



如何使用MLflow搜索API在仪表板中显示模型指标
机器学习工程师和数据科学家经常训练模型来优化损失函数。通过梯度下降等优化方法,我们迭代地改进…
机器学习工程师和数据科学家经常训练模型来优化损失函数。使用梯度下降等优化方法,我们可以迭代地改进损失,最终达到最小值。你有没有想过:作为一名数据科学家,我能优化自己的生产力吗?或者我可以直观地看到我的训练模型的指标的进展吗?
MLflow允许您跟踪训练运行,并为常见指标比较提供开箱即用的可视化,但有时您可能希望提取MLflow标准可视化未涵盖的其他见解。在这篇文章中,我们将向您展示如何使用MLflow跟踪您或您的团队在训练机器学习模型方面的进展。
的MLflow跟踪API使您的运行可搜索,并返回结果作为一个方便熊猫DataFrame.我们将利用此功能生成一个仪表板,显示在平均绝对误差(MAE)等关键指标上的改进,并向您展示如何测量每个实验启动的运行次数以及团队所有成员的运行次数。
一些机器学习工程师和研究人员在一组电子表格中跟踪模型精度结果,用用于生成这些结果的超参数和训练集手动注释结果。随着时间的推移,随着团队的增长和实验运行次数的相应增加,手动簿记可能会变得很麻烦。
然而,当你使用MLflow跟踪API,在一个实验中你所有的训练运行都被记录下来。使用这个API,您可以生成一个熊猫DataFrame任何实验的运行次数。例如,mlflow.search_runs(…)返回一个熊猫。DataFrame,可以显示在笔记本中,也可以作为控件访问单个列熊猫。系列.
Runs = mlflow.search_runs(实验者id =实验者id)runs.head (10)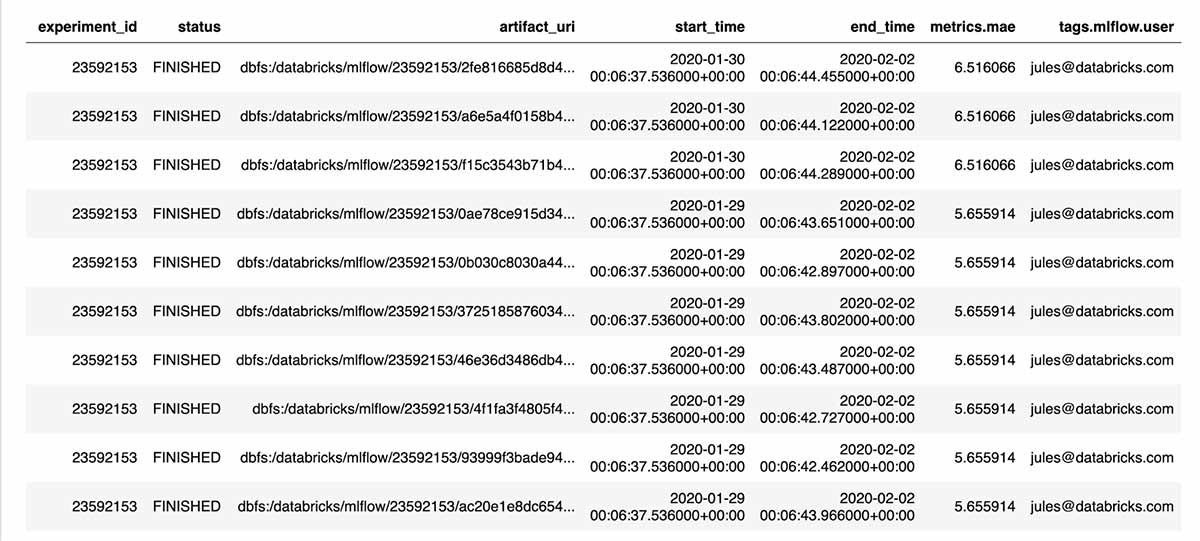
有了这个编程界面,很容易回答诸如“迄今为止性能最好的模型是什么?”
