
Apache Spark™3.1针对结构化流的新特性



除了提供基于Spark Core和SQL API的流处理能力外,结构化流是Apache Spark™最重要的组件之一。在这篇博文中,我们总结了最新3.1版本中Spark Streaming的显著改进,包括一个新的流表API,支持流-流连接和多个UI增强。此外,模式验证和对Apache Kafka数据源的改进提供了更好的可用性。最后,对FileStream源/接收器进行了各种增强,以提高读/写性能。
新的流表API
在启动结构化流时,连续数据流被认为是无界表。因此,Table api提供了一种更自然、更方便的方式来处理流查询。在Spark 3.1中,我们增加了对DataStreamReader和DataStreamWriter的支持。最终用户现在可以直接使用API来读取和写入流数据帧作为表。请看下面的例子:
#创建流数据帧src=spark.readStream.format(“率”).option(“rowPerSecond”,10) .load ()#写入流数据帧来一个表格src.writeStream。选项(“checkpointLocation checkpointLoc1) .toTable(“myTable”)#检查的表格结果spark.read.table(“myTable”)。显示(截断=30.)+-----------------------+-----+|时间戳|价值|+-----------------------+-----+|2021-01年-19年07:45:23.122|42||2021-01年-19年07:45:23.222|43||2021-01年-19年07:45:23.322|44|...此外,使用这些新选项,用户可以转换源数据集并写入一个新表:
#写来一个新表格与转换spark.readStream.table(“myTable”)。选择(“价值”)\.writeStream。选项("checkpointLocation", checkpointLoc2) \.format(“铺”).toTable(“newTable”)#检查的表格结果spark.read.table(“newTable”)。显示()+-----+|价值|+-----+|1214||1215||1216|...Databricks建议使用三角洲湖格式与流表api,这允许您
- 紧凑的小文件产生的低延迟摄取并发。
- 使用多个流(或并发批处理作业)维护“恰好一次”的处理。
- 当使用文件作为流的源时,有效地发现哪些文件是新文件。
新支持流-流连接
在Spark 3.1之前,流-流连接只支持内连接、左外连接和右外连接。在最新的版本中,我们实现了完全的外部和左侧半流连接,使结构化流在更多的场景中有用。
Kafka数据源的改进
在Spark 3.1中,我们已经将Kafka依赖升级到2.6.0 (火星- 32568),允许用户迁移到新的Kafka偏移量检索API (adminclient . listoffset)。它解决了问题(火星- 28367)的Kafka连接器在使用旧版本时无限等待。
模式验证
模式是结构化流查询的基本信息。在Spark 3.1中,我们为用户输入模式和内部状态存储添加了模式验证逻辑:
在查询重启之间引入状态模式验证(火星- 27237)
通过此更新,键和值模式将存储在流开始时的模式文件中。然后,在重新启动查询时,将根据现有的键和值模式验证新的键和值模式的兼容性。当字段数量相同且每个字段的数据类型相同时,状态模式被认为是“兼容的”。注意,这里不检查字段名,因为Spark允许重命名。
这将防止运行具有不兼容状态模式的查询,从而减少不确定行为的机会,并提供更多信息的错误消息。
为流状态存储引入模式验证(火星- 31894)
以前,结构化流直接将检查点(用UnsafeRow表示)放入StateStore,而不需要任何模式验证。当升级到新的Spark版本时,检查点文件将被重用。如果没有模式验证,与聚合函数相关的任何更改或错误修复都可能导致随机异常,甚至是错误的答案(例如火星- 28067).现在Spark根据模式验证检查点,并在迁移期间重用检查点时抛出InvalidUnsafeRowException。值得一提的是,这项工作还帮助我们找到了阻断剂,火星- 31990: Spark 3.0.1版本中,流的状态存储兼容性被打破。
结构化流UI增强
我们介绍了新的结构化流UI火花3.0.在Spark 3.1中,我们添加了历史服务器对结构化流UI的支持(火星- 31953),以及有关流媒体运行时状态的更多信息:
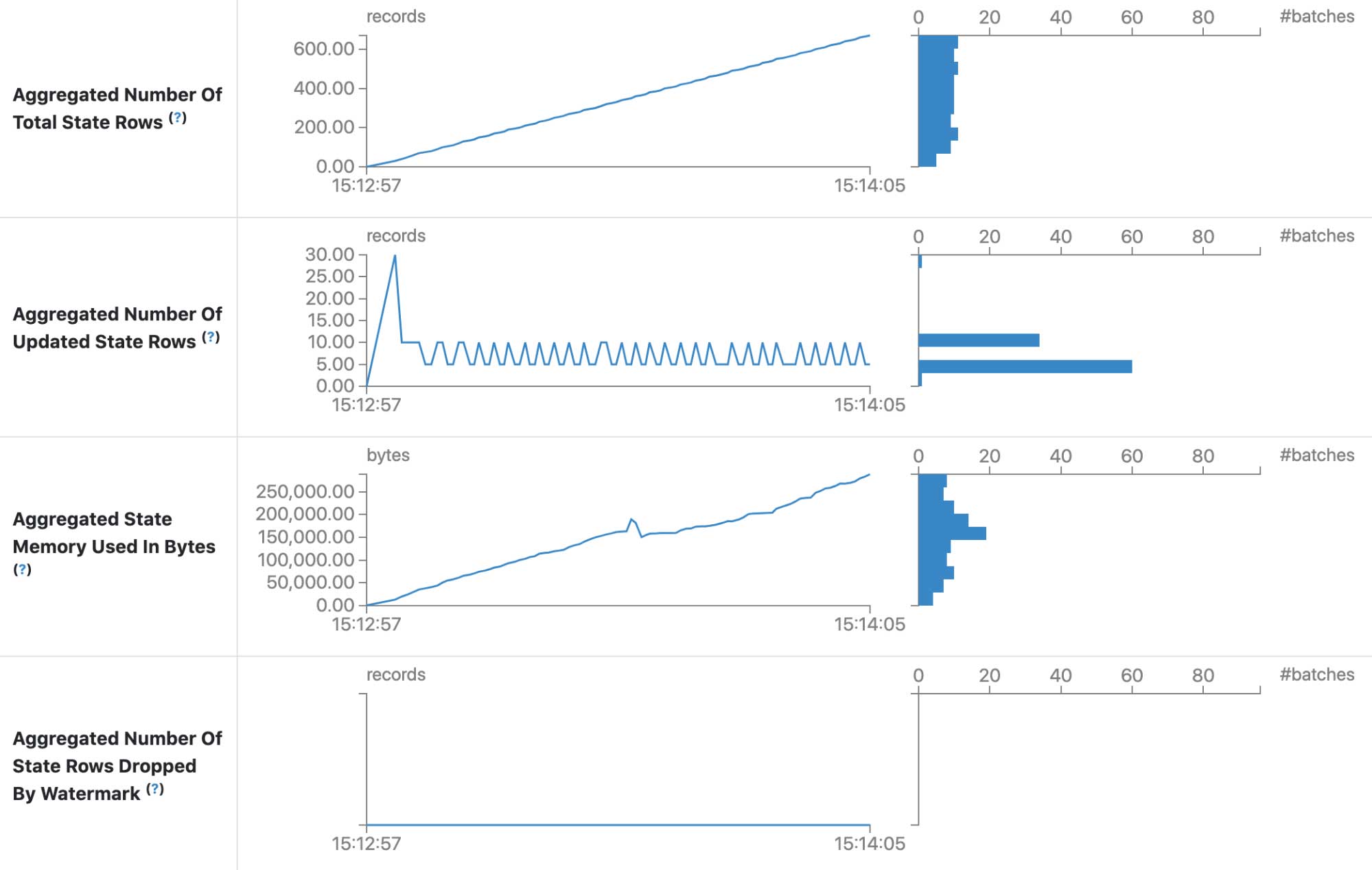
结构化流UI中的状态信息(火星- 33223)
为状态信息添加了另外四个度量:
- 聚合的状态行总数
- 已更新状态行的聚合数
- 按字节使用的聚合状态内存
- 水印删除的聚合状态行数
有了这些指标,我们就有了状态存储的全貌。它还允许添加一些新特性,如容量规划。
- 结构化流UI中的水印间隙信息(火星- 33224)
水印是最终用户需要跟踪有状态查询的主要指标之一。它定义了输出将在“何时”发出附加模式,因此知道壁钟和水印(输入数据)之间有多大的差距对设置输出的期望非常有帮助。

