
为CrowdStrike Falcon活动建立网络安全湖屋



2021年5月20日 在bob体育客户端下载平台的博客
现在开始在自己的Databricks部署中运行这些笔记本电脑.
安全团队需要端点数据进行威胁检测、威胁搜索、事件调查和满足法规遵从性要求。数据量可以是每天太字节或每年拍字节。由于与如此庞大的数据量相关的成本和复杂性,大多数组织都难以收集、存储和分析端点日志。但事情并不一定要这样。
在这个由两部分组成的博客系列中,我们将介绍如何使用Databricks操作pb级的端点数据,以经济有效的方式使用高级分析来改善您的安全态势。第1部分(本博客)将介绍数据收集的体系结构以及与SIEM (Splunk)的集成。在本博客的最后提供笔记本,你将准备使用数据进行分析。第2部分将讨论具体的用例,如何创建ML模型以及自动化的丰富和分析。在第2部分结束时,您将能够实现使用端点数据检测和调查威胁的笔记本。
我们将以Crowdstrike的Falcon日志为例。要访问Falcon日志,可以使用Falcon Data Replicator (FDR)将原始事件数据从CrowdStrike平台推送到云存储(如Amazon S3)。bob体育客户端下载这些数据可以通过Databricks Lakehouse平台与其他安全遥测技术一起摄入、转换、分析和存储。bob体育客户端下载客户可以获取CrowdStrike Falcon数据,应用基于python的实时检测,使用Databricks SQL搜索历史数据,并从SIEM工具(如Splunk with Databricks Add-on for Splunk)中查询。
运作Crowdstrike数据的挑战
虽然Crowdstrike Falcon数据提供了全面的事件记录细节,但以经济有效的方式近实时地吸收、处理和操作复杂的大量网络安全数据是一项艰巨的任务。以下是一些众所周知的挑战:
- 大规模实时数据摄取:很难跟踪已处理和未处理的原始数据文件,这些文件是由FDR几乎实时地写入云存储上的。
- 复杂的转换:数据格式是半结构化的。每个日志文件的每一行都包含数百种不同类型的有效负载,并且事件数据的结构可以随着时间的推移而改变。
- 数据治理:这类数据可能是敏感的,必须只允许有需要的用户访问。
- 简化的端到端安全分析:需要可扩展的工具来对这些快速移动和大容量的数据集进行数据工程和MLand分析。
- 合作:有效的协作可以利用数据工程师、网络安全分析师和机器学习工程师的专业知识。因此,拥有一个协作平台可以提高网络安全分析和响应工作负载的bob体育客户端下载效率。
因此,各企业的安全工程师发现自己处于艰难的境地,难以管理成本和运营效率。他们要么不得不接受被锁定在非常昂贵的专有系统中,要么花费巨大的精力构建自己的端点安全工具,同时为可伸缩性和性能而战。
Databricks网络安全湖屋
Databricks为安全团队和数据科学家提供了高效工作的新希望,并提供了一套工具来应对日益增长的大数据挑战和复杂的威胁。
Lakehouse,一种结合了数据湖和数据仓库的最佳元素的开放架构,简化了逐步向数据添加结构的多跳数据工程管道的构建。多跳架构的好处是,数据工程师可以构建一个管道,从原始数据开始,作为“单一真相来源”,所有信息都从原始数据中流动。Crowstrike的半结构化原始数据可以存储数年,后续的转换和聚合可以以端到端的流方式完成,以细化数据,并引入特定于上下文的结构,以分析和检测不同场景下的安全风险。
- 数据摄取:自动装卸机(AWS|Azure|GCP)有助于立即读取数据,只要一个新文件是由Crowdstrike FDR写入原始数据存储。它利用云通知服务在新文件到达云中时对其进行增量处理。Autoloader还自动配置和监听新文件的通知服务,并可以扩展到每秒数百万个文件。
- 统一流、批处理:三角洲湖是一种将数据管理和治理引入数据湖的开放方法,它利用Apache Spark™分布式计算能力处理大量数据和元数据。Databricks的Delta引擎是一个高度优化的引擎,每秒可以处理数百万条记录。