Runs = mlflow.search_runs(实验者id =实验者id,order_by = [“metrics.mae”), max_results =1)runs.loc [0]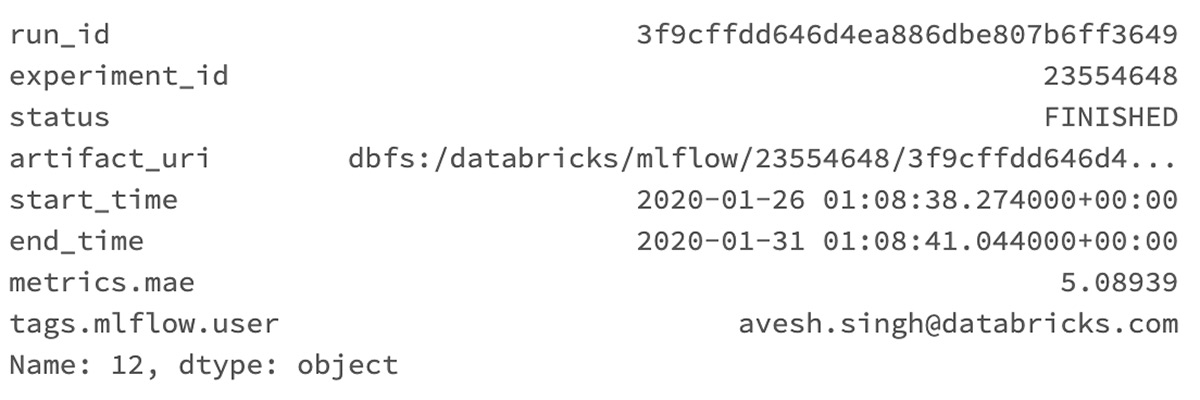
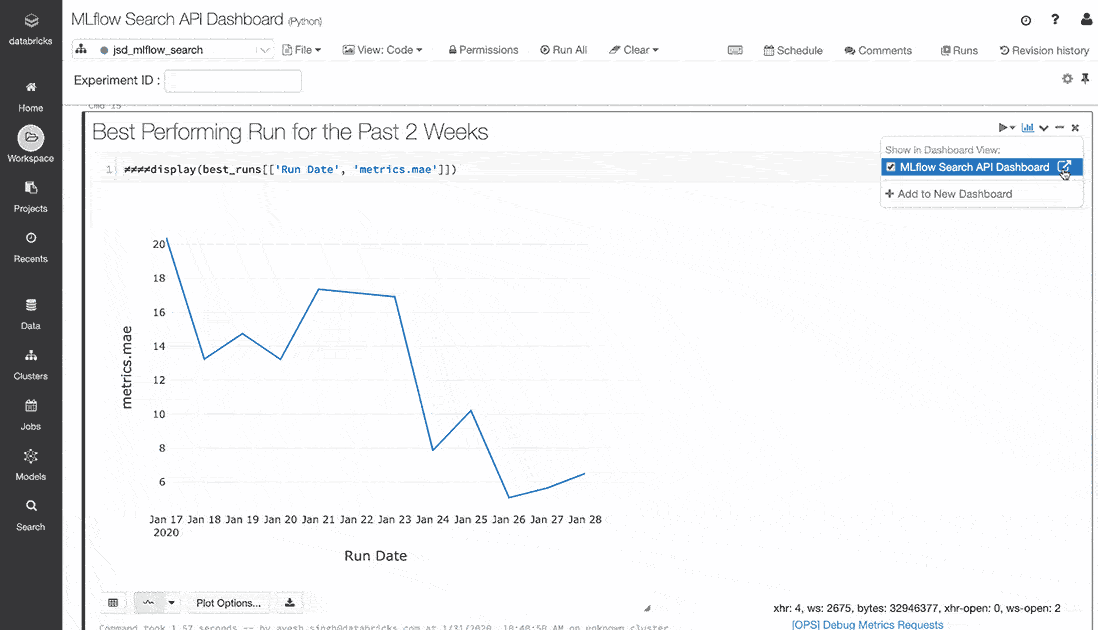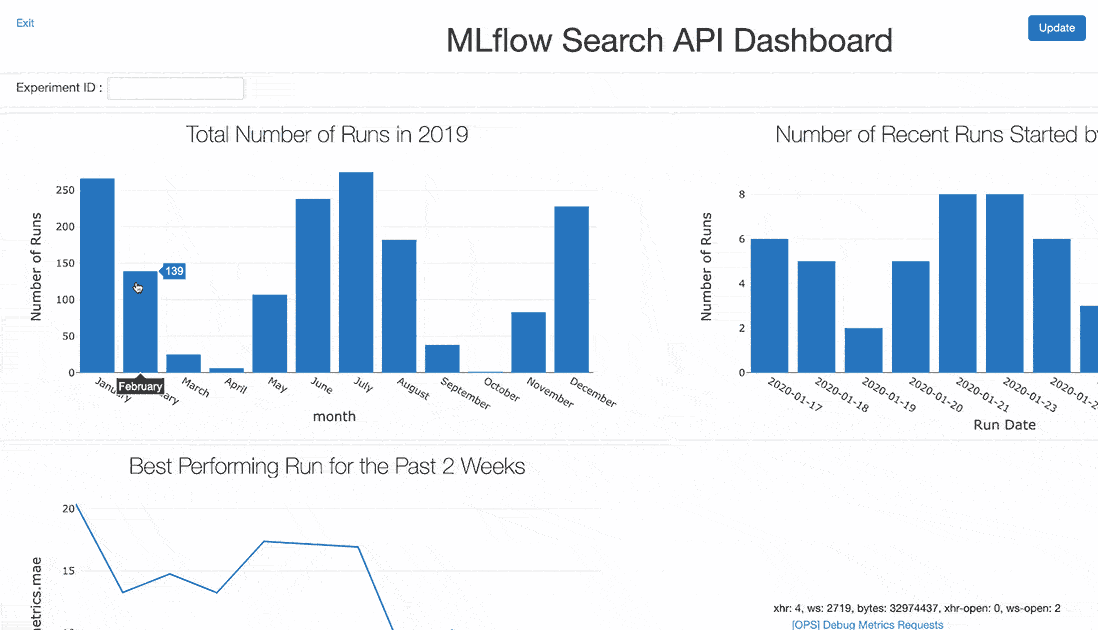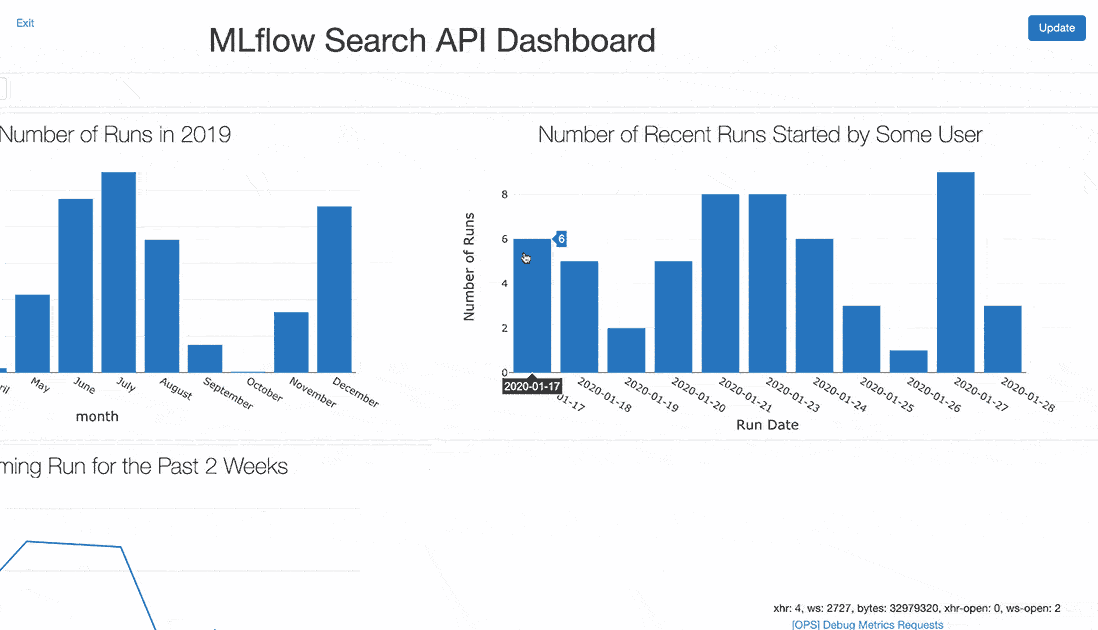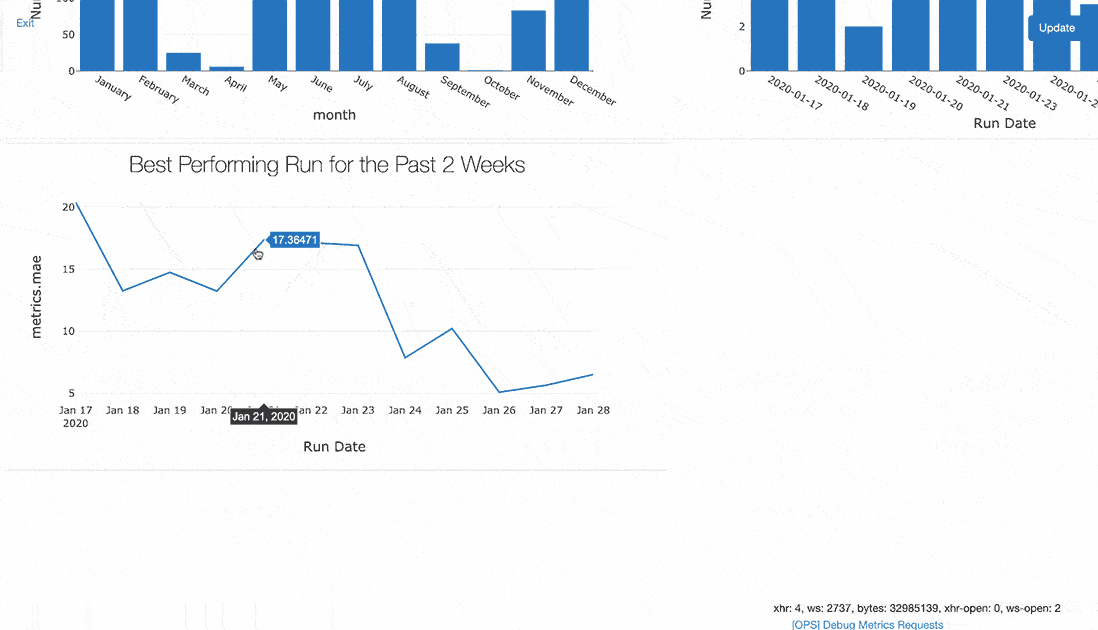
使用pandas DataFrame聚合和Databricks笔记本显示函数,您可以看到顶线精度度量随时间的改进。这个示例跟踪了过去两周内优化MAE的进展。
earliest_start_time=(datetime.now ()-timedelta(天=14) .strftime (' % Y - % - % d ')recent_runs=运行[runs.start_time> =earliest_start_time]recent_runs [“运行时间”]=recent_runs.start_time.dt。