





监控你的砖工作区与审计日志
云计算已经从根本上改变了企业经营——用户不再受限制等本地硬件部署资源和繁重的环境升级过程的物理限制。云服务的便利性和灵活性来挑战如何正确监控用户使用这些方便的可用资源。未能这样做可能导致问题和昂贵的反模式(与云提供商的核心资源和一个PaaS像砖)。砖进行了设计,从而与公共云提供商紧密耦合,如微软和亚马逊网络服务,充分利用这个新范式,审计日志功能提供了管理员一个集中的方法来理解和管理活动发生在平台。bob体育客户端下载管理员可以使用砖审计日志监控模式集群的数量或工作在某一天,执行这些操作的用户,任何用户被拒绝授权到工作区中。
在本系列的第一篇博文中,信任,但要核查砖,我们覆盖砖管理员可以使用砖和其他云提供商日志审计日志的补充他们的云监控场景的解决方案。砖审计日志的主要目的是让企业安全团队和平台管理员跟踪数据访问和使用中可用的各种接口数据砖工作区资源平台。bob体育客户端下载在这篇文章中,我们将介绍,在细节,这些角色可以如何处理和分析审计日志跟踪资源使用和识别潜在的昂贵的反模式。
审计日志ETL设计
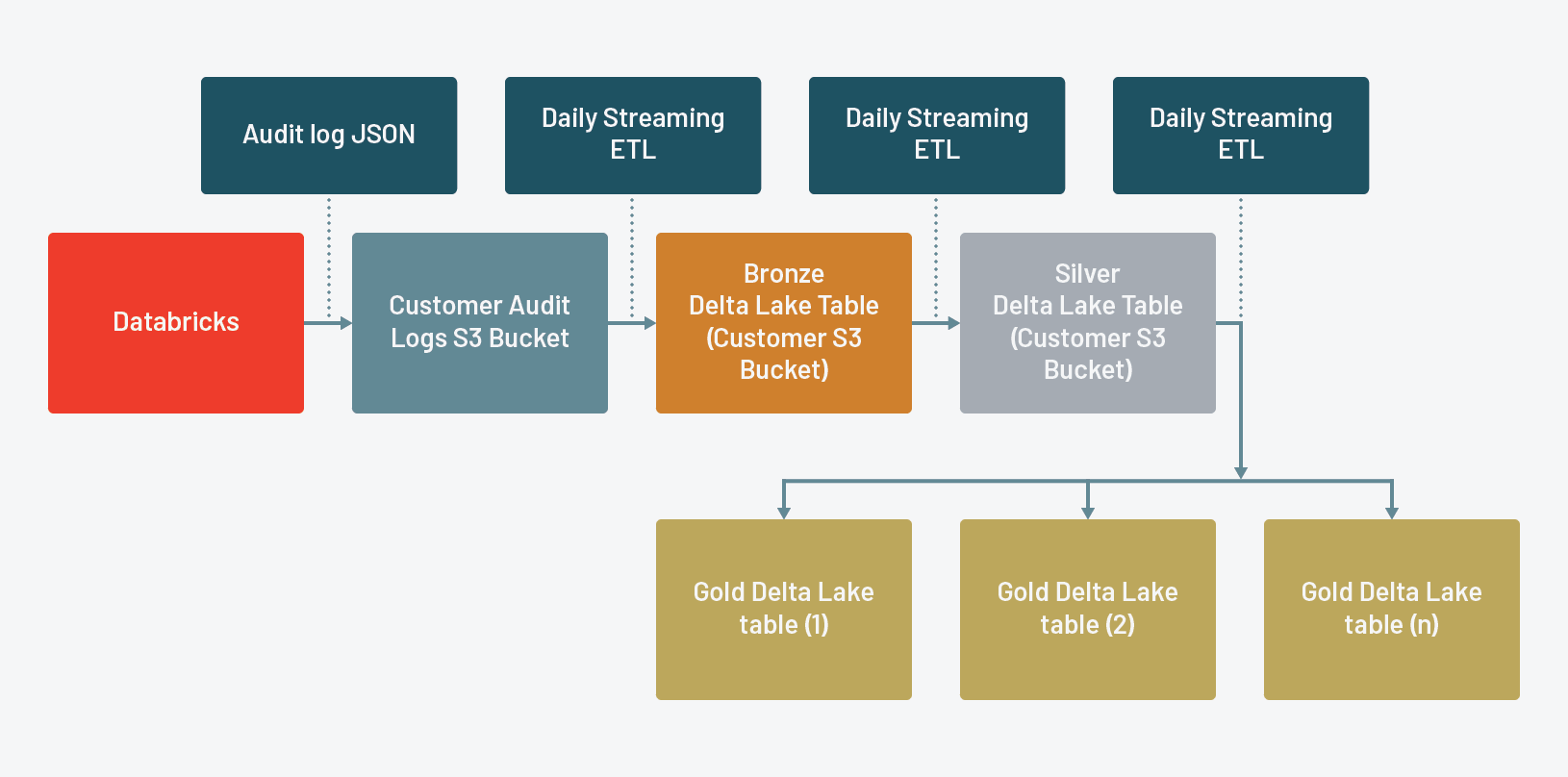
砖为所有人带来审计日志启用工作区根据SLA以JSON格式交付客户拥有的AWS S3 bucket。这些审计日志包含为特定的行为事件相关的主要资源集群等工作,工作空间。简化客户交付和进一步分析,砖记录每个事件的每一个行动都作为一个单独的记录并存储所有相关参数为稀疏StructType称为requestParams。
为了使这些信息更容易获得,我们建议一个ETL过程基于结构化流和三角洲湖。
- 利用结构化流允许我们:
- 离开状态管理的构建目的构建状态管理。而不必思考多长时间以来运行之前运行以确保我们只添加适当的记录,我们可以利用结构化流的检查站和写前日志,确保我们只处理新添加的审计日志文件。我们可以设计流的查询triggerOnce日常工作,就像pseudo-batch工作
