





Azure Databricks数据泄露保护
在之前的博客中,我们讨论了如何使用虚拟网络服务端点或私有…从Azure Databricks安全地访问Azure数据服务。
2020年3月27日 在工程的博客
在以前的博客,我们讨论了如何从Azure Databricks使用安全访问Azure数据服务虚拟网络服务端点或私人联系.在本文中,我们给出了这些最佳实践的基线,详细介绍了如何从网络安全的角度加强Azure Databricks部署,以防止数据泄露。
按维基百科:当恶意软件和/或恶意行为者从计算机进行未经授权的数据传输时,就会发生数据泄露。通常也称为数据挤压或数据导出。数据泄露也被认为是数据盗窃的一种形式。自2000年以来,大量数据泄露事件严重损害了世界各地的消费者信心、企业估值、企业知识产权和政府的国家安全。随着企业开始使用公共云服务存储和处理敏感数据(PII、PHI或战略机密),这个问题变得更加重要.
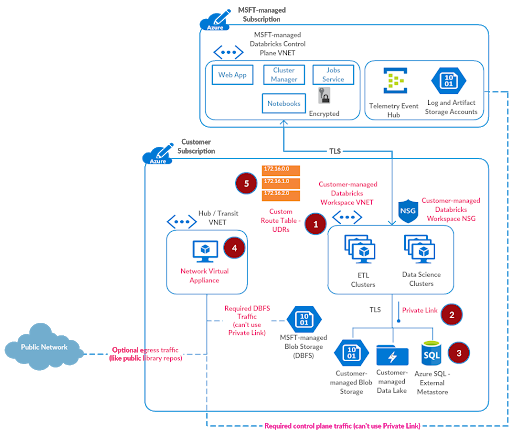
如果PaaS服务要求您将数据存储在PaaS服务中,或者PaaS服务在服务提供商的网络中处理数据,那么解决数据泄露问题就变得难以管理。但通过Azure Databricks,我们的客户可以将所有数据保存在他们的Azure订阅中,并在自己管理的私有虚拟网络中处理这些数据,同时保留Azure上增长最快的数据和AI服务的PaaS性质。在与一些最注重安全的客户合作的同时,我们已经为平台提出了一个安全的部署架构,现在是时候广泛地分享它了。bob体育客户端下载
我们建议轮辐拓扑样式的参考体系结构.集线器虚拟网络包含连接到经过验证的源和可选的本地环境所需的共享基础设施。辐条虚拟网络与中心对等,同时为不同的业务单元或隔离的团队提供隔离的Azure Databricks工作空间。
高级艺术观的可能:
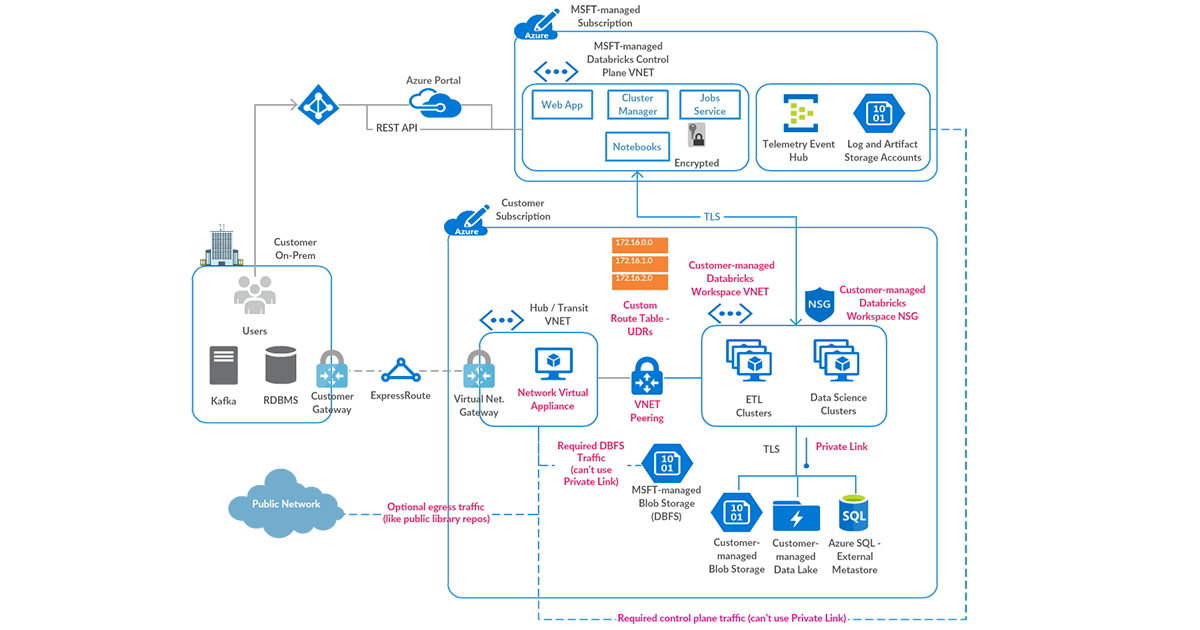
以下是设置安全Azure Databricks部署的高级步骤(参见下面的相应图表):
•应用程序规则定义了可以通过防火墙访问的完全限定域名(fqdn)。一些Azure Databricks所需的流量可以使用应用程序规则被列入白名单。
•网络规则为不能使用fqdn配置的端点定义IP地址、端口和协议。需要使用网络规则将一些必需的Azure Databricks流量列入白名单。
我们的一些客户更喜欢使用第三方防火墙设备,而不是Azure防火墙,后者通常工作得很好。不过请注意,每个产品都有自己的细微差别,最好让相关的产品支持和网络安全团队来解决任何相关问题。
