在许多文章和博客中,机器学习工作流从数据准备开始,到将模型部署到生产中结束。但实际上,这只是机器学习模型生命周期的开始。正如他们所说,“变化是生活中唯一不变的”。这也适用于机器学习模型,因为随着时间的推移,它们的准确性或预测能力可能会恶化,通常被称为模型drif t .这篇博客讨论了如何检测和处理模型漂移。
机器学习中的漂移类型
当对特性数据或目标依赖关系进行某种形式的更改时,就会发生模型漂移。我们可以将这些变化大致分为以下三类:概念漂移、数据漂移和上游数据变化。
概念漂移
当目标变量的统计属性发生变化时,你试图预测的概念也会发生变化。例如,欺诈交易的定义可能会随着时间的推移而改变,因为进行此类非法交易的新方法正在发展。这种类型的改变会导致概念漂移。
数据漂移
用于训练模型的特征是从输入数据中选择的。当输入数据的统计属性发生变化时,它将对模型的质量产生下游影响。例如,由于季节性、个人偏好变化、趋势等导致的数据变化会导致传入数据漂移。
上游数据变更
有时,上游数据管道中的操作更改可能会对模型质量产生影响。例如,对特征编码的更改,如从华氏温度切换到摄氏温度,以及不再生成的特征导致空值或缺失值等。
检测和保护模型漂移的方法
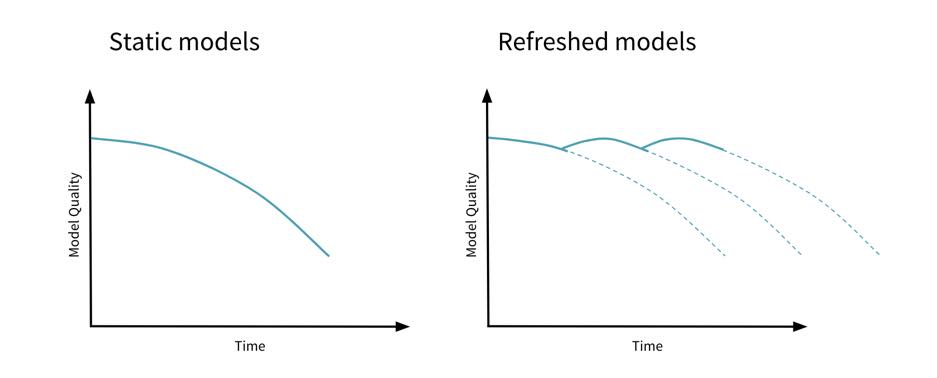
假设在将模型部署到生产环境之后会有这样的更改,那么您最好的行动就是监视更改,并在发生更改时采取行动。拥有来自监控系统的反馈循环,并随着时间的推移刷新模型,将有助于避免模型陈旧。
正如我们在上面看到的,漂移可能来自各种来源,因此您应该监视所有这些来源,以确保完全覆盖。以下是一些可以部署监控的场景:<一个href="//www.neidfyre.com/www/wp-content/uploads/2019/09/model_drift.png">
训练数据
请求和预测
使用数据库管理模型漂移
利用Delta Lake检测数据漂移
数据质量是防止模型质量差和模型漂移的第一道防线。Delta Lake通过提供模式强制、数据类型和质量期望等特性,帮助确保以高质量和可靠性构建数据管道。通常,您可以通过更新传入的数据管道来修复数据质量或正确性问题,例如修复或改进模式以及清除错误的标签等。
用Databricks Runtime检测ML和MLflow的概念和模型漂移
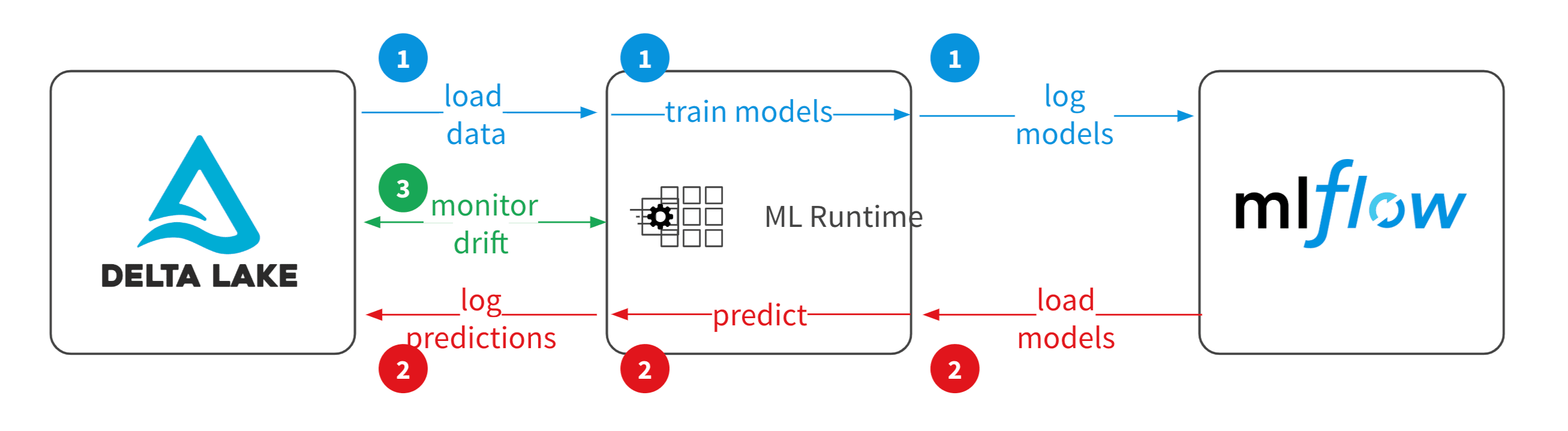
