



使用Databricks Notebook + MLflow自动化部署和测试
如今,许多数据科学(DS)组织正在使用Databricks笔记本电脑加速敏捷分析开发过程。充分利用Apache Spark™的分布式计算能力,这些组织能够轻松地与几tb规模的数据交互,从探索到快速原型,一直到生产复杂的机器学习(ML)模型。随着快速迭代以高速度实现,越来越明显的是,为了效率、可重复性和高质量而管理DS生命周期是非常重要的。在数据量呈指数级增长的大型企业中,这种挑战成倍增加,从数据中获得业务价值的ROI期望很高,而且跨职能协作很常见。
在这篇博客中,我们将介绍一个与可迭代的用软件开发的最佳实践来强化DS过程。这种方法从Databricks笔记本电脑内部自动构建、测试和部署DS工作流,并与MLflow和Databricks CLI完全集成。它支持适当的版本控制和重要指标的全面日志记录,包括功能和集成测试、模型性能指标和数据沿袭。所有这些都无需维护单独的构建服务器即可实现。
概述
在典型的软件开发工作流(例如Github流程)中,一个特性分支是基于用于特性开发的主分支创建的。一个笔记本可以同步到功能分支Github集成.或者你可以将笔记本电脑从Databrick工作区导出到你的笔记本电脑上,然后用git命令将代码更改提交给特性分支。当开发准备好进行审查时,将建立一个Pull Request (PR),并将特性分支部署到一个登台环境中进行集成测试。一旦测试和批准,特性分支将被合并到主分支中。主分支总是可以部署到生产环境中。
