





客户生命周期价值第1部分:评估客户生命周期
下载客户生命周期第1部分笔记本演示下面介绍的解决方案,并观看按需虚拟研讨会以了解更多信息。BOB低频彩你……
2020年6月3日 在工程的博客
每个营销人员面临的最大挑战是如何最好地花钱来发展他们的品牌。我们希望把营销资金花在吸引最佳客户的活动上,同时避免把钱花在无利可图的客户或侵蚀品牌资产的活动上。
营销人员往往只关注支出效率。为了产生收益,我在广告和促销上至少可以花多少钱?只关注ROI指标会削弱你的品牌价值,使你更加依赖价格促销来产生销售。
在你现有的客户群体中,既有品牌忠实者,也有品牌瞬变者。品牌忠诚者对你的品牌高度投入,愿意与他人分享他们的经验,并且最有可能再次购买。品牌瞬变者对你的品牌没有忠诚度,只会根据价格来购物。理想情况下,你的营销支出应该集中在培养品牌忠实者群体上,同时尽量减少对品牌瞬变的曝光。
那么,你如何识别这些品牌忠实者,并最好地利用你的营销资金来延长他们与你的关系呢?
今天的客户不缺乏选择。为了脱颖而出,企业需要直接与显示器、电话或车站另一边的个人的需求和愿望对话,通常以一种不仅认识到个人客户,而且认识到将他们带到交换的环境的方式。如果处理得当,个性化的接触可以带来更高的收入、营销效率和客户保留率,随着功能的成熟和客户期望的提高,正确的个性化将变得越来越重要。作为麦肯锡公司他认为,个性化将成为“未来五年内营销成功的主要驱动力”。
但个性化的一个关键方面是要理解不是每个客户都有相同的盈利潜力。不同的客户不仅从我们的产品和服务中获得不同的价值,而且这直接转化为我们可能期望回报的整体价值的差异。如果我们和客户之间的关系是互惠互利的,我们必须仔细地将客户获取成本(CAC)和保留率与总收入或利润保持一致客户终身价值(CLV)我们在这段关系中所能接受到的。
这是客户生命周期价值计算背后的核心动机。通过计算我们在与客户的关系中可能从他们那里获得的收益,我们可能会更好地调整我们的投资,使我们的关系对双方的价值最大化。我们可能会进一步了解为什么一些客户比其他客户更重视我们的产品和服务,并调整我们的信息,以吸引更多更高潜力的个人。我们也可以综合使用CLV来评估我们在建立公平和监控方面的营销实践的整体有效性随着时间的推移,市场的创新和变化如何影响它.