- 利用三角洲湖允许我们做以下:
作为参考,这是砖的图案参考架构建议:
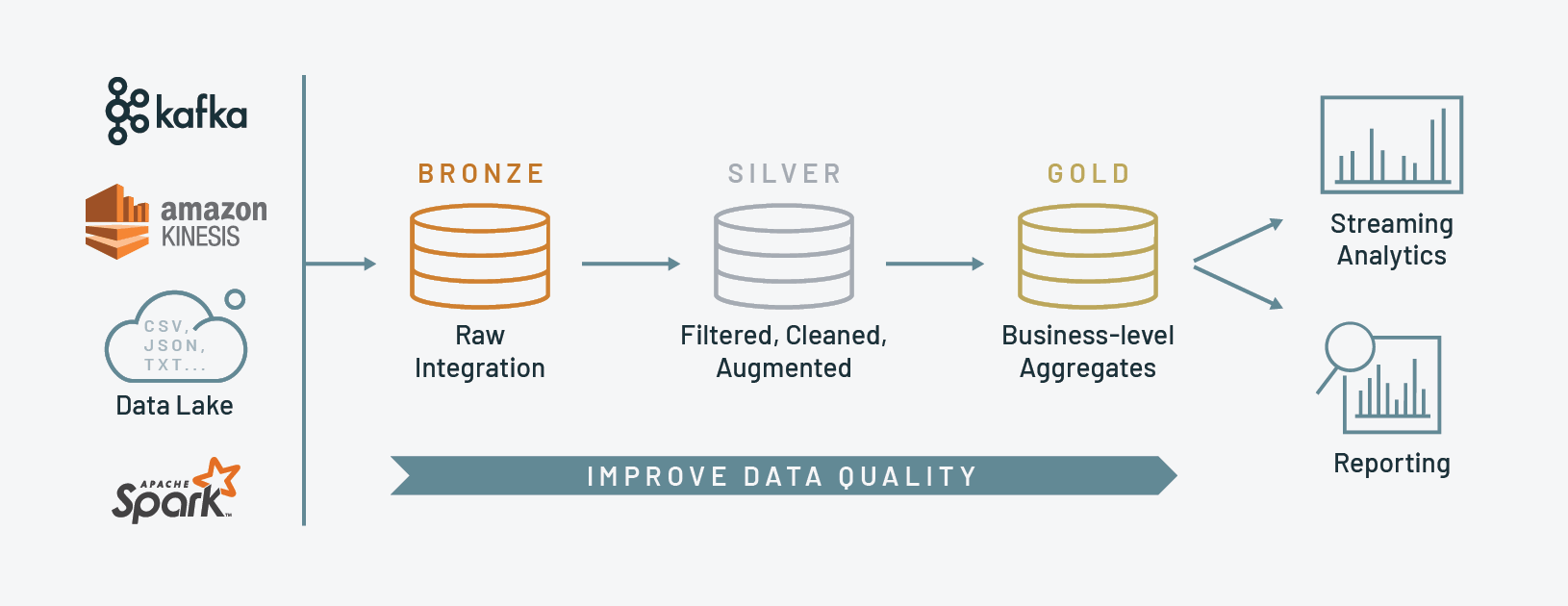
铜:最初的着陆区管道。我们建议复制的数据尽可能接近其原始形式轻松回放整个管道从一开始,如果需要的话
银:原始数据得到洁净(认为数据质量检查),转换和潜在的丰富与外部数据集
黄金:工业生产数据,整个公司可以依靠商业智能,描述性统计和数据科学/机器学习
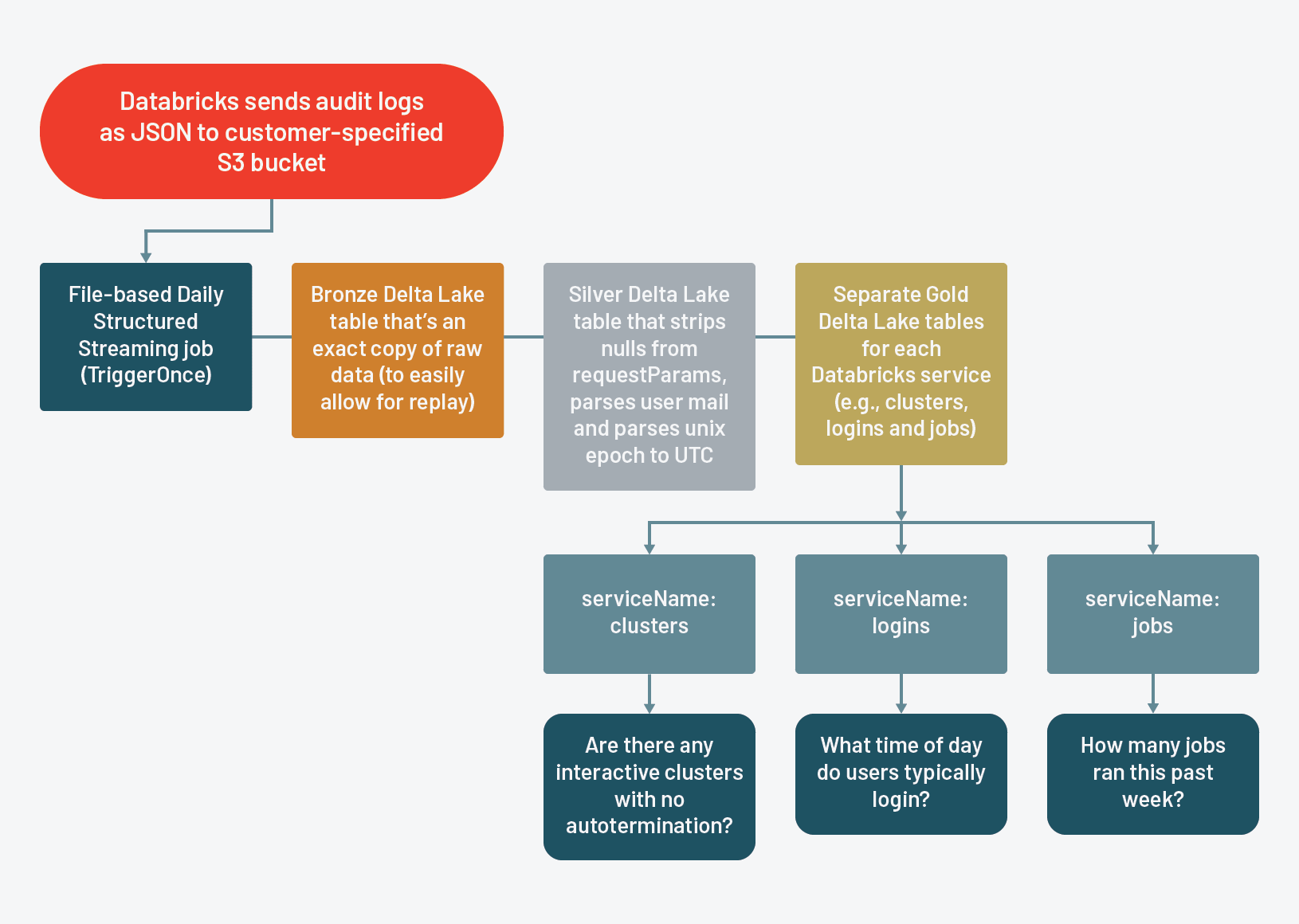
我们自己的图案架构后,我们把它我们的审计日志ETL设计如下:
原始数据铜表
流从砖的原始JSON文件交付使用一个基于文件的结构化流到青铜三角洲湖表。这将创建一个持久的原始数据的副本,让我们重放ETL、我们应该在下游找到任何问题表。
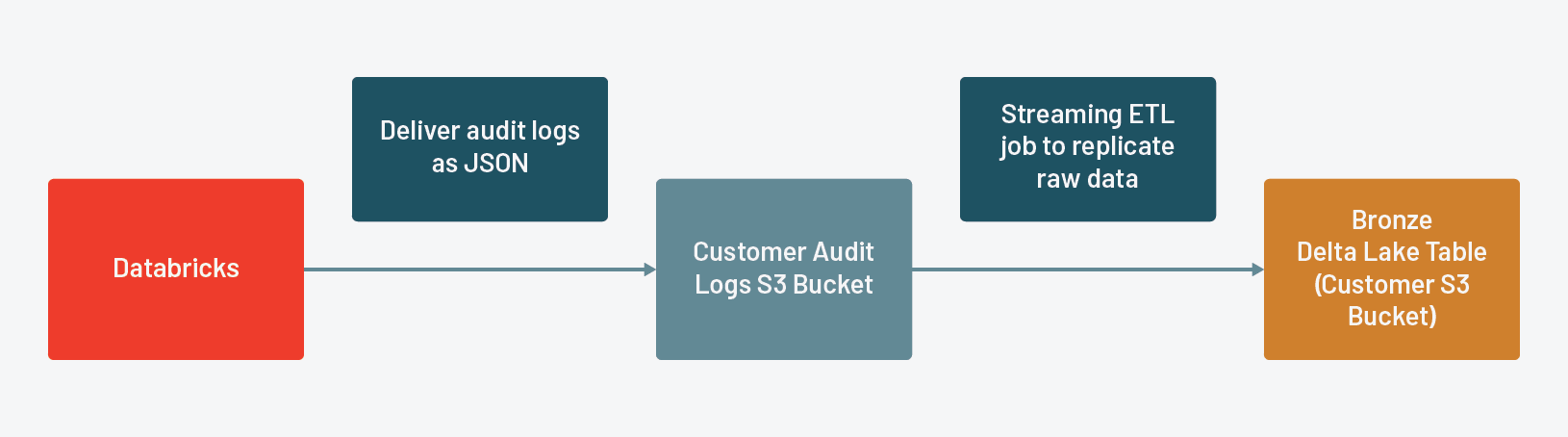
砖提供审计日志的形式向客户指定的AWS S3 bucket JSON。,而不是写作的逻辑来确定我们的状态三角洲湖表,我们要利用结构化流写前的日志和检查点来保持我们的状态表。在这种情况下,我们设计我们的ETL每天运行一次,所以我们使用源文件与triggerOnce用流媒体框架来模拟一个批处理工作负载。由于结构化流需要我们明确定义的模式,我们将读取原始JSON文件一旦建立它。
streamSchema = spark.read.json (sourceBucket) . schema我们然后实例化StreamReader使用模式我们推断和原始审计日志的路径。
streamDF = (火花.readStream。格式(“json”). schema (streamSchema).load (sourceBucket))然后实例化我们的StreamWriter并写出原始审计日志到青铜三角洲湖表分区的日期。