•为Azure防火墙子网设置Azure存储的服务端点,以便所有流量到白名单区域或in-paired-region存储通过Azure网络骨干网(如果客户数据平面区域是匹配或配对的,则包括Azure Databricks控制平面中的端点)。
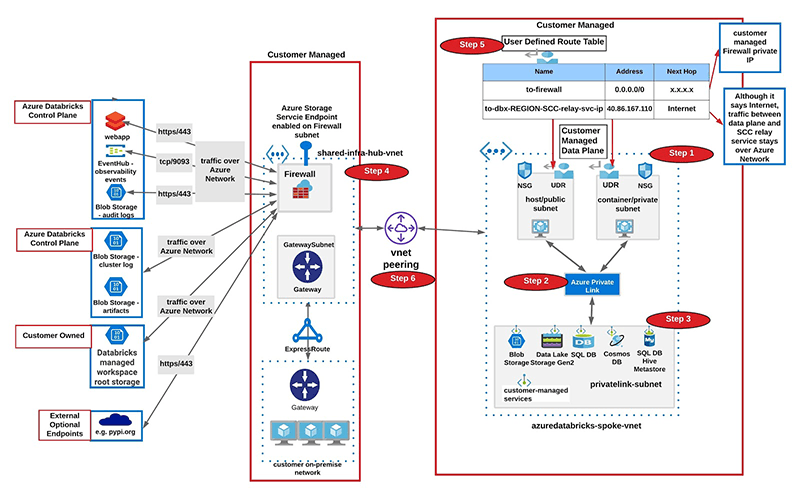
这样的中心辐射型架构允许为不同的目的和团队创建多个辐射型vnet。尽管我们已经看到一些客户通过为大型连续虚拟网络中的不同团队创建单独的子网来实现隔离。在这种情况下,完全可以在各自的子网对中设置多个隔离的Azure Databricks工作空间,并在同一虚拟网络中的另一个姐妹子网中部署Azure防火墙。
下面我们将更详细地讨论上面的设置。
请从这里记录工作空间的Azure Databricks控制平面端点(根据工作空间的区域进行映射)。稍后我们将需要这些详细信息来配置Azure防火墙规则。
| 的名字 | 源 | 目的地 | 协议:港口 | 目的 |
| databricks-webapp | Azure Databricks工作区子网 | 特定于区域的Webapp端点 | https: 443 | 与Azure Databricks webapp通信 |
| databricks-webapp | Azure Databricks工作区子网 | 特定于区域的Webapp端点 | https: 443 | 与Azure Databricks webapp通信 |
| databricks-observability-eventhub | Azure Databricks工作区子网 | 区域特定的可观察性事件中心端点 | https: 9093 | Azure Databricks集群上特定于服务的遥测传输 |
| databricks-artifact-blob-storage | Azure Databricks工作区子网 | 特定于区域的工件Blob存储端点 | https: 443 | 存储要部署到集群节点上的Databricks Runtime映像 |
| databricks-dbfs | Azure Databricks工作区子网 | DBFS Blob存储端点 | https: 443 | Azure Databricks工作区根存储 |
| databricks-sql-metastore (可选-请参见下面的步骤3 External Hive Metastore) |
