
现代化风险管理第2部分:聚合,大规模回溯测试和引入替代数据

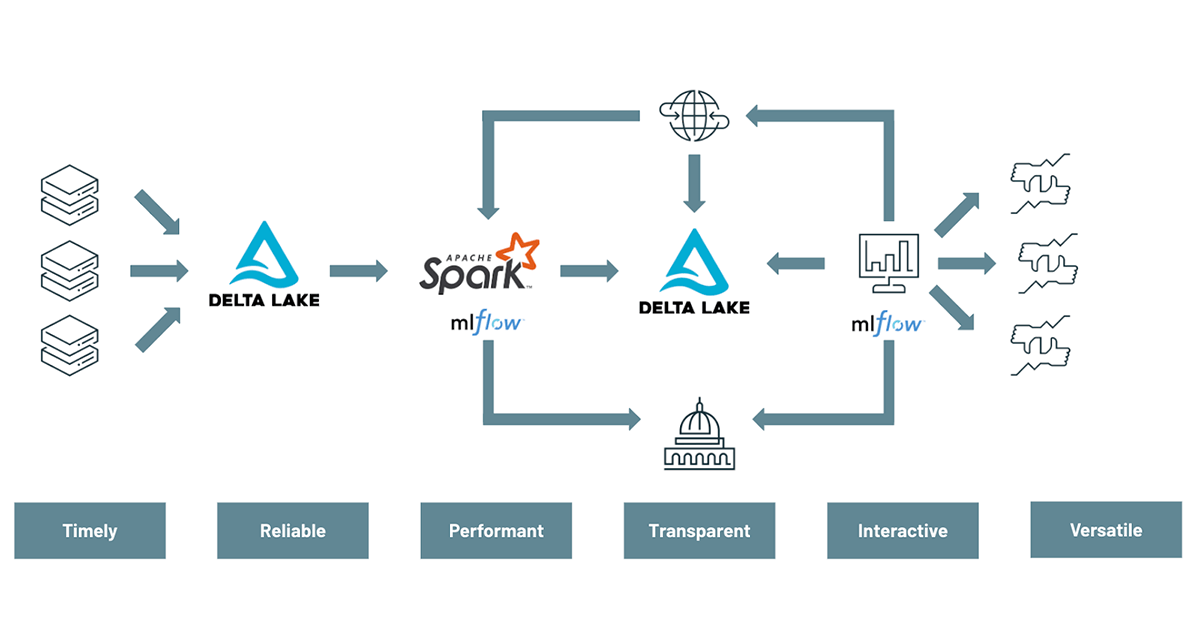
理解和降低风险是任何金融服务机构的首要任务。然而,正如这个由两部分组成的系列的第一篇博客中所讨论的那样,如今的银行仍在努力跟上其业务面临的新风险和威胁。受本地基础设施和遗留技术限制的困扰,银行直到最近才拥有有效构建现代风险管理实践的工具。幸运的是,基于云原生基础设施支持的开源技术,目前存在更好的替代方案。这现代风险管理框架支持日内视图,按需聚合和未来证明/规模风险管理的能力。在这个由两部分组成的系列博客中,我们将演示如何通过使用的方法使传统的风险价值计算现代化三角洲湖,Apache火花TM而且MLflow为了使一个更灵活和前瞻性的方法,风险管理。
第一个演示通过数据和高级分析解决了与风险管理实践现代化相关的技术挑战,涵盖了使用MLflow和Apache Spark进行风险建模和蒙特卡罗模拟的概念TM.本文主要关注风险分析师角色及其需求,以便在新威胁出现时实时更好地理解投资组合风险,从而有效地分割和细分风险模拟(按需)。我们将讨论以下主题:
- 使用Delta Lake和SQL按需聚合风险价值
- 使用Apache SparkTM和MLflow对模型进行回测,并向监管机构报告违规情况
- 探索使用替代数据来更好地评估您的风险暴露
三角洲湖的风险价值
在第一部分在这个由两部分组成的系列博客中,我们揭示了现代风险管理平台的样子,以及金融服务机构需要改变看待数据的视角:不再将数据视为成本,而是将其视为资产。bob体育客户端下载我们展示了数据的多用途性质,以及如何以最细粒度的形式存储蒙特卡罗数据,从而支持多个用例,同时为分析师提供运行特别分析的灵活性,有助于对银行面临的风险进行更健壮和敏捷的查看。