(streamDF.writeStream。格式(“δ”).partitionBy (“日期”).outputMode (“添加”).option (“checkpointLocation”,“{}/检查点/铜”。格式(sinkBucket)).option (“路径”,“{}/流/铜”。格式(sinkBucket)).option (“mergeSchema”,真正的).trigger(一旦=真正的).start ())现在我们已经创建了表在一个AWS S3 bucket,我们需要注册表数据砖蜂巢metastore让最终用户对数据的访问更容易。我们将创建逻辑数据库audit_logs之前,创建一个青铜表。
如果不存在audit_logs创建数据库spark.sql (”“”如果不存在audit_logs.bronze创建表使用δ位置“{}/流/铜””“”。格式(sinkBucket))如果你在批处理或更新你的三角洲湖表pseudo-batch时尚,这是最佳实践优化后立即更新。
优化audit_logs.bronze铜银表
从青铜三角洲湖表流银三角洲湖表,这样它将稀疏requestParams StructType每个记录的删除空的键,以及执行等其他基本转换解析电子邮件地址从一个嵌套的字段和解析UNIX新纪元UTC时间戳。
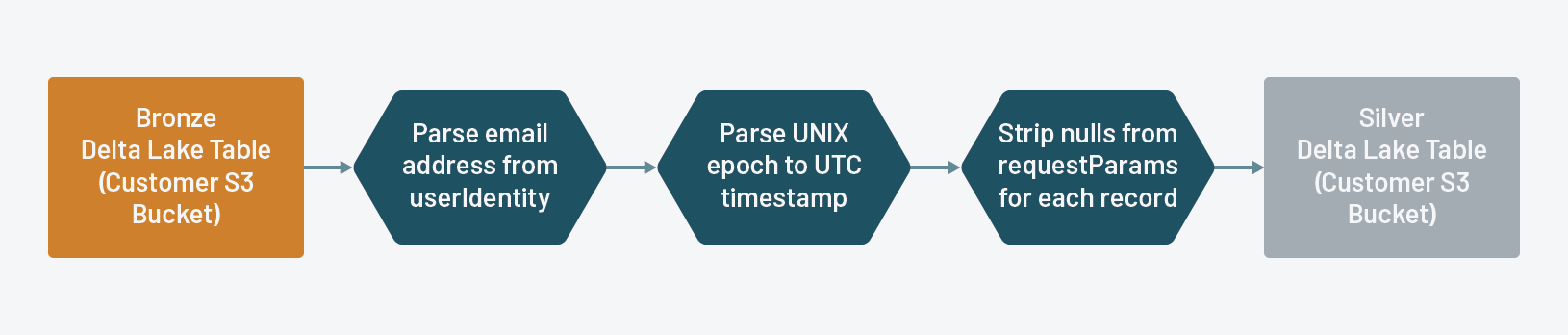
因为我们船审计日志中所有砖资源类型的一个共同的JSON格式,我们定义了一个规范的结构requestParams它包含一个联盟的关键资源类型。最后,我们要创建单独的数据表为每个服务,所以我们要拆开requestParams为每个表字段,使它只包含相关的资源类型的钥匙。为此,我们定义了一个用户定义的函数(UDF)除去所有这些键requestParams有零值。
defstripNulls(生):返回json。转储({我:raw.asDict()[我]为我在raw.asDict ()如果raw.asDict()[我]! =没有一个})