地板上(频率=' D ')best_runs_per_day_idx=recent_runs.groupby ([“运行时间”]) [“metrics.mae”] .idxmin ()best_runs=recent_runs.loc [best_runs_per_day_idx]显示器(best_runs [[“运行时间”,“metrics.mae”]])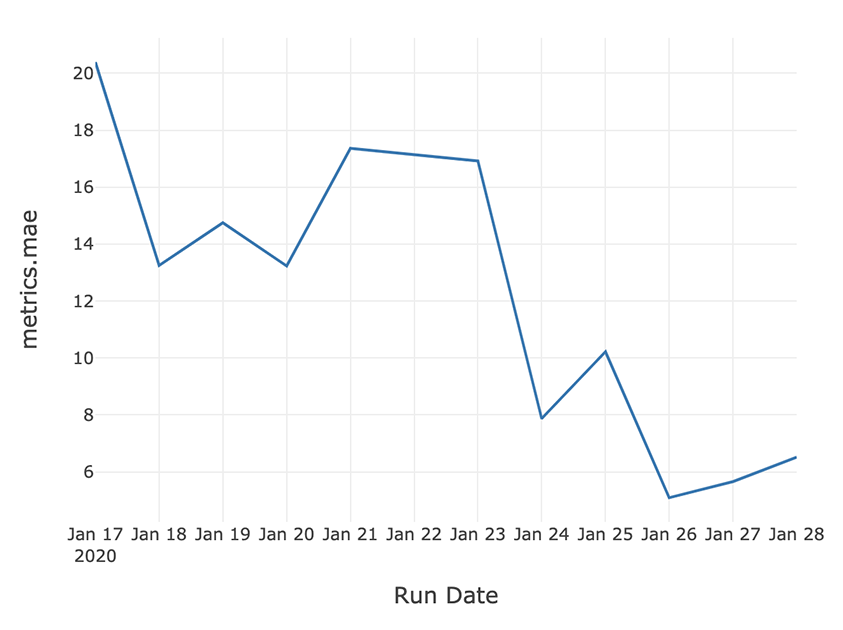
如果您正在运行开源MLflow,则可以bob下载地址使用matplotlib而不是显示功能,该功能仅在Databricks笔记本电脑中可用。
进口matplotlib.pyplot作为pltplt.plot (best_runs [“运行时间”], best_runs [“metrics.mae”])plt.xlabel (“运行时间”)plt.ylabel (“metrics.mae”)plt.xticks(旋转=45)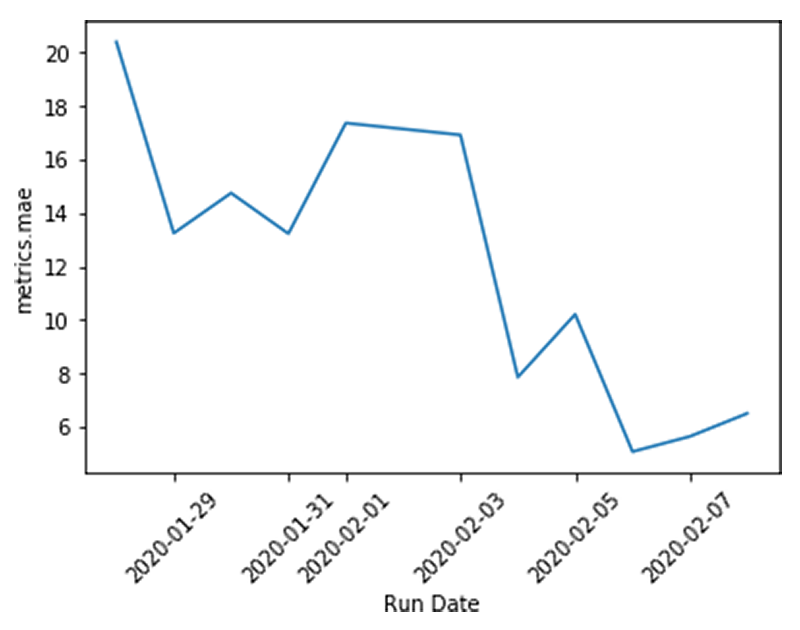