在这个博客和演示中,我们揭示了由多个行业的40种工具组成的拉丁美洲股票投资组合的各种投资风险。为此,我们利用了通过蒙特卡罗模拟(40个仪器x 50,000个模拟x 52周= 1亿条记录)生成的大量数据,按天划分,并通过我们的投资组合分类法进行丰富,如下所示。

风险价值
风险价值是模拟随机游走的过程,它涵盖了可能的结果和最坏的情况(n)。(t)天内95%的风险值是最糟糕的5%试验中的最佳情况。
由于我们的试验是按天划分的,分析师可以很容易地访问一天的模拟数据,并通过试验Id(即用于生成金融市场条件的种子)对个人回报进行分组,以访问我们投资回报的每日分布及其各自的风险价值。我们的第一种方法是使用Spark SQL来聚合给定一天(50,000条记录)的模拟回报,并使用内存中的python通过简单的numpy操作来计算5%的分位数。
返回=火花\.read \.表格(monte_carlo_table) \.过滤器(F.col (“run_date”)==“2020-01-01”) \.groupBy (“种子”) \.agg (F。总和(“审判”) .alias (“返回”)) \.选择(“返回”) \.toPandas () (“返回”]value_at_risk=np.quantile (返回,5/One hundred.)如果在我们所有的拉丁美洲股票工具上进行1万美元的初始投资,在特定的时间点上95%的风险价值将是3000美元。这是我们的业务在所有可能发生的事件中最糟糕的5%中(至少)准备损失的金额。

这种方法的缺点是,我们首先需要收集内存中的所有日常试验,以便计算5%的分位数。虽然在使用1天的数据时可以轻松地执行这个过程,但在较长时间内聚集风险价值时,它很快就会成为一个瓶颈。
一种实用的、可扩展的解决问题的方法
从大型数据集中提取百分位数对于任何分布式计算环境都是一个已知的挑战。一种常见的(尽管效率很低)做法是:1)对所有数据进行排序,2)使用takeOrdered选择特定的行,或者通过approxQuantile方法找到近似值。我们的挑战略有不同,因为我们的数据不构成一个单一的数据集,而是跨越多个天、多个行业和多个国家,其中每个桶可能太大,无法在内存中有效地收集和处理。
在实践中,我们利用风险价值的本质,只关注最坏的n个事件(n小)。给定每台仪器50,000次模拟和99%的VaR,我们只感兴趣在最差的500个实验中找到最好的。为此,我们创建了一个用户定义的聚合函数(UDAF),它只返回最差n个事件中的最佳事件。这种方法将大大减少计算大规模VaR聚合时可能出现的内存占用和网络约束。
类ValueAtRisk(n:Int)扩展UserDefinedAggregateFunction{//这些是聚合函数的输入字段。重写inputSchema: org.apache.spark.sql.types.StructType = {StructType (StructField (“价值”, DoubleType):: Nil)}//这些是你为计算聚合而保留的内部字段。重载bufferSchema: StructType = StructType数组(StructField (“坏的”ArrayType(倍增式)))//聚合函数的输出类型。重写dataType: dataType = DoubleType//我们处理数据帧的顺序不重要//最坏的永远是最坏的覆盖定义确定性:布尔=真正的//这是缓冲区模式的初始值。重写def初始化(缓冲区:MutableAggregationBuffer):单位= {缓冲(0) = Seq。空[双]}这是如何在给定输入的情况下更新你的缓冲区模式。重写def update(buffer: MutableAggregationBuffer, input: Row): Unit = {缓冲(0) = buffer.getAs[Seq[双]] (0):+ input.getAs[双) (0)}这是如何合并bufferSchema类型的两个对象。//我们只保留最差N个事件重写def merge(buffer: MutableAggregationBuffer, row: row): Unit = {缓冲(0) = (buffer.getAs [Seq [双]] (0getas [Seq[双]] (0)) .sorted.take (n)}//这是输出最终值的地方//我们的风险值是所有风险值中最好的override def evaluate(buffer: Row): Any = {返回buffer.getAs [Seq [双]] (0) .sorted.last}
}// 95%的风险值是最坏的N个事件中的最佳Val n = (One hundred.-95) * numSimulations /One hundred.//注册uadfspark.udf.register (“VALUE_AT_RISK”,新ValueAtRisk (n))通过spark.udf.register方法注册我们的UADF,我们将该功能暴露给所有用户,无需scala / python / spark高级知识的所有人都可以进行风险分析。人们只需按试验Id(即种子)进行分组,以便应用上述方法,并在所有数据中使用普通的旧SQL功能提取相关的风险值。
选择t.run_date作为一天,VALUE_AT_RISK (t.return)作为value_at_risk从(选择m.run_date,m.seed,总和(m.trial)作为返回从monte_carlo米集团通过m.run_date,m.seed) t集团通过t.run_date订单通过t.run_dateASC我们可以很容易地发现COVID-19对我们市场风险计算的影响。自2020年3月初以来,90天的经济波动期导致风险价值大幅降低,因此整体风险敞口大幅上升。