strip_udf = udf (stripNulls StringType ())我们实例化一个StreamReader从我们的青铜三角洲湖表:
bronzeDF = (火花.readStream.load (“{}/流/铜”。格式(sinkBucket)))然后下面的转换应用于流媒体数据从青铜三角洲湖表:
- 去掉
零键requestParams和存储为字符串的输出 - 解析
电子邮件从userIdentity - 解析的实际时间戳/时间戳数据类型
时间戳场和存储date_time - 把生
requestParams和userIdentity
查询=(bronzeDF.withColumn(“扁平化”,strip_udf (“requestParams”)).withColumn(“电子邮件”,上校(“userIdentity.email”)).withColumn (“date_time”, from_utc_timestamp (from_unixtime(坳(“时间戳”)/1000年)、UTC))。下降(“requestParams”)。下降(“userIdentity”))然后我们流的记录变成银三角洲湖表:
(查询.writeStream。格式(“δ”).partitionBy (“日期”).outputMode (“添加”).option (“checkpointLocation”,“{}/检查点/银”。格式(sinkBucket)).option (“路径”,“{}/流/银”。格式(sinkBucket)).option (“mergeSchema”,真正的).trigger(一旦=真正的).start ())再次,因为我们已经创建了一个表基于AWS S3 bucket,我们需要注册到万岁Metastore更容易访问。