在机器学习建模中,顶线度量改进并不是实验的确定性结果。有时几周的工作没有明显的改善,而在其他时候,对参数的调整意外地带来了相当大的收益。在这样的环境中,重要的是不仅要衡量结果,还要衡量过程。
这一过程的一个衡量标准是每天启动的实验次数。
earliest_start_time=(datetime.now ()-timedelta(天=14) .strftime (' % Y - % - % d ')recent_runs=运行[runs.start_time> =earliest_start_time]recent_runs [“运行时间”]=recent_runs.start_time.dt。地板上(频率=' D ')runs_per_day=recent_runs.groupby ([“运行时间”]).数() [[“run_id”]] .reset_index ()runs_per_day [“运行时间”]=runs_per_day [“运行时间”] .dt.strftime (' % Y - % - % d ')runs_per_day.rename ({“run_id”:“运行次数”},轴=“列”,原地=真正的)
显示器(runs_per_day)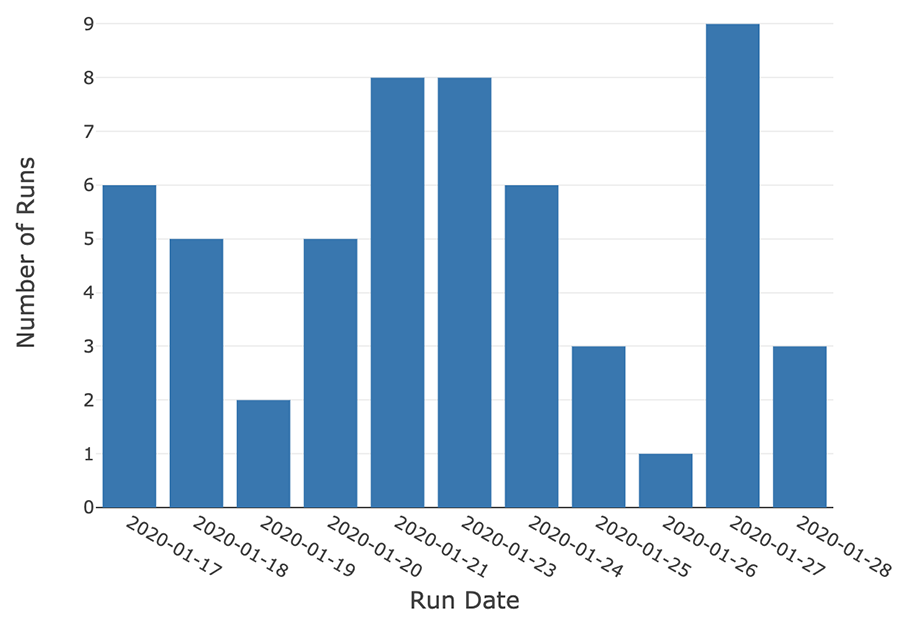
扩展此示例,您可以跟踪任何用户在较长时间内启动的运行总数。
运行=mlflow.search_runs (experiment_ids=experiment_id)runs_2019=[(runs.start_time=“2019-01-01”)]runs_2019 [“月”]=runs_2019.start_time.dt.month_name ()runs_2019 [“month_i”]=runs_2019.start_time.dt.monthruns_per_month=runs_2019.groupby ([“month_i”,“月”]).数() [[“run_id”]] .reset_index (“月”)runs_per_month.rename ({“run_id”:“运行次数”},轴=“列”,原地=真正的)