这将显示自定义度量信息,这些信息在配置' spark.sql.streaming.ui.enabledCustomMetricList '中设置。

FileStreamSource/Sink增强
FileStreamSource/Sink有改进:
缓存获取的文件列表超出maxFilesPerTrigger作为未读文件(火星- 30866)
以前设置maxFilesPerTrigger配置时,FileStreamSource将获取所有可用文件,根据配置处理有限数量的文件,并忽略每个微批处理的其他文件。通过这种改进,它将缓存在前一批中获取的文件,并在接下来的批中重用它们。
简化文件流源和接收器元数据日志的逻辑(火星- 30462)
在此更改之前,每当FileStreamSource/Sink中需要元数据时,元数据日志中的所有条目都被反序列化到Spark驱动程序的内存中。有了这个更改,Spark将尽可能以精简的方式读取和处理元数据日志。
提供一个保留输出文件的新选项(火星- 27188)
在FileStreamSink中有一个配置元数据日志文件保留的新选项,它有助于限制长时间运行的结构化流查询的元数据日志文件大小的增长。
接下来是什么
在下一个主要版本中,我们将继续关注Spark结构化流的新功能、性能和可用性改进。我们很乐意听到您作为最终用户或Spark开发人员的反馈!如果您有任何反馈,请随时通过Spark与我们分享用户或开发人员邮件列表。感谢社区中的所有贡献者和用户,他们帮助实现了这些重要的增强