检测模型漂移的一种常用方法是监测预测的质量。一个理想的ML模型训练练习应该从从Delta Lake表等源加载数据开始,然后使用Databricks Runtime for ML进行特征工程、模型调优和选择,同时在MLflow中跟踪所有的实验运行和生成的模型。<一个href="//www.neidfyre.com/www/wp-content/uploads/2019/09/model_drift.png">
在部署阶段,在运行时从MLflow加载模型以进行预测。您可以将模型性能指标和预测记录回Delta Lake等存储,以便在下游系统和性能监视中使用。通过将训练数据、性能指标和预测记录在一个地方,您可以确保准确的监控。<一个href="//www.neidfyre.com/www/wp-content/uploads/2019/09/model_drift.png">
在监督训练期间,您使用来自训练数据的特征和标签来评估模型的质量。一旦部署了模型,您就可以记录和监视两种类型的数据:模型性能度量和模型质量度量。
建模性能度量 参考模型的技术方面,例如推断延迟或内存占用。当模型部署在Databricks上时,可以轻松地记录和监视这些指标。建模质量度量 视实际标签而定。一旦标签被记录下来,您就可以比较预测的和实际的标签来计算质量指标,并检测模型预测质量的偏差。
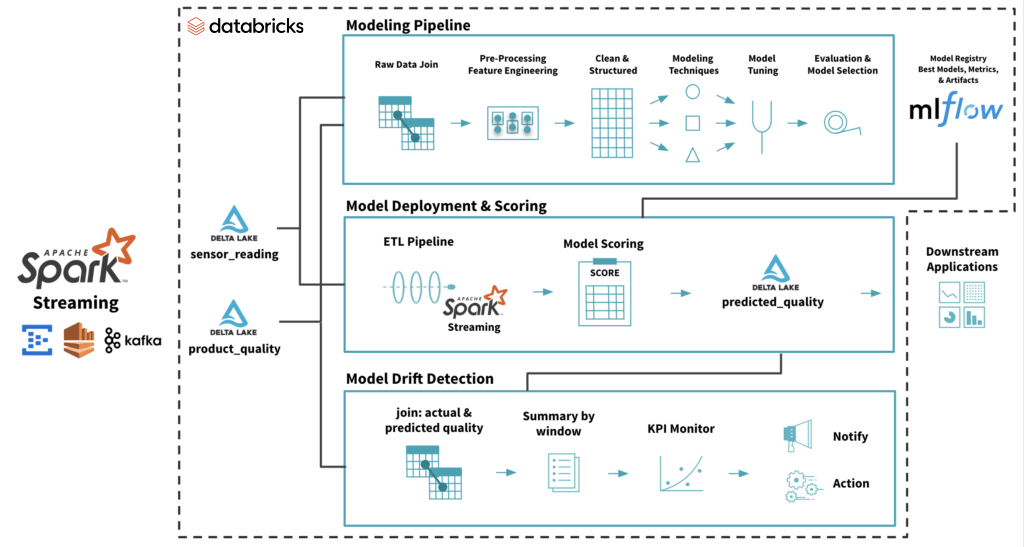
下面所示的示例架构使用来自物联网传感器(功能)和实际产品质量(标签)的数据作为Delta Lake的流媒体源。根据这些数据,您可以创建一个模型,从物联网传感器数据预测产品质量。在MLflow中部署的生产模型被加载到评分管道中,以获得预测的产品质量(预测标签)。
要监视漂移,您可以将实际产品质量(标签)和预测质量(预测标签)结合起来,并在一个时间窗口内汇总以趋势模型质量。用于监视模型质量的总结KPI可能会根据业务需求而变化,可以计算多个这样的KPI以确保足够的覆盖率。有关示例,请参阅下面的代码片段。
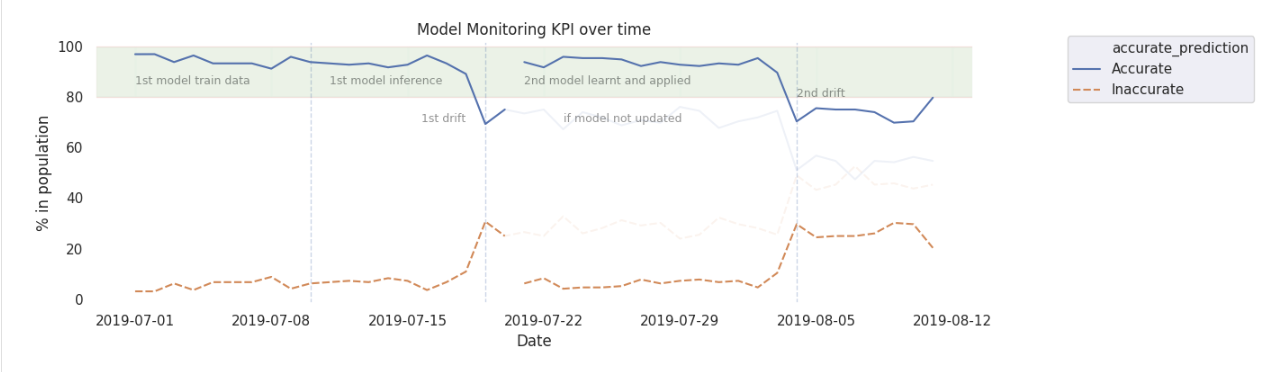
< b > def < / b > track_model_quality ( 真正的 ,预计): # 加入 实际标签 而且 预测的标签 quality_compare = predicted.join ( 真正的 “pid”) # 创建 一个 列 表示是否预测标签 是 准确的 quality_compare = quality_compare.withColumn ( “accurate_prediction” , F.when ((F.col ( “质量” ) = = F.col ( “predicted_quality” )), 