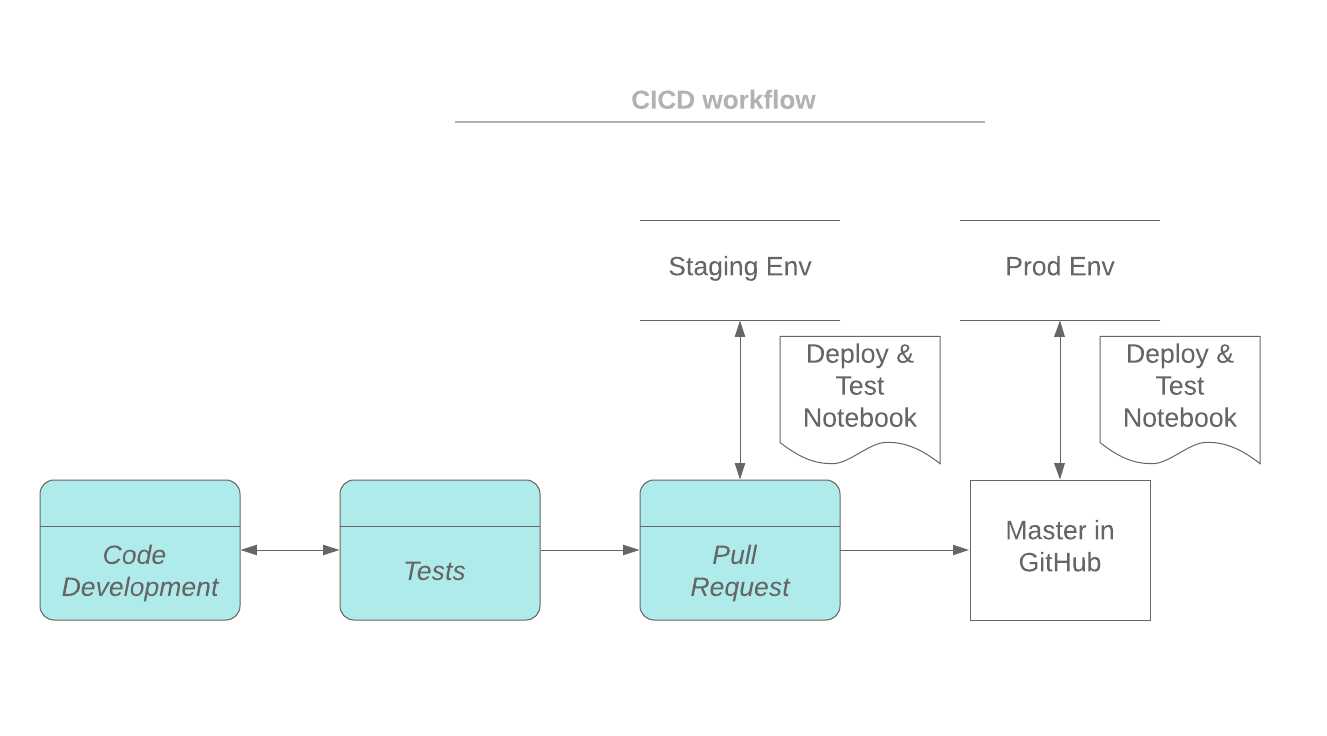 在我们的方法中,部署和测试过程的驱动程序是一个笔记本。驱动程序笔记本可以在自己的集群上运行,也可以在与其他部署笔记本共享的专用高并发集群上运行。笔记本可以手动触发,也可以与构建服务器集成以实现完整的CI/CD实现。输入参数包括部署环境(测试、登台、prod等)、一个实验id (MLflow用它记录消息和工件)以及源代码版本。
在我们的方法中,部署和测试过程的驱动程序是一个笔记本。驱动程序笔记本可以在自己的集群上运行,也可以在与其他部署笔记本共享的专用高并发集群上运行。笔记本可以手动触发,也可以与构建服务器集成以实现完整的CI/CD实现。输入参数包括部署环境(测试、登台、prod等)、一个实验id (MLflow用它记录消息和工件)以及源代码版本。
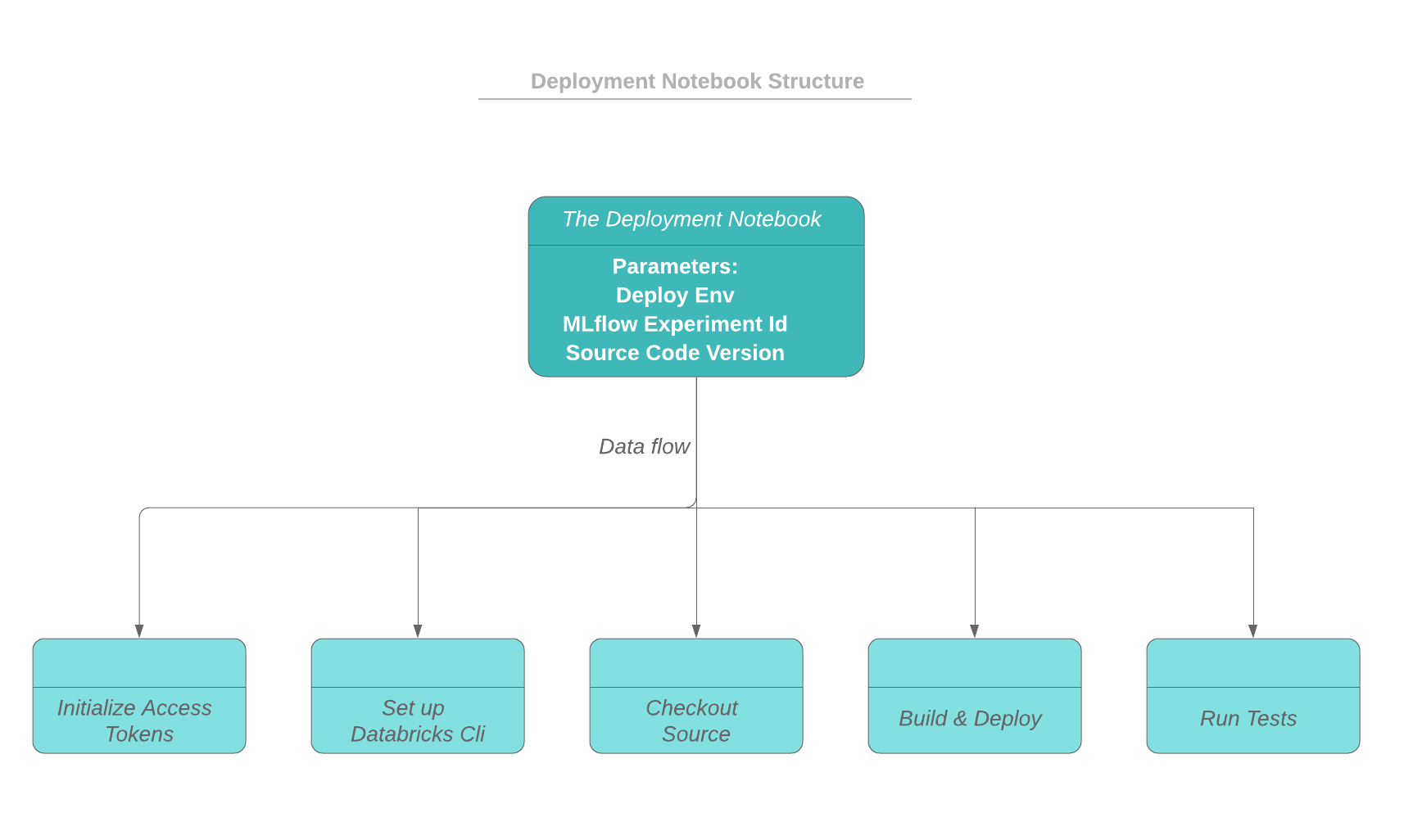
如下面的工作流程所示,驱动程序笔记本首先初始化Databricks工作区和源代码回购(例如github)的访问令牌。构建和部署过程在集群的驱动程序节点上运行,构建构件将部署到dbfs目录。部署状态和消息可以记录为当前MLflow运行的一部分。
部署完成后,可以通过驱动笔记本触发功能和集成测试。测试结果被记录为MLflow实验运行的一部分。可以跟踪来自不同运行的测试结果,并与MLflow进行比较。在本博客中,python和scala代码作为示例提供了如何在测试中利用MLflow跟踪功能。
自动化笔记本部署流程