全面看待我们的风险暴露
在大多数情况下,仅仅了解总体的风险价值是不够的。分析师需要了解不同账簿、资产类别、不同行业或不同运营国家的风险敞口。除了前面讨论过的时间旅行和ACID事务等Delta Lake功能之外,Delta Lake和Apache SparkTM在Databricks运行时进行了高度优化,以提供读取时的快速聚合。通过使用我们的本地分区逻辑(按日期)以及适用于国家和行业的z顺序索引,可以实现高性能。在选择国家或行业级别的特定数据切片时,将充分利用这个额外的索引,从而大大减少在VaR聚合之前需要读取的数据量。
优化蒙特卡罗ZORDER BY(国家,行业)通过使用国家和行业作为VALUE_AT_RISK方法的分组参数,我们可以轻松地调整上面的SQL代码,以便对风险暴露有一个更细粒度和描述性的视图。由此产生的数据集可以使用Databricks笔记本进行可视化,并可以进一步细化,以了解这些国家对我们整体风险价值的确切贡献。

在这个例子中,秘鲁似乎对我们整体风险敞口的贡献最大。在秘鲁的行业级别上查看相同的SQL代码,我们可以调查跨行业风险的贡献。

2020年3月,秘鲁的主要风险敞口似乎与采矿业有关,这一比例接近60%。为应对新冠病毒而实施的越来越严格的封锁措施,影响了铜、黄金和白银生产中心秘鲁的采矿项目。源).
扩展本文的范围,我们可能想知道是否可以更早地使用替代数据,特别是使用事件、位置和基调的全球数据库(GDELT).我们在下面的图表中报告秘鲁采矿业的媒体报道,通过简单的移动平均线对积极和消极趋势进行颜色编码。

这清楚地显示了2月初的积极趋势,即在观察到的股票波动的15天之前,这可能是风险增加的早期迹象。这一分析强调了风险价值计算现代化的重要性,用来自替代数据的外部因素来补充历史数据。
模型,val
为了应对2008年金融危机,巴塞尔银行监管委员会又制定了一套措施。1天VaR 99结果将与每日损益进行比较。每季度使用最近250天的数据进行回测。根据在此期间所经历的超标次数,VaR测量被分为三个彩色区域之一。
| 水平 | 阈值 | 结果 |
|---|---|---|
| 绿色 | 最多超过4项 | 没有特别的担忧 |
| 黄色的 | 最多超过9项 | 监测要求 |
| 红色的 | 超过10项 | VaR措施有待改进 |
的风险价值
根据我们前面定义的聚合函数,我们可以在整个投资组合中提取每日的风险价值。由于我们的聚合风险价值数据集很小(包含2年的历史,即365 x 2个数据点),我们的策略是收集每日VaR并将其广播到更大的数据集,以避免不必要的混乱。关于AS-OF功能的更多细节可以在更早的文章中找到博客民主化金融时间序列分析.
情况下类VarHistory(time:长,valueAtRisk:字符串)瓦尔historicalVars=sql(年代”“”SELECT t.run_date, VALUE_AT_RISK(t.return) AS valueAtRisk从(SELECT m.run_date, m.seed, sum(m.trial)作为返回值来自蒙特卡洛mGROUP BY m.run_date, m.seed) t集团t.run_date”“”).withColumn(“时间”convertDate (坳(“run_date”))).orderBy(asc (“时间”)).选择(“时间”,“valueAtRisk”).作为[VarHistory].收集().sortBy(_.time).反向瓦尔historicalVarsB=火花.sparkContext.广播(historicalVars)我们通过一个简单的用户定义函数检索与实际收益最接近的风险价值,并执行250天的滑动窗口来提取连续的每日违规。
val asOfVar=udf ((s: java.sql.Date)=>{val historicalVars=historicalVarsB.value如果(s。取得时间s.getTime).headOption.map (_.valueAtRisk)}})val windowSpec=Window.orderBy(“时间”).rangeBetween (-3600年*24*250,0)val countBreaches=udf (asOfVar:双,返回: Seq [双])=>{的回报。数(_我们可以观察到一个连续的级数的17违反从二月以后就需要了来报告来法规依据来巴塞尔协议III框架。同样的情况也可以反映在图表上,在时间。