显示器(runs_per_month)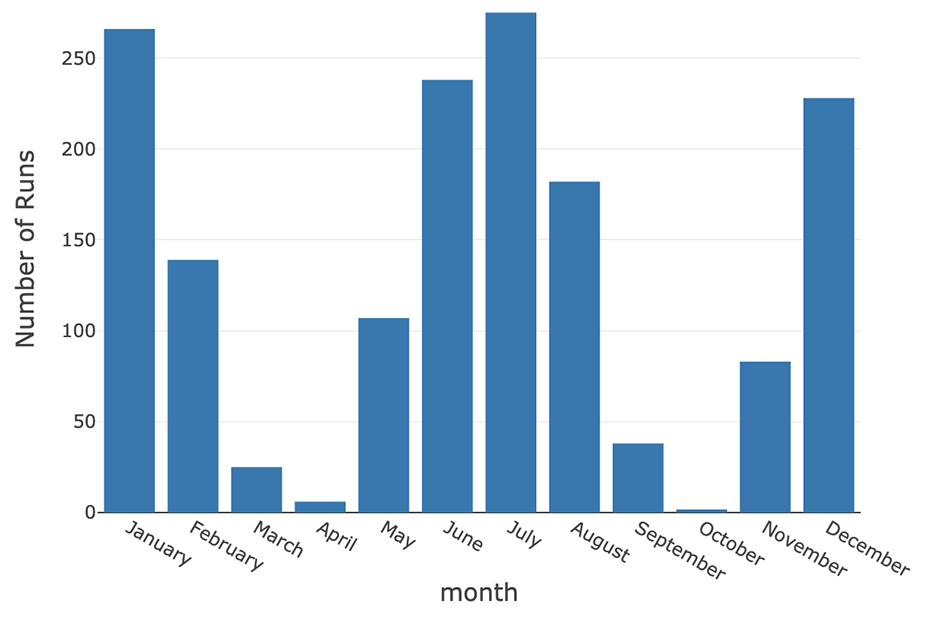
使用上面的显示,你可以建立一个显示你结果的许多方面的仪表板。这样的仪表板计划每天刷新,在截止日期前或团队冲刺期间作为共享显示被证明是有用的。
如果不跟踪和测量运行和结果,机器学习建模和实验可能会变得混乱且容易出错,特别是当结果在电子表格、纸上手动跟踪时,或者有时根本不跟踪。使用MLflow跟踪和搜索api,您可以轻松地搜索过去的训练运行,并构建使您或您的团队更具生产力的仪表板,并提供模型指标的可视化进展。
贡献:Max Allen是MLflow工程团队的工程实习生。
在去年的实习期间,他实现了MLflow搜索API,我们将在本博客中对此进行演示。
准备好开始或者自己尝试了吗?您可以在一个可运行的笔记本上看到本文中使用的示例AWS或Azure.
如果您是MLflow的新手,请阅读使用最新的MLflow 1.6快速入门.有关生产用例,请阅读相关内容在Databricks上管理MLflow.