首先,为部署创建一个uuid和一个专用的工作目录,这样并发部署就彼此隔离了。下面的代码片段展示了如何从MLflow实验的活动运行id分配deploy uuid,以及如何创建工作目录。
进口mlflowActive_run = mlflow.start_run(实验者_id=实验者_id)Deploy_uuid = active_run.info.run_id工作区=“/ tmp /{}”.格式(deploy_uuid)打印(“工作区:{}”.格式(工作区))如果不os.path.exists(工作区):os.mkdir(工作区)为了验证和访问Databricks CLI和Github,您可以设置个人访问令牌。设置CLI身份验证的详细信息可以在以下位置找到:Databricks CLI >设置鉴权.访问令牌应该小心对待。显式地在笔记本中包含令牌可能是危险的。当导出笔记本并与其他用户共享时,令牌可能会意外暴露。
保护令牌的一种方法是将令牌存储在Databricks secrets中。首先需要创建一个范围:
数据库机密create-scope——scope ccid -test
在作用域中存储一个令牌:
Databricks secrets put——scope cicd-test——key token
为了访问存储在秘密中的令牌,dbutils.secrets.get可以利用。获取的令牌在笔记本中显示为[REDACTED]。访问令牌的权限可以使用Secrets ACL定义。有关secrets API的详细信息,请参阅Databricks Secrets API.
