,随意改变变量和参数,知道输入和输出已被记录和记录。您甚至可以在使用不同的超参数组合进行实验时自动保存训练过的模型,这样模型权重就已经保存了,一旦您选择了性能最好的模型就可以使用。
在Databricks中,MLflow从MLR 5.5开始自动启用,您可以使用MLflow运行侧边栏,如下图所示。
https://www.youtube.com/watch?v=o6SBBlhqw2A
通常,数据工程师和科学家发现,数据管道的初始构建比维护它更容易。随着时间的推移,由于业务需求、业务定义、产品更新和时间序列数据的性质的变化,对表模式的更改实际上是不可避免的,因此使用使这些更改更易于管理的工具非常重要。Delta Lake不仅为模式实施提供了工具,而且还为模式演变提供了工具mergeSchema选项,如下所示。
#添加mergeSchema选项loans.write.option(“mergeSchema”,“真正的”).format .mode(“δ”)(“追加”).save (DELTALAKE_SILVER_PATH)%sql检查' loan_by_state_delta ' Delta Lake表中的当前贷款选择addr_state,总和(“金额”)作为量从loan_by_state_delta集团通过addr_state订单通过总和(“金额”)DESC限制10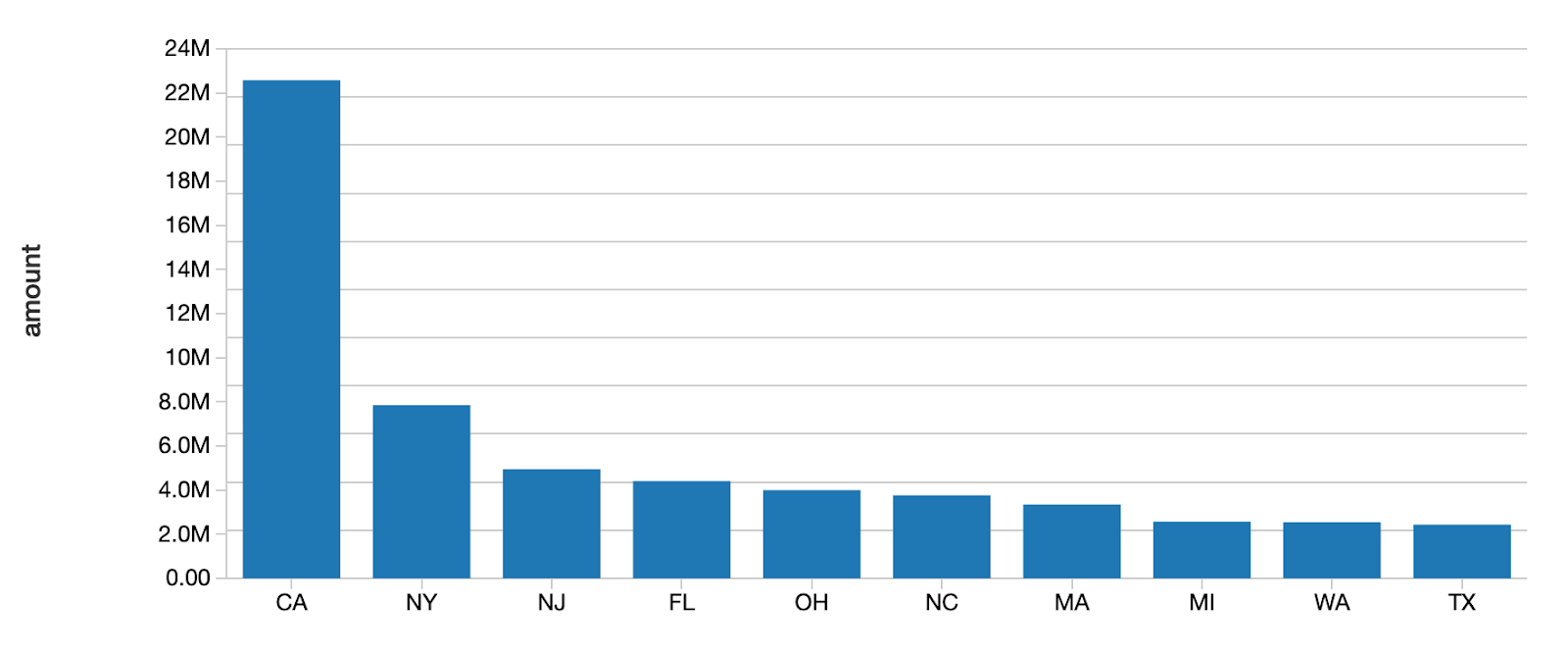
通过添加.option(“mergeSchema”,“真正的”)对于您的查询,任何出现在DataFrame中但不在目标Delta Lake表中的列都将作为写事务的一部分自动添加。数据工程师和科学家可以使用这个选项向他们现有的机器学习生产表添加新列(可能是一个新跟踪的指标,或者本月的销售数据的列),而不会破坏依赖于旧列的现有模型。
MLflow在后台记录我们的参数和结果,我们已经准备好将数据分成训练集和测试集,并训练我们的机器学习模型。我们已经创建了Gold表,我们将通过从Silver数据中获取转换后的数据来训练我们的模型,并强制执行模式,以确保进入这个最终表的所有数据都是一致且无错误的。现在,我们已经使用前面介绍的“多跳”架构构建了我们的管道,使新数据能够连续地流入我们的管道,然后在整个过程中对这些数据进行处理并保存在中间表中。
为了完成机器学习生命周期,我们将构建一个具有标准化和交叉验证的GLM模型网格,如下面的缩写代码所示。我们在这里的目标是预测借款人是否在给定的贷款上违约。查看完整代码在这里.