- 数据治理:与Databricks表访问控制(AWS|Azure|GCP),管理员可以根据用户的业务功能授予不同级别的delta表访问权限。
- 安全分析工具:砖的SQL帮助创建交互式仪表板,在检测到异常模式时自动发出警报。同样,它可以很容易地与高度采用的BI工具集成,如Tableau, Microsoft Power BI和lookker。
- 在Databricks笔记本上的合作:Databricks协作笔记本使安全团队能够实时协作。多个用户可以用多种语言运行查询,共享可视化,并在同一工作空间内进行评论,以保持调查不间断地进行。
Crowdstrike Falcon数据的Lakehouse架构
对于网络安全工作负载,我们推荐以下湖屋架构,例如Crowdstrike的Falcon数据。Autoloader和Delta Lake简化了从云存储读取原始数据和写入Delta表的过程,成本低,DevOps工作量最小。
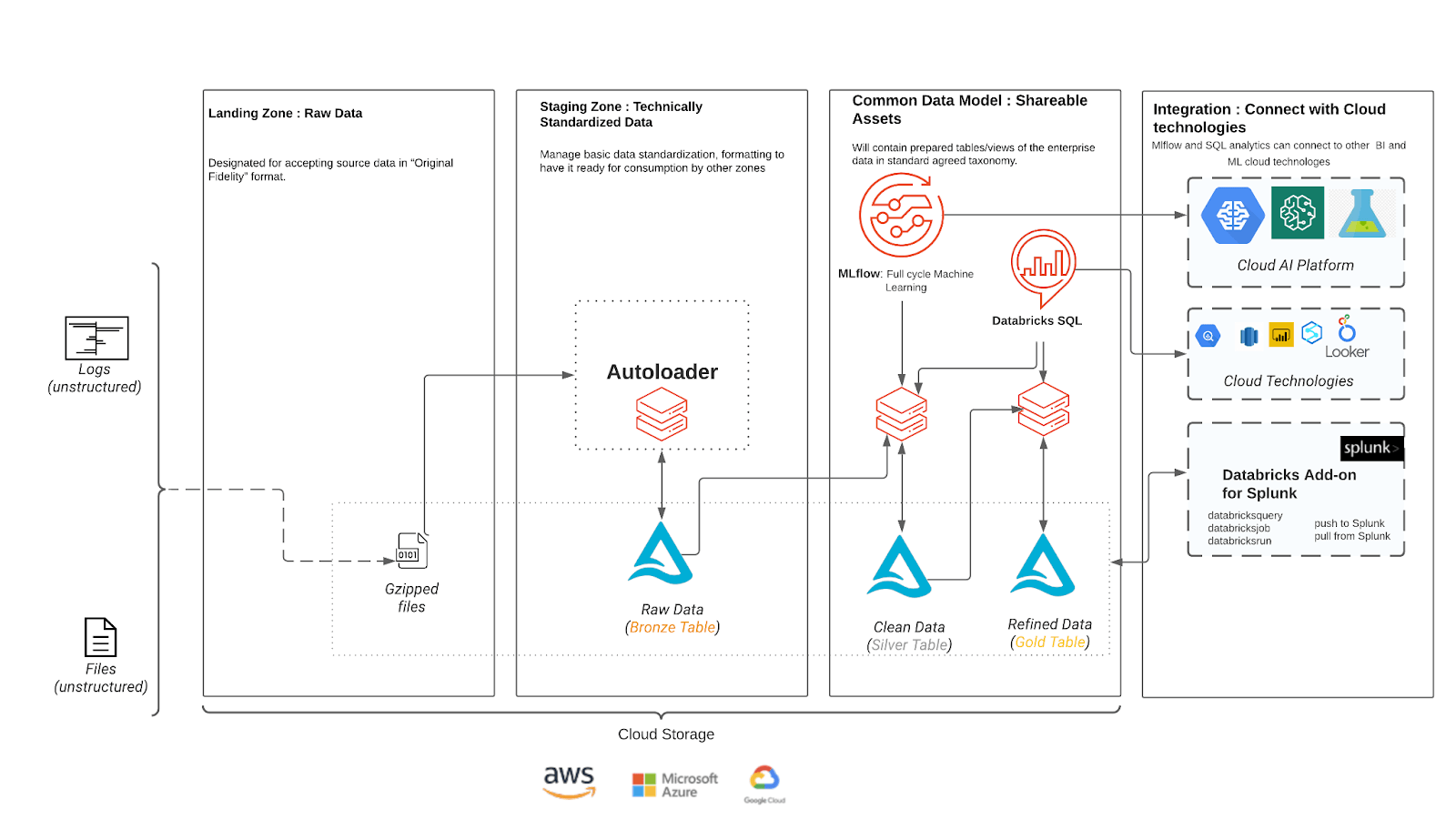
在这种架构中,半结构化Crowdstrike数据被加载到客户在着陆区的云存储中。然后,Autoloader使用云通知服务自动触发新文件的处理和输入到客户的青铜表中,这将作为所有下游作业的唯一真实来源。自动加载器将跟踪处理和未处理的文件使用检查点,以防止重复的数据处理。
当我们从青铜阶段过渡到银色阶段时,将添加模式来为数据提供结构。由于我们是从一个真实源读取数据,所以我们能够处理所有不同的事件类型,并在将它们写入各自的表时强制执行正确的模式。在Silver层强制执行模式的能力为构建ML和分析工作负载提供了坚实的基础。
黄金阶段是可选的,根据用例和数据量将数据聚合在仪表板和BI工具中以实现更快的查询和性能。警报可以设置为在观察到意外趋势时触发。
的另一个可选特性是Databricks插件Splunk这使得安全团队可以利用Databricks的低成本模式和人工智能的力量,而不必离开Splunk的舒适。客户可以在Splunk仪表板或带有附加组件的搜索栏中对Databricks进行特别查询。用户还可以通过Splunk仪表板或响应Splunk搜索在Databricks中启动笔记本电脑或作业。Databricks集成是双向的,允许客户总结噪声数据或在Splunk Enterprise Security中显示的Databricks中运行检测。客户甚至可以在Databricks笔记本电脑中运行Splunk搜索,以防止需要复制数据。
Splunk和Databricks的集成使客户能够降低成本,扩展他们分析的数据源,并提供一个更强大的分析引擎的结果,所有这些都不需要改变员工日常使用的工具。
代码走查
由于Autoloader抽象了基于文件的数据摄取中最复杂的部分,因此可以在几行代码中创建原始到青铜的摄取管道。下面是一个用于Delta摄取管道的Scala代码示例。Crowdstrike Falcon事件记录有一个通用字段名:“event_simpleName”。
val crowdstrikeStream = spark.readStream.format (“cloudFiles”).option (“cloudFiles.format”,“文本”)//文本文件不需要schema.option (“cloudFiles.region”,“us-west-2”).option (“cloudFiles.useNotifications”,“真正的”).load (rawDataSource).withColumn (“load_timestamp”current_timestamp ()).withColumn (“load_date”to_date(美元)“load_timestamp”)).withColumn (“eventType”from_json(美元)“价值”,“结构”,地图空虚(字符串,字符串])) .selectExpr (“eventType.event_simpleName”,“load_date”,“load_timestamp”,“价值”).writeStream.format (“δ”).option (“checkpointLocation”checkPointLocation).table (“demo_bronze.crowdstrike”)在raw-to-bronze层中,仅从原始数据中提取事件名称。