
简化变化数据获取与数据砖三角洲生活表


2022年4月25日 在工程的博客
本指南将演示如何利用变化数据捕获三角洲住表中管道识别新记录和捕捉更改数据集的数据。三角洲生活表管道使您能够开发可伸缩、可靠和低延迟数据管道,在执行中变化数据捕获数据湖与最低要求计算资源和无缝的无序的数据处理。
背景变化数据捕获
变化数据捕获(疾病预防控制中心)是一个过程,识别和捕捉增量变化(数据删除、插入和更新)数据库,跟踪客户,订单或产品状态为近实时数据的应用程序。进化的疾控中心提供实时数据处理数据连续渐进的方式作为新事件发生。
自超过80%的公司计划在2025年实施多重云战略,选择合适的方法为你的业务,允许无缝实时集中所有数据ETL管道跨多个环境的变化是至关重要的。
通过捕获中心事件,砖用户可以re-materialize源表如表在三角洲Lakehouse并运行他们的分析之上,同时能够结合数据与外部系统。并入命令在三角洲湖砖使客户能够高效地插入和删除记录的数据湖泊——你可以查看我们之前的深俯冲的话题在这里。这是一个常见的用例,我们观察砖的许多客户利用湖泊三角洲执行,并保持他们的数据湖泊最新的实时业务数据。
而三角洲湖为实时疾病预防控制中心提供了一个完整的解决方案在数据同步湖,我们现在兴奋地宣布三角洲生活中的变化数据捕获功能表,使结构更简单,更高效和可伸缩的。DLT允许用户摄取CDC数据无缝地使用SQL和Python。
早期疾病预防控制中心与三角洲表解决方案是使用合并成操作需要手动排序数据,以避免失败当源数据集的多行匹配而试图更新相同的目标三角洲表行。处理无序的数据,有一个额外的步骤需要进行预处理源表使用foreachBatch实现消除多个匹配的可能性,只保留最新的改变对于每个关键(见变化数据捕获的例子)。新申请更改生效DLT管道自动和无缝地处理无序的数据没有任何数据工程人工干预的必要性。
疾病预防控制中心与砖三角洲的生活表
在这个博客中,我们将演示如何使用变化到命令在三角洲住表中管道申请一个常见的疾病预防控制中心疾病控制和预防中心的数据使用情况是来自外部系统。各种疾病预防控制中心的工具,如Debezium Fivetran, Qlik复制,Talend, StreamSets。虽然具体的实现不同,这些工具通常捕获和记录的历史数据变化日志;下游应用程序使用这些疾病预防控制中心日志。在我们的示例数据落在云从CDC Debezium等工具,对象存储Fivetran等等。
我们有来自各种疾病预防控制中心的数据工具降落在云对象存储或Apache卡夫卡等消息队列。通常我们看到疾病预防控制中心用于摄入我们所说的大奖章的架构。大奖章的体系结构是一种数据设计模式用于Lakehouse逻辑上组织数据,逐步逐步的目标和改进的结构和质量数据流经的每一层的体系结构。三角洲生活无缝应用更改表允许您从美国疾病控制与预防中心Lakehouse提要表;这个功能结合图案架构允许增量变化轻易流过大规模分析工作量。使用疾病预防控制中心的大奖章体系结构提供了许多好处因为只有用户更改或添加数据需要处理。因此,它使用户能够有效保持黄金表最新的商业数据。
注:例子同时适用于SQL和Python版本的疾病预防控制中心和一个特定的方式使用操作,评估变化,请参阅官方文档在这里。
先决条件
为了最有效的指导,你应该有一个基本的熟悉:
- SQL或Python
- 三角洲生活表
- ETL开发管道和/或处理大数据系统
- 砖互动的笔记本和集群
- 你必须能够访问一个砖工作区与权限创建新集群,运行工作,并将数据保存到一个外部云对象存储或位置DBFS。
- 在这个博客我们创建的管道,“高级”产品版本支持的执行数据质量约束,需要选择。
数据集
我们在这里消费现实CDC数据从外部数据库。在这个管道中,我们将使用骗子库生成的数据集疾病预防控制中心工具Debezium可以产生和纳入云存储初始摄取的砖。使用自动加载程序我们从云对象存储增量加载信息,并将它们存储在铜表存储原始消息。铜表仅供数据摄入使真理的快速访问单一来源。接下来我们从清洁铜层表执行应用更改为传播下游银表的更新。数据流银表,通常它变得更加精炼和优化(“足够”)提供一个企业的关键业务实体。请参见下图。
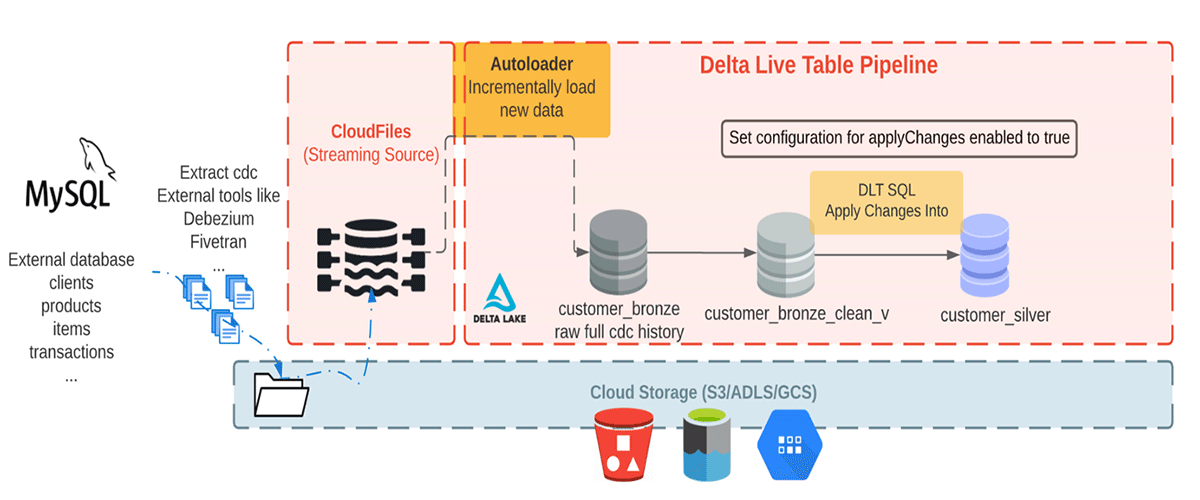
这个博客专注于一个简单的例子,需要一个JSON消息与四个领域的客户名称、电子邮件、地址和id以及两个字段:操作(商店操作代码(删除、添加、更新、创建),和operation_date(存储记录的日期和时间戳来为每个操作动作)来描述更改的数据。
与上面的字段生成一个样本数据集,我们使用一个Python包产生假数据,骗子。你可以找到笔记本相关数据生成部分在这里。在这个笔记本我们提供的名称和存储位置写生成的数据。我们使用的是砖的DBFS功能,请参阅DBFS文档更多地BOB低频彩了解它是如何工作的。然后,我们使用一个PySpark用户定义函数为每个字段,生成合成数据集和写数据定义的存储位置,我们将请参考其他笔记本电脑合成数据集访问。