Azure Databricks工作区子网 | 区域特定的SQL Metastore端点 | tcp: 3306 | 在Azure Databricks工作区中存储数据库和子对象的元数据 |
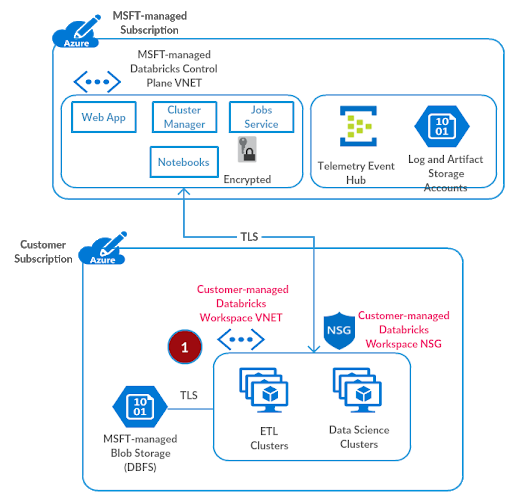
Azure Databricks的默认部署在Databricks管理的资源组中创建一个新的虚拟网络(包含两个子网)。为了对安全部署进行必要的定制,工作区数据平面应该部署在您自己的虚拟网络中.这个快速入门展示了如何在几个简单的步骤中做到这一点。在此之前,你应该创建虚拟网络命名为azuredatabicks -spoke-vnet,带有地址空间10.2.1.0/24在资源组中adblabs-rg(名称和地址空间是特定于这个测试设置的)。


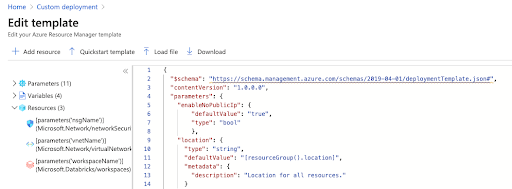
" enableNoPublicIp ": {
“defaultValue”:“真实的”,
“类型”:“bool”
}
向下滚动到底部,在工作区属性部分添加:
" enableNoPublicIp ": {
"value": "[parameters(' enablenoppublicip ')]"}
}
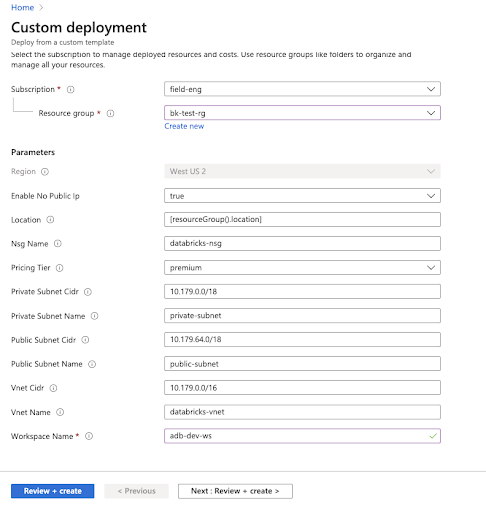
| 设置 | 建议值 | 描述 |
| 工作区名称 | adblabs-ws | 为Azure Databricks工作区选择一个名称。 |
| 订阅 | “你的订阅” | 选择要使用的Azure订阅。 |
| 资源组 | adblabs-rg | 选择用于虚拟网络的相同资源组。 |
| 位置 | 美国中部 | 选择与虚拟网络相同的位置。 |
| 开启无公网IP | 真正的 | 在Azure Databricks集群节点上禁用公共ip。 |
| 定价层 | 溢价 | 有关定价等级的更多信息,请参阅Azure Databricks定价页面. |
在虚拟网络(VNet)中部署Azure Databricks工作区是的此设置允许您在虚拟网络中部署Azure Databricks工作空间。
| 设置 | 价值 | 描述 |
| 虚拟网络 | azuredatabricks-spoke-vnet | 选择前面创建的虚拟网络。 |
| 公网子网名称 | public-subnet | 使用默认的公共子网名称,您也可以使用任何名称。 |