但是尽管CLV很强大,重要的是我们欣赏它由两个独立的估计得出.第一个是我们期望从给定客户那里看到的每笔交易花费(或平均订单价值)。第二个是在给定的时间范围内,我们可能期望从该客户那里获得的估计交易数量。第二种估计通常被视为达到目的的手段,但作为组织改变营销支出从获取新客户到留存用户,它本身就变得非常有价值。
在大多数零售商参与的非合同场景中,顾客可以随心所欲地来去。试图评估客户关系剩余寿命的零售商必须仔细检查客户先前产生的交易信号,包括他们参与的频率和最近。例如,一个频繁的购买者放慢了他们的购买模式,或者只是在很长一段时间内没有重新出现,这可能表明他们正在接近他们的关系生命周期的终点。另一个不经常参与的买家,即使在缺席类似的时间,也可能继续保持可行的关系。
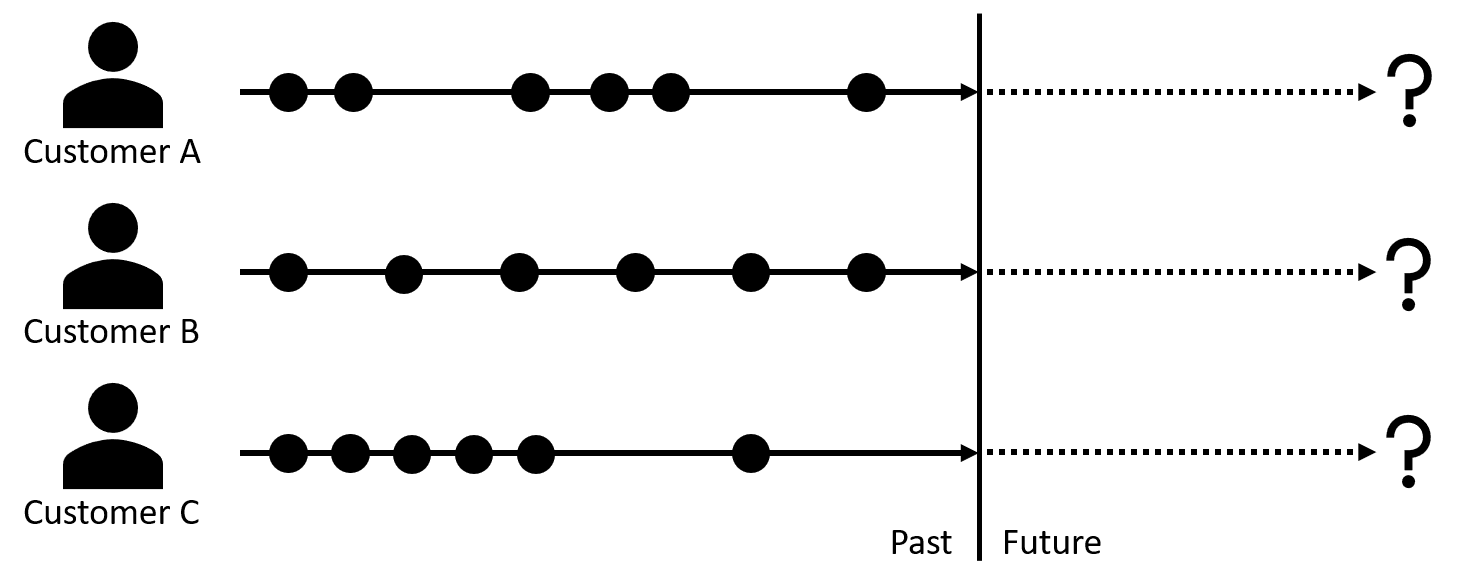
了解客户在他们与我们的关系生命周期中的位置,对于在正确的时间传递正确的消息至关重要。表示有意与我们品牌建立长期关系的客户,可能会积极响应更高的投资报价,这将加深和加强他们与我们的关系,并在牺牲短期收入的情况下将关系的长期潜力最大化。客户表示他们的意图是短期关系可能会被类似的报价推开,或者更糟的是,可能会接受这些报价,而我们没有希望收回投资。
利用mlflow,一个机器学习模型管理和部署平台,我们可以轻松地将我们的模型映射到标准化的应用程序接口。bob体育客户端下载虽然mlflow本身不支持生命周期生成的模型,但很容易为此目的进行扩展。这样做的最终结果是,我们可以快速地将经过训练的模型转换为功能和应用程序,从而实现定期、实时和交互式的客户预期寿命指标评分。
同样,我们可能会发现关系信号的变化,比如当长寿的客户接近他们关系生命周期的终点时,我们会推广替代产品和服务,从而将他们转变为与我们或合作伙伴之间的新的、潜在有利可图的关系。即使是短期客户,我们也会考虑如何最好地提供产品和服务,在他们有限的时间内实现收入最大化,并允许他们将我们推荐给其他寻求类似产品的客户。
正如Peter Fader和Sarah Toms在《以客户为中心的策略》中所写的那样,在一个有效的以客户为中心的战略中,“获得最大经济收益的机会被发现并充分利用,但这些高风险的赌注必须权衡,并分布在风险较低的资产类别中。”要找到正确的平衡并调整我们的互动,首先要仔细估计客户在他们一生中与我们在一起的过程中所处的位置。
