
在Databricks自动化随叫随到的工程工作流程

一个自愈的夏天
今年夏天,我在云基础设施团队实习。该团队负责构建可扩展的基础设施,以支持Databricks的多云产品,同时使用与云无关的技术,如Terraform和Kubernetes。我的主要工作是开发一种新的自动补救服务,疗愈者,自动维修我们的Kubernetes基础设施,以提高我们的服务可用性,减少随叫随到的负担。
自动减少停机和停机时间
Databricks的云基础设施团队负责所有Databricks的底层计算基础设施,管理跨云和区域的数千个虚拟机和数据库实例。作为分布式系统中的组件,这些云管理的资源预计会不时出现故障。随叫随到的工程师有时会执行重复的任务来解决这些预期的事故。当PagerDuty警报触发时,随叫随到的工程师通过遵循记录好的剧本手动解决问题。
尽管理想情况下,我们希望追踪并修复每个问题的根本原因,但这样做的成本将高得令人望而却步。对于这一长尾问题,我们反而依赖于解决症状并控制它们的剧本。在某些情况下,根本原因是我们合作的许多开源项目中的一个已知问题(如Kubernetes, Prometheus, Envoy, Consul, Hashicorp Vault),所以一个变通方案是唯一可行的选择。
待命页面需要我们的工程师仔细关注。数据工程根据优先级对问题进行分类。低优先级的问题只会在工作时间出现(也就是说,工程师不会在晚上被叫醒!)例如,如果一个Kubernetes节点在我们的开发环境中损坏了,那么随叫随到的工程师只会在第二天早上收到警报,以便对问题进行分类。由于Databricks工程分布在世界各地(在旧金山、多伦多和阿姆斯特丹都有办公室),大多数团队都在一个办公室工作,开发环境的问题可能会阻碍某些工程师工作几个小时,降低开发人员的工作效率。
我们一直在寻找减少“保持照明”(KTLO)负担的方法,因此设计一个无需人工干预就能响应警报的系统,通过执行工程师定义的策略手册来管理我们这种规模的资源非常有意义。我们开始设计一个系统来帮助我们解决这些系统性问题。
自愈体系结构
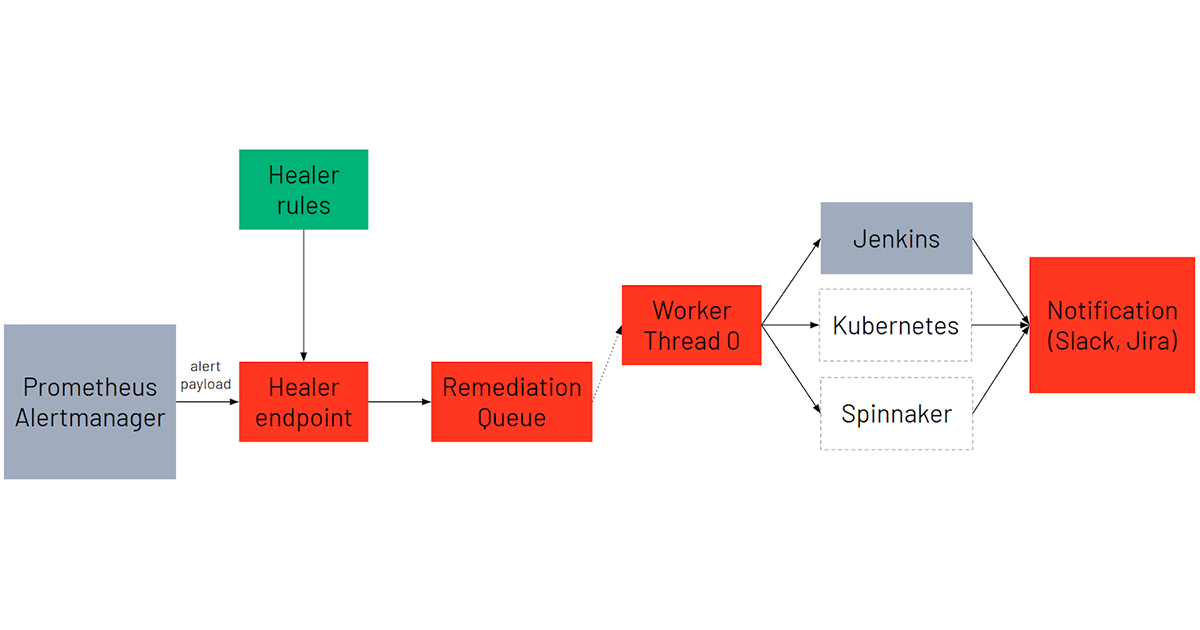
Healer是使用事件驱动的架构设计的,可以自动修复Kubernetes基础设施。我们的警报系统(普罗米修斯,Alertmanager)监控我们的生产基础设施,并根据定义的表达式发出警报。Healer作为后端服务运行,侦听来自Alertmanager的带有警报有效负载的HTTP请求。
Healer使用警报元数据,根据警报类型和警报标签构造适当的补救措施。补救规定了补救行动以及所需的任何参数。
每个补救都被调度到一个工作执行线程池。工作线程将通过调用适当的服务来运行相应的修复,然后监视修复的完成情况。在实践中,这可能是启动Jenkins、Kubernetes或Spinnaker作业来自动化手动脚本工作流。我们选择支持这些框架,因为它们为Databricks工程师提供了广泛的能力,可以自定义响应警报的操作。