摄入的原始数据集使用自动加载程序
根据图案架构范式,青铜层拥有最原始数据质量。在这个阶段我们可以逐步使用自动装卸机读取新的数据云存储的一个位置。这里我们添加路径下生成的数据集配置部分管道设置,它允许我们加载源路径作为一个变量。所以现在我们的配置下管道设置看起来像下图:
“配置”:{“源”:“/ tmp /演示/ cdc_raw”}然后我们在笔记本中加载这个配置属性。
让我们看一看铜表我们会摄取,SQL。,和b。使用Python
一个SQL。
设置spark.source;创建流表customer_bronze生活(地址字符串,电子邮件字符串,id字符串,firstname字符串,姓字符串,操作字符串,operation_date字符串,_rescued_data字符串)TBLPROPERTIES (“质量”=“青铜”)评论“新客户数据逐步吸收从云对象存储着陆区”作为SELECT *从cloud_files (" ${来源}/客户”,“json”地图(“cloudFiles.inferColumnTypes”,“真正的”));Python b。
进口dlt从pyspark.sql.functions进口*从pyspark.sql.types进口*源= spark.conf.get (“源”)@dlt.table (name =“customer_bronze”,评论=“新客户数据逐步吸收从云对象存储着陆区”,table_properties = {“质量”:“青铜”})defcustomer_bronze():返回(spark.readStream。格式(“cloudFiles”)\.option (“cloudFiles.format”,“json”)\.option (“cloudFiles.inferColumnTypes”,“真正的”)\.load (f”{来源}/客户”))上面的语句使用自动加载程序从json文件中创建一个名为customer_bronze的流媒体直播表。当使用自动装卸机在三角洲生活表,您不需要提供任何模式或检查点位置,这些位置将被自动管理你的DLT管道。
自动加载器提供了一个结构化流源cloud_files在SQL和cloudFiles在Python中,采用云存储路径和的形式作为参数。
降低计算成本,我们建议的DLT管道运行触发模式作为micro-batch假设你没有非常低的延迟需求。
预期和高质量的数据
在下一步创建高质量、多样化和可访问的数据集,我们期望实施质量检查标准使用约束。目前,一个约束可以保留,下降,或失败。为更多的细节在这里看到的。所有的约束都记录到启用流线型的质量监控。
一个SQL。
创建临时现场直播表customer_bronze_clean_v (约束valid_id期望(id是不零)在违反下降行,约束valid_address期望(地址是不零),约束valid_operation期望(操作是不零)在违反下降行)TBLPROPERTIES(“质量”=“银”)评论”洁净青铜客户视图(即什么将成为银)”作为选择*从流(LIVE.customer_bronze);Python b。
@dlt.view (name =“customer_bronze_clean_v”,评论=“洁净青铜客户视图(即什么将成为银)”)@dlt.expect_or_drop (“valid_id”,“id”不是零)@dlt.expect (“valid_address”,“地址不空”)@dlt.expect_or_drop (“valid_operation”,“不是空行动”)defcustomer_bronze_clean_v():返回dlt.read_stream (“customer_bronze”)\.select (“地址”,“电子邮件”,“id”,“firstname”,“姓”,“操作”,“operation_date”,“_rescued_data”)使用应用变化成语句更改传播到下游目标表
在执行之前申请变更成查询,我们必须确保目标流表,我们要保存最新的数据存在。如果它不存在,我们需要创建一个。下面的细胞是创建一个目标流表的例子。注意,发布这篇博客的时候,目标要求随流表创建语句申请变更成查询,都需要在管道,否则你的表创建查询将失败。
一个SQL。
创建流媒体直播表customer_silverTBLPROPERTIES(“质量”=“银”)评论“干净、合并客户”;Python b。