如前所述,在非订阅模型中,我们无法知道客户的确切生命周期或他/她在生命周期中的位置,但我们可以利用它们生成的事务信号来估计客户活跃和未来可能返回的概率。以“买到死”(BTYD)模型著称的是,顾客的参与频率和最近度相对于零售商顾客群体的相同模式,可以用来推导生存曲线,为我们提供这些值。
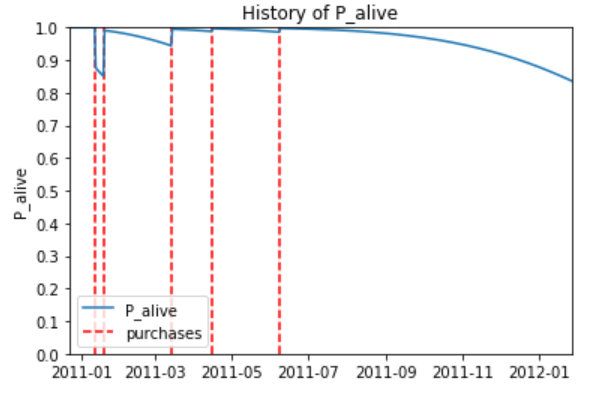
这些预测CLV模型背后的数学是相当复杂的。提出的原始BTYD模型Schmittlein等人.直到20世纪80年代末(今天被称为帕累托/负二项分布或帕累托/NBD模型)才开始被采用Fader等.在2000年代中期简化了计算逻辑(产生了beta几何/负二项分布或BG/NBD模型)。即便如此,简化模型的数学运算很快就会变得非常复杂。值得庆幸的是,我们可以通过名为lifetimes的流行Python库访问这两个模型背后的逻辑,我们可以向该库提供简单的汇总度量,以便获得特定于客户的生命周期估计。
尽管具有高度的可访问性,但使用生命周期库以与大型企业的需求一致的方式计算特定于客户的概率可能具有挑战性。首先,必须处理大量的事务数据,以生成模型所需的每个客户指标。接下来,必须从这些数据中推导出曲线,使其符合预期的值分布模式,该过程由一个不能预先确定的参数调节,而是必须在很大的潜在值范围内迭代评估。最后,生命周期模型一旦拟合,必须整合到我们业务的营销和客户参与功能中,以便它产生的预测产生任何有意义的影响。这是我们在这个博客和相关笔记本的意图,以演示如何解决每一个挑战。
BTYD模型依赖于三个关键的每个客户指标:
这些指标本身非常简单。挑战在于从交易历史中为每个客户推导这些值,这些交易历史可能记录了多年期间发生的每笔交易的每一行项。通过利用数据处理平台,例如bob体育客户端下载Apache火花本机将此工作分布到多服务器环境的容量中,可以轻松解决此挑战,并及时计算指标。随着越来越多的事务数据到达,这些指标必须在不断增长的事务数据集上重新计算,Spark的弹性特性允许征调额外的资源,以将处理时间保持在业务定义的范围内。