使用逻辑回归lr = LogisticRegression(maxIter=10elasticNetParam =0.5, featuresCol =“scaledFeatures”)#构建ML管道管道=管道(阶段=model_matrix_stage +[标量]+[lr])#为模型调优构建参数网格paramGrid = ParamGridBuilder() \.addGrid (lr)。regParam, (0.1,0.01]) \.build ()#执行CrossValidator进行模型调优crossval =交叉验证器(估计器=管道,estimatorParamMaps = paramGrid,评估者= BinaryClassificationEvaluator (),numFolds =5)#训练调优模型,建立我们最好的模型cvModel = crossval.fit(train)glm_model = cvModel.bestModel#回归中华民国Lr_summary = glm_model.stages[len(glm_model.stages) -1] .summary显示器(lr_summary.roc)受试者工作特征(ROC)曲线的结果图如下所示。
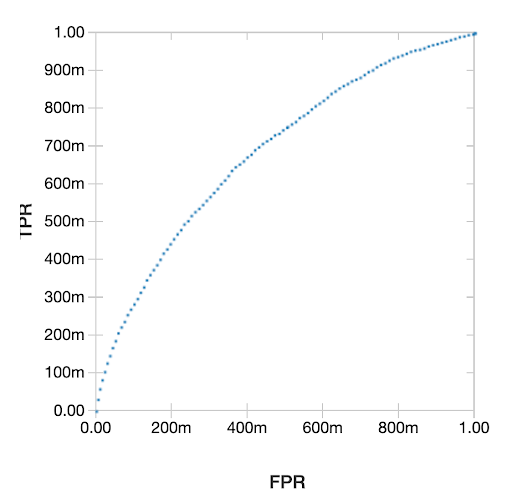
然后,我们继续将这个模型与完整代码笔记本中的其他几个广义线性模型进行比较,发现在这里.在选择最佳模型(XGBoost模型)之后,我们使用它来预测我们的测试集,并根据每个正确或不正确的分类绘制我们节省或损失的金额。正如数据科学家所知,像这样用金钱来表达你的分析总是一个好主意,因为它使你的结果具体且易于理解。
显示器(glm_valid。groupBy(“标签”,“预测”).agg ((总和(坳(“净”))).alias(“sum_net”)))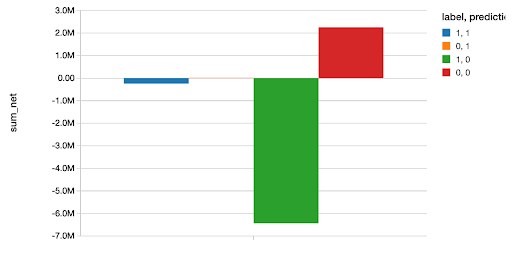
你可以在一篇博客文章中找到更深入的Scala示例在这里.
Delta Lake是机器学习生命周期的理想选择,因为它提供了统一数据科学、数据工程和生产工作流的功能。它启用数据从原始形式到结构化形式的连续流动,允许新的ML模型在新的输入数据上进行训练,而现有的生产模型则用于预测。它提供了模式执行,以确保数据的格式适合机器学习模型处理模式演化,它可以防止模式更改破坏现有的生产模型。最后,三角洲湖提供“时间旅行”,也就是数据版本控制通过有序事务日志,允许对数据更改进行审计、复制,甚至在需要时进行回滚。
总的来说,Delta Lake的这些功能代表着数据工程师和科学家向前迈进了一步,使他们能够比以往更快地设计可靠、有弹性的自动化数据管道和机器学习模型。
欲了解更多信息,请观看为数据科学准备数据.