一旦修复完成,JIRA和Slack通知将被发送到相应的团队,确认修复任务完成。
治疗可以很容易地扩展与新的补救类型。Cloud Infra以外的工程团队可以安装与服务警报集成的补救作业,采取必要的行动从事件中恢复,减少整个工程的随叫随到负载。
用例
Healer的一个用例是修复Kubernetes节点上的低磁盘空间。一个名为“NodeDiskPressure”的警报将此问题通知随叫随到的工程师。为了补救NodeDiskPressure,一个随叫随到的工程师将连接到适当的节点并执行Docker映像修剪命令。
为了实现自动化,我们首先开发一个由Healer触发的动作;我们定义了一个名为DockerPruneNode的Jenkins作业,它自动化了相当于连接到节点并执行的手动步骤Docker映像修剪.然后,我们配置一个Healer补救,通过定义一个Healer规则来自动解决NodeDiskPressure警报,该规则绑定一个给定警报及其参数的确切补救(DockerPruneNode)。
下面是一个示例,说明如何将NodeDiskPressure警报转换为特定的补救措施,包括要运行的作业和所有所需的参数。最后的补救对象有三个“已翻译”的来自警报的参数,以及一个“静态”硬编码的参数。
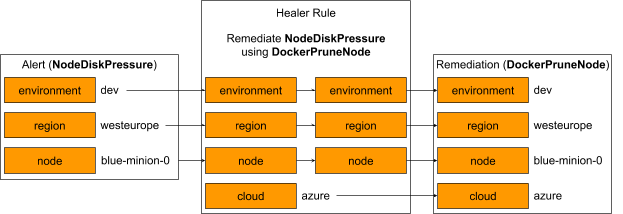
该配置还有一些其他参数,工程师可以配置这些参数来优化修复的确切行为。为简洁起见,这里省略了它们。
在定义了这条规则之后,潜在的问题就完全自动化了,允许随叫随到的工程师专注于其他更重要的事情!
未来的步骤
目前,Healer已经启动、运行,并正在提高我们开发基础设施的可用性。该服务的下一步是什么?
最初,我们计划加入更多云基础设施团队的用例。具体来说,我们正在研究以下用例:
- 通过利用现有的系统使用警报(CPU、内存)来触发将增加集群容量的补救措施,支持细粒度自动伸缩到我们的集群。
- 终止并重新配置标识为不健康的Kubernetes节点。
- 当服务TLS认证快要过期时,请轮换TLS认证。
此外,我们希望在工程组织中继续推动该工具的采用,并帮助其他团队加入他们的用例。这个通用框架可以扩展到其他团队,以减少他们随叫随到的负载。
我期待着看到什么其他事件治疗可以帮助补救Databricks在未来!
特别感谢我的导师廖子恒、康南溪和Eric Wang经理,以及Databricks云计算团队的其他成员!
我真的很享受在Databricks度过的这个夏天,并鼓励任何希望在平台工程领域找到有挑战性和有回报的职业的人加入我们的团队。bob体育客户端下载如果您有兴趣为我们的自愈架构做出贡献,请查看我们的开放的工作机会!