通过添加加载时间戳和日期列,用户可以将原始数据存储到青铜表中。bronze表按事件名称和加载日期进行分区,这有助于提高bronze-to-silver作业的性能,特别是在对有限数量的事件日期范围感兴趣时。
接下来,bronze-to-silver流作业从bronze表中读取事件,执行模式并根据事件名称写入数百个事件表。下面是一个Scala代码示例:
火花.readStream.option(“ignoreChanges”,“真正的”).option(“maxBytesPerTrigger”、“2 g”).option(“maxFilesPerTrigger”、“64”).format(“δ”).load (bronzeTableLocation).过滤器(美元“event_simpleName”===“event_name”).withColumn("event", from_json($"value", schema_of_json(sampleJson))).选择($”事件。*", $"load_timestamp", $"load_date").withColumn(“silver_timestamp”,current_timestamp()).writeStream.format(“δ”).outputMode(“追加”).option(“mergeSchema”,“真正的”).option(“checkpointLocation检查点)tableLocation .option(“路径”).开始()每个事件模式都可以存储在模式注册中心或Delta表中,以防需要跨多个数据驱动服务共享模式。注意,上面的代码使用了从青铜表中读取的示例json字符串,并且模式是从json中推断出来的schema_of_json().稍后,json字符串转换为使用的结构from_json().然后,将结构平展,提示添加时间戳列。这些步骤提供了一个数据框架,其中包含要添加到事件表中的所有必需列。最后,我们使用追加模式将这些结构化数据写入事件表。
也可以用一个流将事件扇形展开到多个表foreachBatch通过定义一个处理微批的函数。使用foreachBatch(),可以重用现有的批处理数据源来过滤和写入多个表。但是,foreachBatch()只提供至少一次写入保证。因此,需要手动实现来强制执行只执行一次的语义。
在这个阶段,可以使用Databricks笔记本和作业中支持的任何语言查询结构化数据:Python、R、Scala和SQL。银层数据可以方便地用于机器学习和网络攻击分析。
下一个流媒体管道将是银转金。在此阶段,可以为仪表板和警报聚合数据。在本博客系列的第二部分中,我们将提供更多关于如何使用Databricks SQL构建仪表板的见解。
接下来是什么
请继续关注更多通过应用ML和使用Databricks SQL在这个用例上构建更大价值的博客文章。
你可以用这些笔记本电脑在自己的Databricks部署中。笔记本的每个部分都有评论。我们邀请您给我们发电子邮件(电子邮件保护).我们期待您的问题和建议,以使本笔记本更容易理解和部署。
现在,我们邀请您登录自己的Databricks帐户并运行这些笔记本电脑.我们期待您的反馈和建议。
详情请参考文件进口说明笔记本要运行。
致谢
我们要感谢支持这个博客的Bricksters,特别感谢Monzy Merza, Andrew Hutchinson, Anand Ladda的深刻讨论和贡献。