| 公共子网CIDR范围 | 10.2.1.64/26 | 使用CIDR范围高达/26。 |
| 私有子网名称 | 的子网 | 使用默认的私有子网名称,您也可以使用任何名称。 |
| 私有子网CIDR范围 | 10.2.1.128/26 | 使用CIDR范围高达/26。 |
点击回顾和创造。有几点需要注意:
如前所述在安全访问Azure数据服务博客中,我们将使用Azure私有链接将以前创建的Azure Databricks工作空间安全地连接到您的Azure数据服务。我们不建议通过网络虚拟设备/防火墙来设置对此类数据服务的访问,因为这可能会对大数据工作负载和中间基础设施的性能产生不利影响。
请创建子网privatelink-subnet地址空间10.2.1.0/26在虚拟网络中azuredatabricks-spoke-vnet.
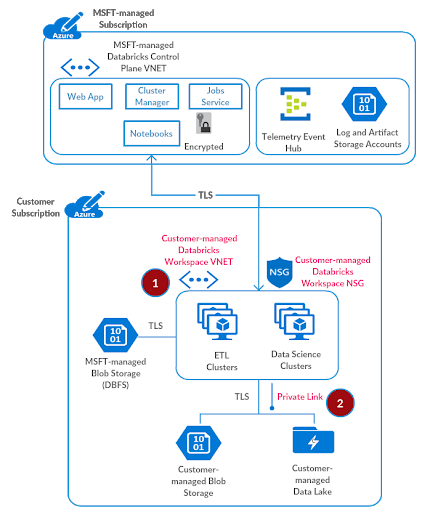
对于测试设置,我们将部署一个示例存储帐户,然后为此创建一个Private Link端点。参考私有链接的设置文档:
资源groupSelectadblabs-rg.您在前一节中创建了这个。
| 设置 | 价值 |
| 项目详细信息 | |
| 订阅 | 选择您的订阅。 |
| 实例细节 | |
| 存储帐户名称 | 输入myteststorageaccount.如果使用此名称,请提供唯一的名称。 |
| 地区 | 选择美国中部(或用于Azure Databricks工作空间和虚拟网络的相同区域)。 |
| 性能 | 保持默认标准。 |
| 复制 | 选择“读访问两地冗余存储(RA-GRS)”。 |
选择第二:网络>
项目详细信息
| 设置 | 价值 |
| 订阅 | 选择您的订阅。 |
| 资源组 | 选择adblabs-rg.您在前一节中创建了这个。 |
| 位置 | 选择美国中部(或用于Azure Databricks工作空间和虚拟网络的相同区域)。 |
| 的名字 | 输入myStoragePrivateEndpoint. |
| 存储sub-resource | 选择dfs。 |
| 网络 | |
| 虚拟网络 | 选择azuredatabricks-spoke-vnet来自资源组adblabs-rg. |
| 子网 | 选择privatelink-subnet. |
| 私有DNS集成 | |
| 与专用DNS区域集成 | 保持默认值是的. |
| 私有DNS区域 | 保留默认值(新建)privatelink.dfs.core.windows.net. |
选择好吧.