1 ) \ .otherwise ( 0 ) )总结准确的标签 在 一个 时间 窗口 来 趋势 百分比 的 准确的预测 accurate_prediction_summary = (quality_compare.groupBy (F.window (F.col ( “process_time” ), “一天” ) .alias ( “窗口” ), F.col ( “accurate_prediction” )) . 数 () .withColumn ( “window_day” F.expr ( “to_date (window.start)” )) .withColumn ( “总” F。 总和 (F.col ( “数” ))。 在 (Window.partitionBy ( “window_day” ))) .withColumn ( “比” F.col ( “数” ) * One hundred. / F.col ( “总” )) . 选择 ( “window_day” , “accurate_prediction” , “数” , “总” , “比” ) .withColumn ( “accurate_prediction” , F.when (F.col ( “accurate_prediction” ) = = 1 , “准确” ) .otherwise ( “不准确” )) .orderBy ( “window_day” ) )< b > 返回 < / b > accurate_prediction_summary 根据延迟的实际标签与预测标签相比如何到达,这可能是一个重要的滞后指标。为了提供漂移的一些早期预警,该指标可以伴随着领先指标,如预测质量标签的分布。为了避免误报,需要根据业务上下文设计此类kpi。
您可以在业务需要可接受的控制范围内设置准确的预测汇总趋势。然后,可以使用标准的统计过程控制方法对摘要进行监控。当趋势超出这些控制限制时,它可以触发一个通知或一个操作,以使用更新的数据重新创建一个新模型。
下一个步骤
按照说明操作<一个href="https://github.com/joelcthomas/modeldrift" target="_blank">在这个GitHub回购,以重现上面的示例并适应您的用例。要了解更多背景信息,请参阅附带的网络研讨会,<一个href="//www.neidfyre.com/pages/ProductionizingMLWebinar_Reg.html" target="_blank">生产机器学习-从部署到漂移检测.