计算每个客户的指标后,生命周期库可以用于训练多个BTYD模型中的一个,这些模型可能适用于给定的零售场景。(最广泛应用的两种是帕累托/NBD模型和BG/NBD模型,但还有其他模型。)虽然计算复杂,但每个模型都是通过一个简单的方法调用来训练的,这使得该过程具有高度的可访问性。
但在每个模型的训练过程中都采用了正则化参数,避免了对训练数据的过度拟合。在给定的训练练习中,该参数的最佳值很难事先知道,因此通常的做法是根据一系列潜在值训练和评估模型拟合,直到可以确定最优值。
这个过程通常包括数百甚至数千次的培训/评估。当一次执行一个时,确定最佳值的过程(通常在新的事务数据到达时重复)可能会非常耗时。
通过使用一个名为hyperopt,我们可以利用Apache Spark环境背后的基础设施,并以并行的方式分发模型训练/评估工作。这使得参数调优练习能够有效地执行,返回给我们最优的模型类型和正则化参数设置。
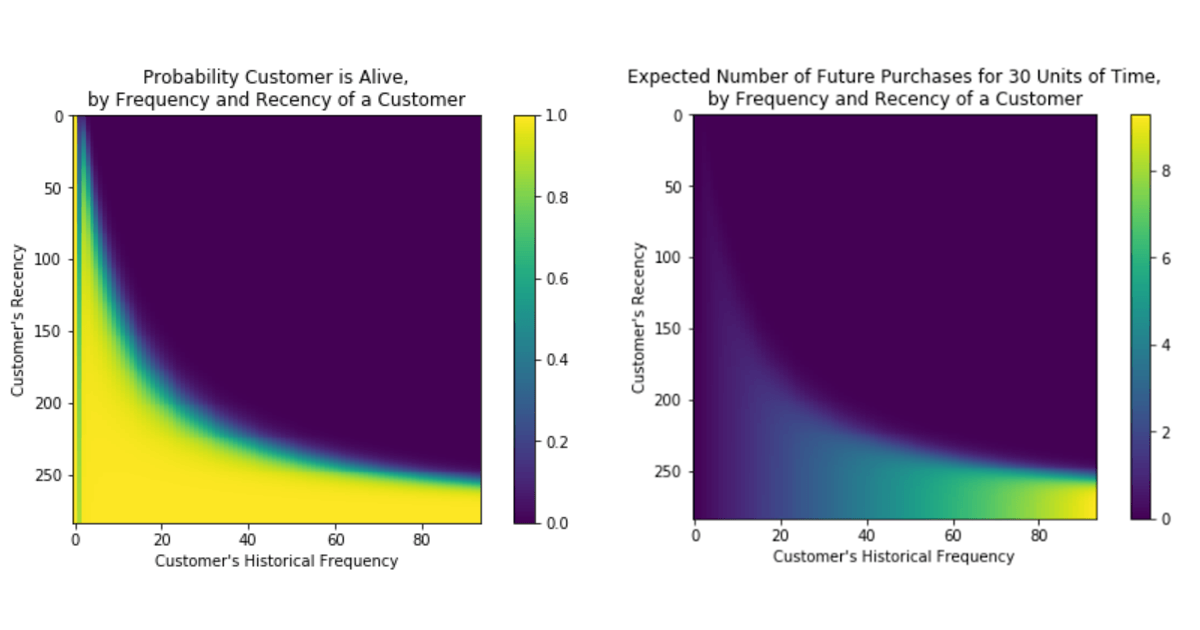
一旦经过适当的训练,我们的模型不仅能够确定客户再次参与的概率,而且能够确定未来期间预期的参与数量。说明近因和频率度量之间关系的矩阵和这些预测结果提供了封装在现在拟合模型中的知识的强大可视化表示。但真正的挑战是将这些预测能力交到那些决定客户参与度的人手中。
利用mlflow(机器学习模型管理和部署平台),我们可以轻松地将模型映射到标准化的应用程序接口。bob体育客户端下载虽然mlflow本身不支持生命周期生成的模型,但很容易为此目的进行扩展。这样做的最终结果是,我们可以快速地将经过训练的模型转换为功能和应用程序,从而实现定期、实时和交互式的客户预期寿命指标评分。
BYTD模型的预测能力与生命周期库提供的易于实现相结合,使得广泛采用客户生命周期预测成为可能。不过,在这样做的过程中还必须克服一些技术挑战。但是,无论是从大量交易历史中扩展客户指标的计算,在大型搜索空间中执行优化的超参数调优,还是部署最优模型作为支持客户评分的解决方案,克服这些挑战所需的能力都是可用的。不过,将这些功能集成到单个环境中可能是具有挑战性和耗时的。谢天谢地,Databricks已经为我们做了这项工作。通过将其作为云原生平台提供,需要访问这些平台的零售商和制造商可以在一个高度可扩展的环bob体育客户端下载境中开发和部署解决方案,且前期成本有限。
下载笔记本开始吧。