下面的代码片段显示了如何从作用域检索秘密:
db_token=dbutils.secrets.get (范围=pipeline_config(“secrets_scope”)键=pipeline_config [" databricks_access_token "])git_username=dbutils.secrets.get (范围=pipeline_config(“secrets_scope”)键=pipeline_config [" github_user "])git_token=dbutils.secrets.get (范围=pipeline_config(“secrets_scope”)键=pipeline_config [" github_access_token "])数据库访问可以通过.databrickscfg文件如下。请注意,每个工作目录都有自己的目录.databrickscfg文件来支持并发部署。
Dbcfg_path = os.path.join(工作区,“.databrickscfg”)与开放(dbcfg_path“w +”)作为f:f.write (“(默认)\ n”)f.write ("host = {}\n".格式(db_host_url))f.write ("token = {}\n".格式(db_token))下面的代码片段展示了如何从Github中检查给定的代码版本的源代码。构建过程不包括在内,但可以在签出步骤之后添加。之后,工件被部署到dbfs位置,笔记本可以导入到Databricks工作空间。
行=“‘#!/bin/bash出口DATABRICKS_CONFIG_FILE = {dbcfg}返回“cd {workspace}/{repo_name}/notebooks/”cd{工作区}/ {repo_name} /笔记本电脑/回声“target_ver_dir = {target_ver_dir}”Databricks工作区删除-r {target_ver_dir}Databricks工作区mkdirs {target_ver_dir}如果[[$?= 0]];然后exit -1;fiDatabricks工作区import_dir {source_dir} {target_ver_dir}“‘.格式(target_base_dir=target_base_dir, git_hash=git_hash, deploy_env=deploy_env, repo_name=repo_name, target_ver_dir=target_ver_dir, git_url=git_url, pipeline_id=pipeline_id, workspace=workspace, dbcfg=dbcfg_path)与开放(“{}/ deploy_notebooks.sh”.格式(工作区),“w +”)作为f:f.writelines(线)进程=子进程。Popen ([“bash”,“{}/ deploy_notebooks.sh”.格式(工作区)],stdout =子流程。管,stderr = subprocess.PIPE)sys.stdout.write (process.communicate () (0])部署跟踪
为了查看部署状态,我们通常会将其存储在数据库中,或者使用某种带有UI的托管部署服务。在我们的例子中,我们可以使用MLflow来实现这些目的。
MLflow跟踪API可以记录部署环境、应用名称、notes等元数据:
试一试:mlflow.log_param (“run_id”active_run.info.run_uuid)mlflow.log_param (“env”deploy_env)mlflow.log_param (“githash”git_hash)mlflow.log_param (“pipeline_id”, pipeline_config [“pipeline-id”])mlflow.log_param (“deploy_note”deploy_note)除了:clean_up (active_run.info.run_uuid)提高触发笔记本