dlt.create_target_table (name =“customer_silver”,评论=“干净、合并客户”,table_properties = {“质量”:“银”})现在我们有一个目标流表,我们可以更改传播到下游目标表使用申请变更成查询。而CDC饲料有插入、更新和删除事件,DLT的默认行为是应用插入和更新事件从源数据集匹配的任何记录主键,和排序的字段标识事件的顺序。更确切地说它更新现有的任何行匹配的目标表主键(s)或插入一个新行,当一个匹配的目标流表中记录不存在。我们可以使用使用时删除在SQL或其等价的apply_as_deletes参数在Python中来处理删除事件。
在这个示例中,我们使用“id”作为我的主键,唯一地标识客户和允许疾控中心事件申请确定目标流表的客户记录。因为“operation_date“疾控中心的逻辑顺序事件源数据集,我们使用“operation_date序列”在SQL或其等价的“sequence_by =坳(“operation_date”)”在Python中处理变更的事件到达的顺序。请记住,我们使用的字段值(或sequence_by序列)应该是唯一的在所有相同的密钥更新。在大多数情况下,顺序与时间戳列将列信息。
最后我们使用“列*除了(操作、operation_date _rescued_data)”在SQL或其等价的“except_column_list”=(“操作”、“operation_date”,“_rescued_data”)在Python中排除三列“操作”、“operation_date”、“_rescued_data”从目标流表。默认情况下所有的列都包含在目标流表,当我们不指定“列”条款。
一个SQL。
申请更改成LIVE.customer_silver从流(LIVE.customer_bronze_clean_v)键(id)应用作为删除当操作=“删除”序列通过operation_date列*除了(操作、operation_date_rescued_data);Python b。
dlt.apply_changes (目标=“customer_silver”,源=“customer_bronze_clean_v”,键= [“id”),sequence_by =坳(“operation_date”),apply_as_deletes = expr (“=”删除“行动”),except_column_list = [“操作”,“operation_date”,“_rescued_data”])检查可用条款的完整列表在这里。
请注意,在发布这篇博客的时候,表读取的目标申请变更成查询或apply_changes函数必须是一个生活表,不能流表。
一个SQL和python这一部分笔记本可供参考。现在我们已经准备好了所有的细胞,让我们创建一个管道从云摄取数据对象存储。在新选项卡中打开工作或工作区窗口,并选择“三角洲住表”。
管道与此相关的博客,有以下DLT管道设置:
{“集群”:【{“标签”:“默认”,“num_workers”:1}),“发展”:真正的,“连续”:假,“版”:“高级”,“光子”:假,“库”:【{“笔记本”:{“路径”:“/回购/(电子邮件保护)/ Delta-Live-Tables /笔记本电脑/ 1-CDC_DataGenerator”}},{“笔记本”:{“路径”:“/回购/(电子邮件保护)/ Delta-Live-Tables /笔记本电脑/ 2-Retail_DLT_CDC_sql”}}),“名称”:“CDC_blog”,“存储”:“dbfs: / home / mydir / myDB / dlt_storage”,“配置”:{“源”:“/ tmp /演示/ cdc_raw”,“pipelines.applyChangesPreviewEnabled”:“真正的”},“目标”:“my_database”}- 选择“创建管道”来创建一个新的管道
- 指定一个名称,如“零售中心管道”
- 指定你的笔记本路径之前已经创建,一个用于生成的数据集使用伪造者的包,另一个路径在DLT摄入生成的数据。第二个笔记本路径可以参考笔记本用SQL编写的,或者Python取决于你的语言的选择。
- 访问数据生成的第一个笔记本,添加数据路径的配置。这里我们将数据存储在“/ tmp /演示/ cdc_raw /客户”,我们将“源”“/ tmp /演示/ cdc_raw /”引用“源/客户”在第二个笔记本。
- 指定目标(这是可选的,他指的是目标数据库),在那里你可以查询结果表从你的管道。
- 指定对象存储的存储位置(这是可选的),访问你的DLT生产数据和元数据日志的管道。
- 管道模式设置为触发。在触发模式下,DLT管道将使用新数据的来源,一旦处理它将自动终止计算资源。你可以触发和连续模式之间切换时编辑管道设置。设置“连续”:假的JSON相当于设置管道触发模式。
- 对于这个工作负载可以禁用自动定量自动驾驶仪选项下,集群和只使用1工人。生产工作负载,我们建议启用自动定量和设置最大的集群大小所需的工人数量。
- 选择“开始”
- 现在您的管道创建并运行!