可以为受支持的Azure数据服务创建多个私有链接端点。要为其他服务配置这样的端点,请参考相关的Azure文档。
这一步是可选的。默认情况下,Azure Databricks工作区使用合并的区域metastore。如果您希望避免为这个端到端部署管理Azure SQL数据库,请跳到下一步。
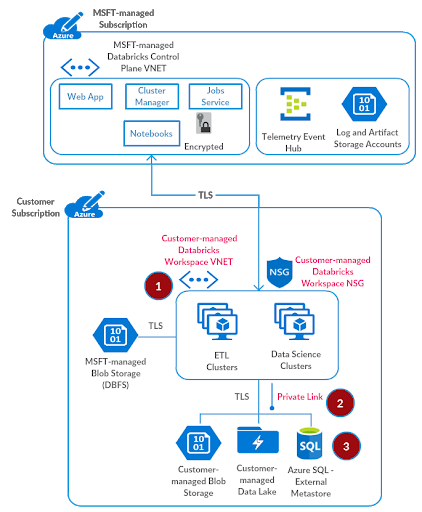
参考配置Azure SQL数据库文档,请提供一个Azure SQL数据库,我们将使用它作为Azure Databricks工作空间的外部hive metastore。
| 设置 | 价值 |
| 数据库的细节 | |
| 订阅 | 选择您的订阅. |
| 资源组 | 选择adblabs-rg。您在前一节中创建了这个。 |
| 实例细节 | |
| 数据库名称 | 输入myhivedatabase。如果使用此名称,请提供唯一的名称。 |
| 设置 | 价值 |
| 服务器名称 | 输入mysqlserver。如果使用此名称,请提供唯一的名称。 |
| 服务器管理员登录 | 输入您选择的管理员名。 |
| 密码 | 输入您选择的密码。密码长度至少为8个字符,满足密码设置要求。 |
| 位置 | 选择美国中部(或用于Azure Databricks工作空间和虚拟网络的相同区域)。 |
选择好吧.
在本节中,您将为上面创建的Azure SQL数据库添加一个Private Link端点。从这个来源引用
| 设置 | 价值 |
| 项目详细信息 | |
| 订阅 | 选择您的订阅。 |
| 资源组 | 选择adblabs-rg。您在前一节中创建了这个。 |
| 实例细节 | |
| 的名字 | 输入mySqlDBPrivateEndpoint。如果使用此名称,请提供唯一的名称。 |
| 地区 | 选择美国中部(或用于Azure Databricks工作空间和虚拟网络的相同区域)。 |
| 选择下一个:资源 |
在创建私有端点-资源,输入或选择此信息:
| 设置 | 价值 |
| 连接方法 | 选择“连接到我目录中的Azure资源”。 |
| 订阅 | 选择您的订阅。 |
| 资源类型 | 选择Microsoft.Sql /服务器。 |
| 资源 | 选择mysqlserver |
| 目标sub-resource | 选择sqlServer |
选择下一个:配置
在创建私有端点-配置,输入或选择此信息:
网络
| 设置 | 价值 | |||||||
| 虚拟网络 | 选择azuredatabricks-spoke-vnet | 子网 | 选择privatelink-subnet | 私有DNS集成 | 与专用DNS区域集成 | 选择Yes。 | 私有DNS区域 | 选择(新)privatelink.database.windows.net |
我们建议Azure防火墙作为一个可扩展的云防火墙,作为Azure Databricks控制平面流量、DBFS存储和任何允许从Azure Databricks工作空间访问的公共端点的过滤设备。
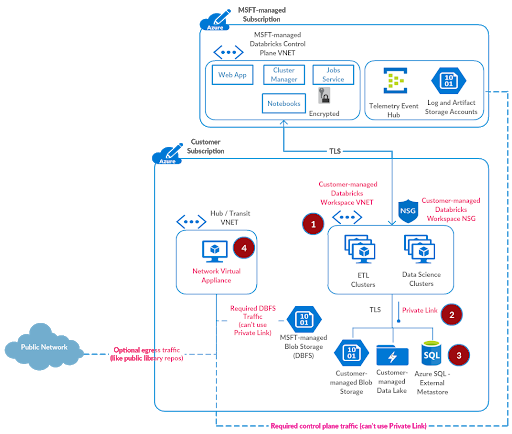
参考配置Azure防火墙的文档,您可以将Azure防火墙部署到新的虚拟网络中。请创建虚拟网络命名hub-vnet地址空间10.3.1.0/24在资源组中adblabs-rg(名称和地址空间是特定于这个测试设置的)。还要创建一个名为AzureFirewallSubnet地址空间10.3.1.0/26在hub-vnet.