现在我们已经将笔记本部署到工作区路径中,我们需要能够在给定环境下触发笔记本的正确版本。我们可能在prd环境中的版本A上有笔记本,同时在登台环境中测试版本B。
每个部署系统都需要一个真实源,用于每个环境的“已部署”githash的映射。对我们来说,我们利用Databricks Delta,因为它为我们提供了事务性保证。
对于我们来说,我们只需在部署增量表中查找给定环境的githash,并在该路径下运行notebook。
dbutels .notebook.run(PATH_PREFIX + s " ${git_hash}/notebook ",…)
在生产中
在Iterable,我们需要快速行动,尽可能避免设置沉重的基础设施来部署和触发系统。因此,我们与Databricks的Li一起开发了这种方法,这样我们就可以在Databricks内部执行大部分工作流,利用Delta作为数据库,并使用MLflow作为部署状态的视图。
因为我们的数据科学家在Databricks中工作,现在可以在Databricks中部署他们的最新更改,利用MLflow和Databricks笔记本电脑提供的UI,我们能够快速迭代,同时拥有健壮的部署和触发系统,在部署之间没有停机时间。
实现测试
可以通过调用断言语句将测试和验证添加到笔记本中。然而,来自断言的错误消息分散在笔记本上,并且没有可用的测试结果概述。在本节中,我们将向您展示如何从笔记本自动化测试,并使用MLflow跟踪api跟踪结果。
在我们的示例中,驱动程序笔记本作为所有测试的主要入口点。驱动程序笔记本是源代码控制的,可以从部署笔记本调用。在驱动程序笔记本中,定义了一个测试/测试笔记本列表,并循环遍历以运行和生成测试结果。测试可以是一组回归测试和特定于当前分支的测试。驱动程序笔记本处理MLflow作用域的创建,并记录测试结果以正确运行实验。
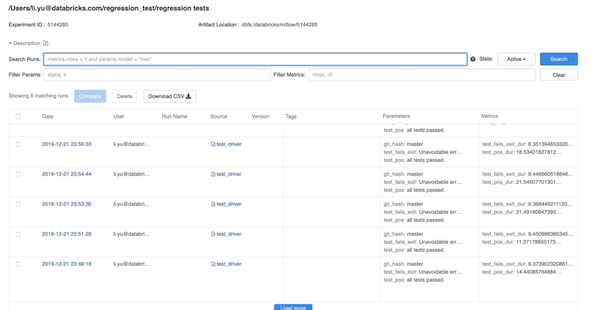
deflog_message(test_name:str味精:str):如果experiment_id:mlflow.log_param (test_name、味精)打印(“{}{}”.格式(msg) test_name)deftest_notebook(notebook_path):进口时间Test_name = get_notebook_name(notebook_path)试一试:Start_time = time.time()Result = dbutils.notebook.run(notebook_path,120, {“egg_file”: egg_file})Elapsed_time = time.time() - start_time .timelog_message (test_name,结果)mlflow.log_metric (“{}_dur”.格式(elapsed_time test_name))除了异常作为艾凡:log_message (test_name“失败”)打印(e)为t在test_notebooks:test_notebook (t)下图显示了MLflow实验的截图,其中包含不同运行的测试结果。每次运行都基于代码版本(git提交),这也作为运行的参数记录下来。
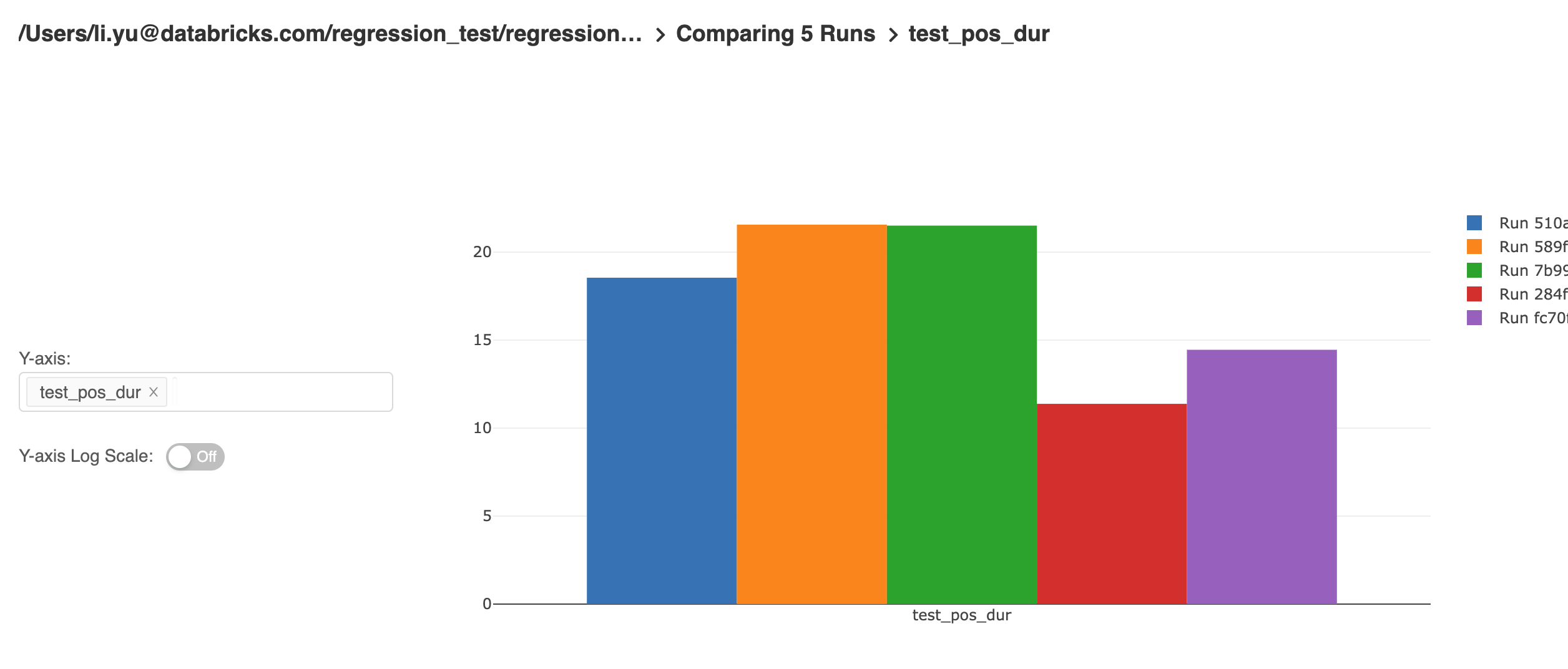
MLflow UI为最终用户提供了探索和分析实验结果的强大功能。结果表可以通过特定的参数和指标进行筛选。来自不同运行的指标可以进行比较,并生成如下所示的指标趋势:
MLflow还跟踪单个函数的单元测试。可以实现一个通用的测试fixture来记录测试的元数据。测试类将继承此公共fixture,以将MLflow跟踪功能包含到测试中。我们当前的实现基于——scalate,尽管类似的实现也可以用其他测试框架完成。
下面的代码示例显示了一个fixture (testTracker)可以通过重写withFixture方法TestSuiteMixin.一个测试函数被传递给withFixture并在内部执行withFixture.这种方式,withFixture服务器作为测试的包装器功能。预处理和后处理代码可以在内部实现withFixture.在我们的例子中,预处理是记录测试的开始时间,后处理是记录测试函数的元数据。任何继承此fixture的测试套件都将在每次测试之前和之后自动运行此fixture,以记录测试的元数据。
进口org.scalatest._进口scala.collection.mutable._特质TestTracker扩展TestSuiteMixin {这:TestSuite= >vartestRuns = scala.collection.mutable.Map[字符串MetricsTrackData] ()varenvVariables:字符串=""//将被实际的测试套件名称覆盖vartestSuiteName:字符串.toString = randomUUID ()
抽象重写def withFixture(test: NoArgTest) = {val ts = System.currentTimeMillis()val t0 = System.nanoTime()vartestRes:布尔=假var例:字符串=""试一试超级.withFixture(test)匹配{情况下结果:结果= >如果(结果。isFailed || result. iscancelled) {val failed = result.asInstanceOf[failed]ex = failed.exception.toString}其他的如果(result.isCanceled) {val cancelled = result.asInstanceOf[取消]ex = cancelled .exception. tostring}其他的如果(结果。isSucceeded) {testRes =真正的}结果情况下其他= >其他}最后{//待办事项:在这里记录你的指标}}def AllTestsPassed ():布尔= {如果(testRuns。大小= =0)真正的其他的{testRuns.values.forall {t= >t.status}}}}一个测试套件需要从TestTracker将日志记录功能合并到其自己的测试中。下面的代码示例展示了如何从上面定义的fixture继承测试元数据日志功能:
类TestClass扩展FlatSpec与TestTracker{“addCountColumns”应该“添加正确的计数”在{//待办事项:在这里测试你的函数/ /维护(…)}}//运行测试Val测试=新TestClasstest.execute ()讨论
在这篇博客中,我们回顾了如何结合Databricks CLI和MLflow构建CI/CD管道。这种方法的主要优点是:
- 将笔记本部署到生产环境,而无需设置和维护构建服务器。
- 自动记录测试的度量。
- 提供测试的查询功能。
- 提供部署状态和测试结果的概述。
- ML算法的性能可以被跟踪和分析(例如检测模型漂移,性能退化)。
使用这种方法,您可以在Databricks环境中快速设置生产管道。您还可以通过为自己的产品化过程添加更多约束和步骤来扩展该方法。
学分
我们要感谢以下贡献者:Denny Lee, Ankur Mathur, Christopher Hoshino-Fish, Andre Mesarovic和Clemens Mewald
免费试用Databricks
相关的帖子