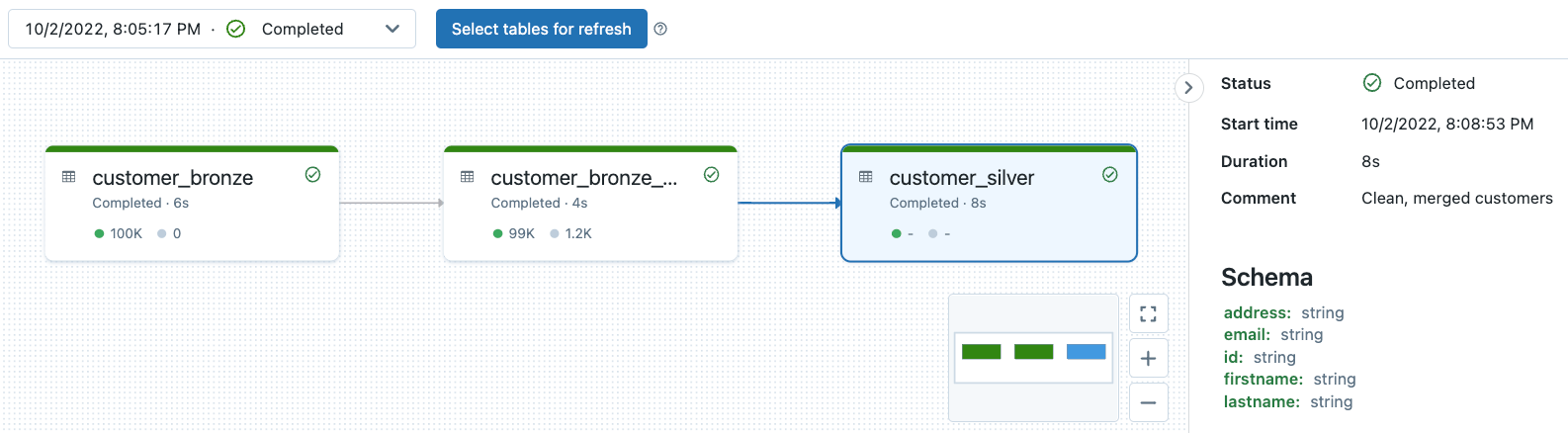
DLT管道血统可观测性,数据质量监控
所有DLT管道日志存储在管道的存储位置。你可以指定存储位置只有当你创建管道。注意一旦创建了管道可以不再修改存储位置。
你可以查看我们之前的深俯冲的话题在这里。试一试这个笔记本看到管道可观测性和数据质量监控的例子DLT管道与此相关的博客。
结论
在这个博客中,我们展示了我们无缝用户高效地实现变化数据捕获(CDC)到Lakehouse平台与达美住表(DLT)。bob体育客户端下载DLT为内置的质量控制提供了深可见性管道操作,观察管道血统,监控模式,在管道中的每个步骤和质量检查。DLT支持自动错误处理和最好的伸缩能力流工作负载,使得用户拥有质量数据和优化他们的工作负载所需的资源。
数据工程师现在可以轻松实现疾病预防控制中心和一个新的声明申请变更为API在SQL或与DLT Python。这个新功能允许你ETL管道容易识别的变化和应用这些更改在成千上万的表与低延迟的支持。
请注意这个网络研讨会学习如何三角洲生活表简化了数据转换的复杂性和ETL,看看我们改变数据获取与三角洲生活表官方文档,github并遵循的步骤视频创建你的管道!