Lakehouse架构模式的兴起建立在技术创新的基础上,使数据湖能够支持ACID事务和传统数据仓库工作负载的其他特性。加入我们的五部分学习系列开始与三角洲湖。本系列技术讲座将带您了解Delta Lake (Apache Spark)的技术基础,构建高度可伸缩的数据管道,处理合并流+批处理工作负载,使用Delta Lake和MLflow为数据科学提供动力,甚至与Delta Lake工程师一起深入了解其起源。
许多研讨会都有笔记本和幻灯片链接供你下载。

Apache Spark是大数据的主要处理框架。Delta Lake为Spark增加了可靠性,因此您的分析和机器学习计划可以随时访问高质量、可靠的数据。本次网络研讨会将介绍如何使用Delta Lake增强Spark环境中的数据可靠性。

常见的数据工程管道架构使用对应不同质量级别的表,逐步向数据添加结构:数据摄取(“青铜”表),转换/特征工程(“银”表),以及机器学习训练或预测(“金”表)。结合起来,我们将这些表称为“多跳”体系结构。它允许数据工程师建立一个管道,从原始数据开始,作为“单一的真相来源”,一切都从中流动。
Lambda架构是一种流行的技术,其中记录由批处理系统和流系统并行处理。然后在查询期间将结果进行组合,以提供完整的答案。随着Delta Lake的出现,我们看到许多客户采用了简单的连续数据流模型来处理到达的数据。我们称这种体系结构为“Delta体系结构”。在本节课中,我们将讨论采用连续数据流模型的主要瓶颈,以及Delta体系结构如何解决这些问题。
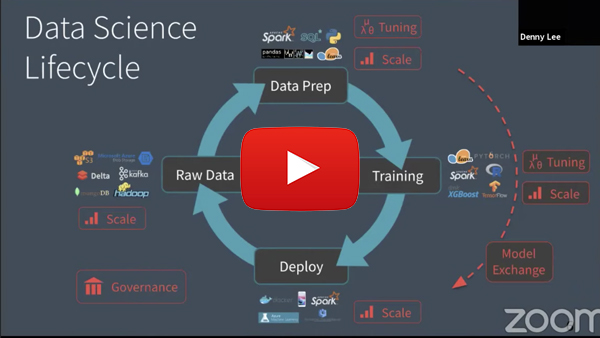
在规划数据科学计划时,必须对整个数据分析领域有一个整体的看法。数据工程是数据科学的关键推动者,有助于及时提供可靠、高质量的数据。Delta Lake是一种为数据湖带来可靠性的开源存储层,可以帮助您将数据可靠性提升到一个新的水平。

开发者倡导者Denny Lee采访了Databricks的软件工程师Burak Yavuz,了解Delta Lake团队的决策过程,以及他们为什么设计、构建和实现今天的架构。了解团队面临的技术挑战,如何解决这些挑战,并了解未来的计划。