spark.sql (”“”如果不存在audit_logs.silver创建表使用δ位置的{}/流/银”“”。格式(sinkBucket))虽然结构化流担保完全处理后,我们仍然可以添加一个断言检查项铜牌三角洲湖表到银三角洲湖表。
断言(spark.table (“audit_logs.bronze”)。数()==spark.table (“audit_logs.silver”)。数())至于铜表之前,我们将运行优化在更新后的银表。
优化audit_logs.silver白银和黄金表
个人黄金三角洲湖流表为每个砖服务跟踪审计日志
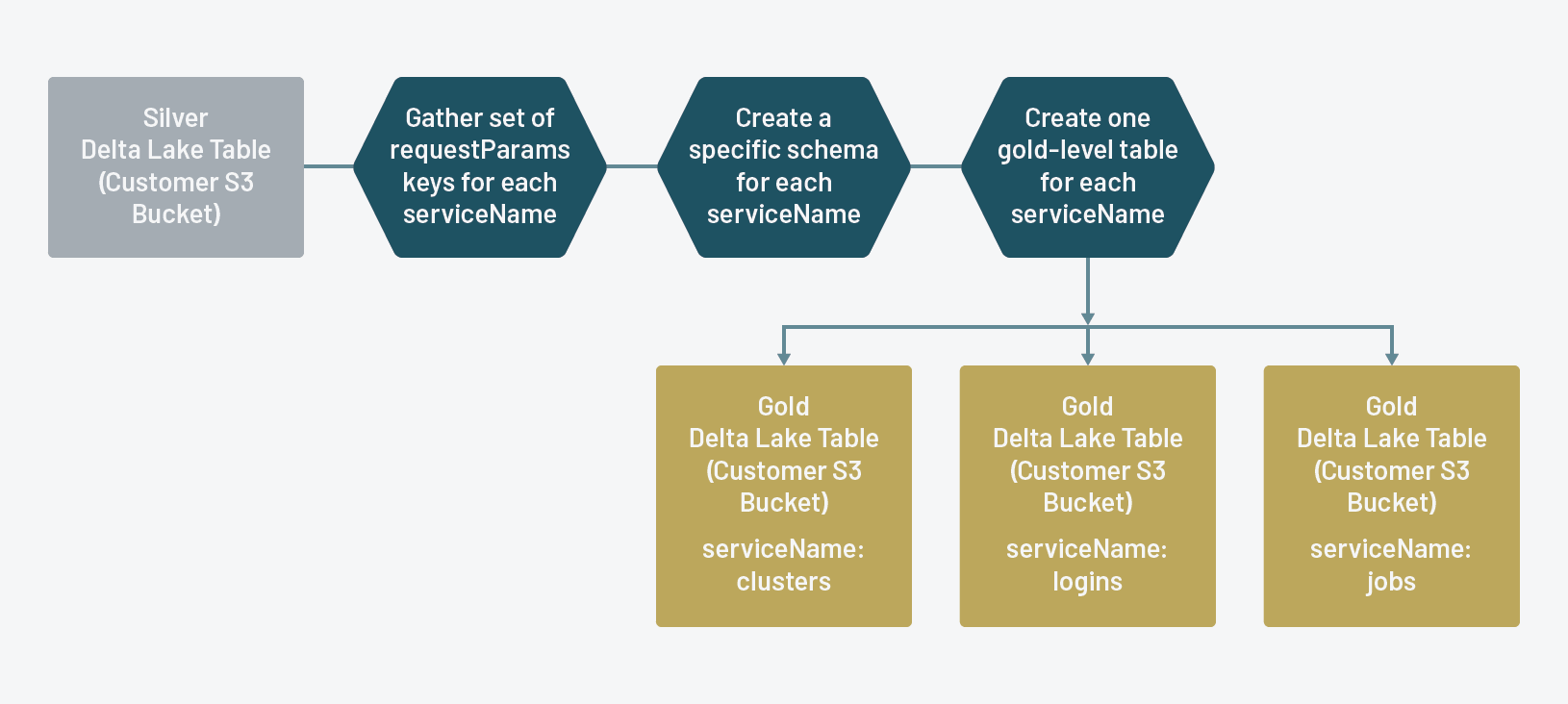
黄金审核日志表是什么砖管理员将利用他们的分析。通过requestParams字段精简的服务水平,现在更容易掌握分析和相关的事情。与三角洲湖优雅地处理模式演化的能力,如砖跟踪额外的行动为每个资源类型,黄金表将无缝地改变,消除错误的需要硬编码模式或照顾。
在ETL过程的最后一步,我们首先定义一个UDF来解析从原文的精简版本的钥匙requestParams字段。
def justKeys (字符串):返回(我为我在json.loads (字符串). keys ())
just_keys_udf = udf (justKeys StringType ())ETL的下一大块,我们将定义一个函数实现如下:
- 收集每个记录对于一个给定的密钥
名(资源类型) - 创建一组密钥(去除重复)
- 创建一个模式适用于一个给定的关键
名(如果名没有任何键requestParams,我们给它一个关键的模式占位符) - 写出个人黄金三角洲湖表
名在银三角洲湖表中
defflattenTable(这是bucketName):flattenedStream = spark.readStream.load (“{}/流/银”。格式(bucketName))= spark.table(夷为平地“audit_logs.silver”)…我们提取所有惟一的值的列表名用于迭代和运行上面的每个值函数名:
serviceNameList=(我(“名”]为我在spark.table (“audit_logs.silver”)。选择(“名”)。截然不同的()。收集())为名在serviceNameList:flattenTable(这是sinkBucket)和之前一样,注册蜂巢Metastore每个黄金三角洲湖表:
为名在serviceNameList:spark.sql (”“”如果不存在audit_logs创建表。{0}使用δ位置的{1}/流/金/ {2}””“”。格式(我)这是sinkBucket)然后运行优化每个表:
为名在serviceNameList:spark.sql (“优化audit_logs {}”。。格式(名))再次,声称没有必要数量是相等的,但我们仍然做:
flattened_count=spark.table (“audit_logs.silver”)。数()total_count=0为名在serviceNameList:total_count+=(spark.table (“audit_logs。{}“.format(名))。数())断言(flattened_count==total_count)我们现在有一个表为每个黄金三角洲湖名(资源类型)砖跟踪审计日志,我们现在可以使用进行监控和分析。
审计日志分析
在上面的部分中,我们使用ETL过程原始审计日志,包括一些建议关于如何简化数据访问您的最终用户和更好的性能。第一个笔记本包含在本文属于ETL过程。
第二个笔记本我们已经包括进入更详细的分析审计日志事件本身。对于这篇文章的目的,我们将专注于资源类型之一集群,但我们已经包括了分析登录作为另一个例子,管理员可以做的信息存储在审计日志。
可能是明显的有些为什么砖管理员可能希望监视集群,但它强调一遍:集群的正常运行时间是最大的动力成本,我们希望确保我们的客户获得最大价值当他们利用砖集群。