| 设置 | 价值 |
| 订阅 | “你的订阅” |
| 资源组 | adblabs-rg |
| 的名字 | 防火墙 |
| 位置 | 选择美国中部(或用于Azure Databricks工作空间和虚拟网络的相同区域)。 |
| 选择虚拟网络 | 使用现有的:hub-vnet |
| 公网IP地址 | 添加新的。公网IP地址必须为“Standard SKU”类型。它的名字fw-public-ip |
使用Azure防火墙,您可以配置:
我们首先需要配置应用程序规则以允许出站访问日志Blob存储而且工件Blob存储Azure Databricks控制平面中的端点加上DBFS根块存储对于工作空间。
| 的名字 | 源type | 源 | 协议:港口 | 目标的fqdn |
| databricks-spark-log-blob-storage | IP地址 | Azure Databricks工作区子网 10.2.1.128/26, 10.2.1.64/26 |
https: 443 | 参考上述先决条件中的注意事项(适用于美国中部) |
| databricks-audit-log-blob-storage | IP地址 | Azure Databricks工作区子网 10.2.1.128/26, 10.2.1.64/26 |
https: 443 | 参考上述先决条件中的注意事项(适用于美国中部) 这是目前仅针对美国地区的单独日志存储 |
| databricks-artifact-blob-storage | IP地址 | Azure Databricks工作区子网 10.2.1.128/26, 10.2.1.64/26 |
https: 443 | 参考上述先决条件中的注意事项(适用于美国中部) |
| databricks-dbfs | IP地址 | Azure Databricks工作区子网 10.2.1.128/26, 10.2.1.64/26 |
https: 443 | 参考上述先决条件中的注意事项 |
| Python和R库的公共存储库 (可选-如果工作空间用户被允许从公共回购中安装库) |
IP地址 | 10.2.1.128/26, 10.2.1.64/26 | https: 443 | * pypi.org, pythonhosted.org, cran.r-project.org 根据需要添加任何其他公共回购 |
| 所使用的神经节用户界面 | IP地址 | 10.2.1.128/26, 10.2.1.64/26 | https: 443 | Cdnjs.com或cdnjs.cloudflare.com |
有些端点不能使用fqdn配置为应用程序规则。我们将这些设置为网络规则,即可观测性事件中心而且Webapp.
| 的名字 | 协议 | 源类型 | 源 | 目的地类型 | 目的地址 | 目的地港口 |
| databricks-webapp | TCP | IP地址 | Azure Databricks工作区子网 10.2.1.128/26, 10.2.1.64/26 |
IP地址 | 参考上述先决条件中的注意事项(适用于美国中部) | 443 |
| databricks-observability-eventhub | TCP | IP地址 | Azure Databricks工作区子网 10.2.1.128/26, 10.2.1.64/26 |
IP地址 | 参考上述先决条件中的注意事项(适用于美国中部) | 9093 |
| databricks-sql-metastore (可选-请参见上面的步骤3 External Hive Metastore) |
TCP | IP地址 | Azure Databricks工作区子网 10.2.1.128/26, 10.2.1.64/26 |
IP地址 | 参考上述先决条件中的注意事项(适用于美国中部) | 3306 |

服务端点将允许来自AzureFirewallSubnet来日志Blob存储,工件Blob存储,DBFS存储通过Azure网络骨干网,从而消除对公共网络的暴露。
如果用户要访问使用服务主体的Azure存储,那么我们建议从Azure Databricks工作区子网创建一个额外的服务端点到微软。AzureActiveDirectory.