集群的一个主要部分正常运行时间方程是创建的集群的数量在这个平台上,我们可以使用审计日志确定创建的砖集群的数量在给定的一天。bob体育客户端下载
通过查询集群的黄金三角洲湖表,我们可以过滤actionName在哪里创建按日期和执行一个计数。
选择日期,数(*)作为num_clusters从集群在哪里actionName=“创建”集团通过1订单通过1ASC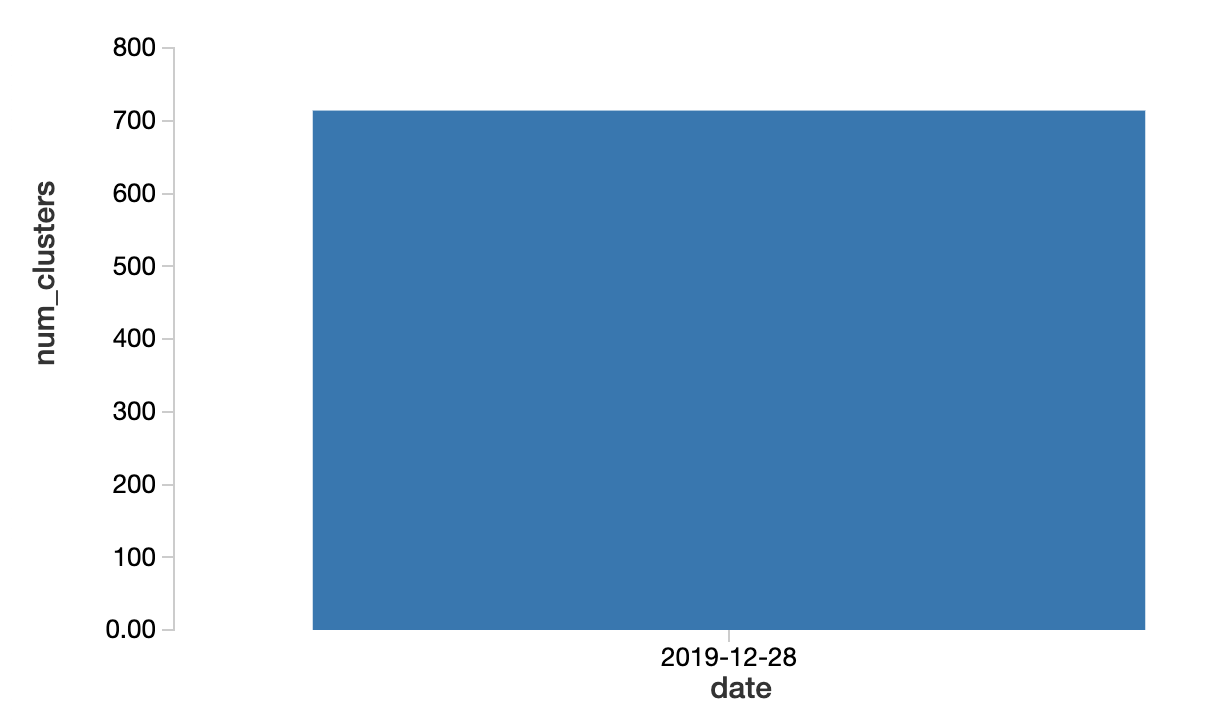
没什么背景在上面的图表,因为我们没有其他天的数据。但是为了简单起见,我们假设集群的数量增加了两倍多比正常使用模式和用户的数量并没有改变有意义的那段时期。如果真的是这样的话,那么一个合理的解释是,创建集群以编程方式使用工作。此外,12/28/19是周六,所以我们不要期望有许多互动集群创建。
检查cluster_creator字段,它应该告诉我们谁创造了它。
选择requestParams.cluster_creator,actionName,数(*)从集群在哪里日期=“2019-12-28”集团通过1,2订单通过3DESC
基于上述结果,我们注意到JOB_LAUNCHER714年创造了709个集群,集群12/28/19上创建,这证实了我们的直觉。
我们的下一步是找出哪些特定的工作创造了这些集群,我们可以提取从集群名称。砖工作的集群按照此命名约定工作,,所以我们可以解析jobId从集群名称。
选择(requestParams分裂。cluster_name,“-”)1]作为jobId,数(*)从集群在哪里actionName=“创建”和日期=“2019-12-28”集团通过1订单通过2DESC
这里我们看到jobId“31303”的罪魁祸首是绝大多数集群12/28/19上创建。另一个信息,存储在审计日志requestParams是user_id用户创建的工作。由于工作的创造者是不可变的,我们可以把第一条记录。
选择requestParams.user_id从集群在哪里actionName=“创建”和日期=“2019-12-28”和(requestParams分裂。cluster_name,“-”)1]=“31303”限制1
现在,我们有user_id用户创建的工作,我们可以利用SCIM API直接获取用户的身份和问他们什么可能发生在这里。
除了监控集群整体的总数,我们鼓励砖管理员特别注意所有没有目的计算集群autotermination启用。原因是这样的集群将继续运行,直到手动终止,无论他们空闲与否。您可以识别这些集群使用以下查询:
选择日期,数(*)作为num_clusters从集群在哪里actionName=“创建”和requestParams.autotermination_minutes=0和requestParams.cluster_creator是零集团通过1订单通过1ASC如果你使用我们的示例数据,你会发现有5个集群的cluster_creator是零这意味着他们是由用户而不是工作。

通过选择创建者的电子邮件地址和集群的名字,我们可以确定哪些集群需要终止哪些用户,我们需要讨论砖资源管理的最佳实践。
如何开始处理数据砖审计日志吗
灵活的ETL过程,遵循最佳实践的大奖章架构与结构化流和三角洲湖,我们简化砖审计日志的分析通过创建单独的数据表为每个数据砖资源类型。聚类分析的例子只是其中之一的许多方面分析审计日志有助于识别有问题的反模式可能导致不必要的成本。请使用以下笔记本具体步骤我们包含在这篇文章试试在你结束:
更多的信息,你也可以看最近的技术讨论:最佳实践对如何处理和分析审计日志与三角洲湖和结构化流。

稍微不同的架构,流程的审计日志,只要他们可用,考虑评估新自动加载程序能力,我们详细讨论博客。
我们希望我们的客户价值最大化他们从我们的平台,所以请联系你的砖账户团队如果你有任何问题。bob体育客户端下载
免费试着砖
相关的帖子