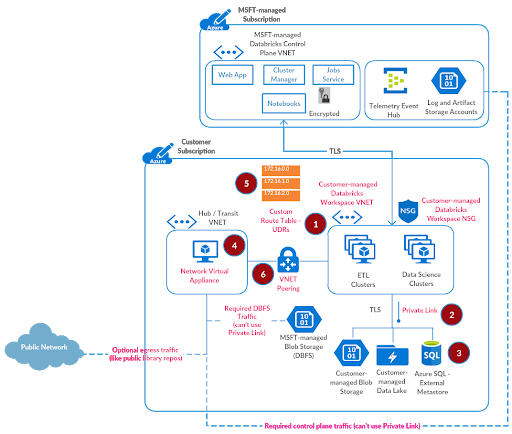
至此,用于安全、锁定部署的大部分基础设施设置已经完成。我们现在需要将适当的流量从Azure Databricks工作区子网路由到控制平面SCC中继IP(见下面的常见问题解答)和Azure防火墙设置。
参考用户定义路由的文档:
现在再添加一条路由Azure Databricks SCC中继IP.
路由表需要与两个Azure Databricks工作区子网相关联。
我们现在到了最后一步。虚拟网络azuredatabricks-spoke-vnet而且hub-vnet为了使前面配置的路由表能够正常工作,需要对路由表进行对等。
在Azure门户顶部的搜索框中,输入虚拟网络在搜索框中。当虚拟网络出现在搜索结果中时,选择该视图。
| 的名字 | 价值 |
| 从hub-vnet对等到远端虚拟网络的名称 | from-hub-vnet-to-databricks-spoke-vnet |
| 虚拟网络部署模型 | 资源管理器 |
| 订阅 | 选择订阅 |
| 虚拟网络 | azuredatabricks-spoke-vnet或选择部署Azure Databricks的VNET |
| 从远端虚拟网络对等到hub-vnet的名称 | from-databricks-spoke-vnet-to-hub-vnet |
设置现在已经完成。
现在是时候测试一切了:
如果数据访问没有任何问题,这意味着您已经在订阅中完成了Azure Databricks的最佳安全部署。这是相当多的手工工作,但这更像是一次展示。在实际应用中,你会想要使用ARM模板、Azure CLI、Azure SDK等的组合来自动化这样的设置:
我是否可以使用服务端点策略来保护到Azure数据服务的数据出口?
是的,只有VNet注入。服务端点策略通过Azure骨干网上的优化路由,提供到Azure服务的安全、直接连接。服务端点可用于仅保护到您的虚拟网络的外部Azure资源的连接。服务端点只有在使用服务端点与为Azure服务正确定义的网络防火墙规则结合使用时才安全。服务端点不能在标准部署中使用,因为虚拟网络是受管理的,不能应用于Databricks根DBFS存储。
我可以使用网络虚拟设备(NVA)而不是Azure防火墙吗?
是的,只要按照本文所讨论的配置网络流量规则,您就可以使用第三方NVA。请注意,我们只在Azure防火墙上测试了这个设置,尽管我们的一些客户使用其他第三方设备。理想的情况是将设备部署在云中,而不是部署在本地。
我可以在与Azure Databricks相同的虚拟网络中拥有防火墙子网吗?
是的,你可以。按Azure参考体系结构,建议采用轮辐式虚拟网络拓扑结构,以便更好地规划未来。如果您选择在与Azure Databricks工作区子网相同的虚拟网络中创建Azure防火墙子网,则不需要像上面第6步中讨论的那样配置虚拟网络对等。
我可以通过Azure防火墙过滤Azure Databricks控制平面SCC中继ip流量吗?
是的,你可以,但我们不建议这样做,因为:
我可以分析Azure防火墙接受或阻止的流量吗?
我们建议使用Azure防火墙日志和度量对于这个要求。
我们讨论了利用云原生安全控制为Azure Databricks部署实现数据泄露保护,所有这些都可以自动化,以支持大规模的数据团队。在这个项目中,你可能需要考虑和实现的其他一些事情:
如有任何问题,请与Microsoft或Databricks客户团队联系。