
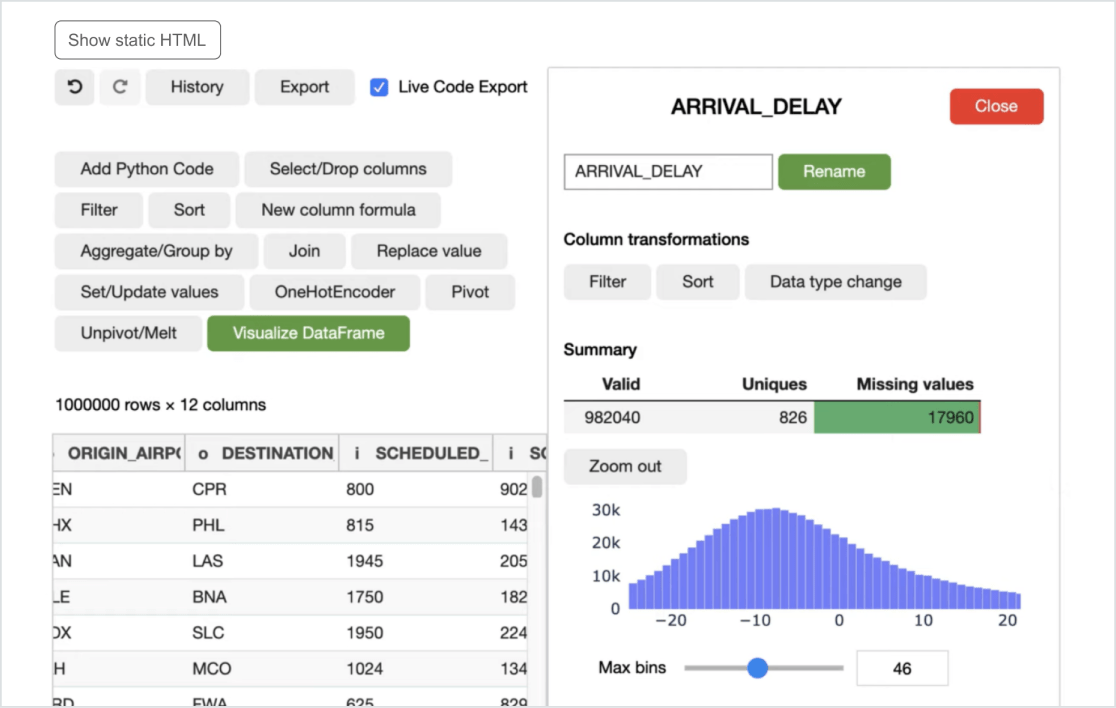
非工程师的数据工程
机器学习始于数据工程。现在,您第一次无需编写代码就可以准备、转换、可视化和执行探索性数据分析。Databricks允许组织中的任何人为任何下游用例准备数据。
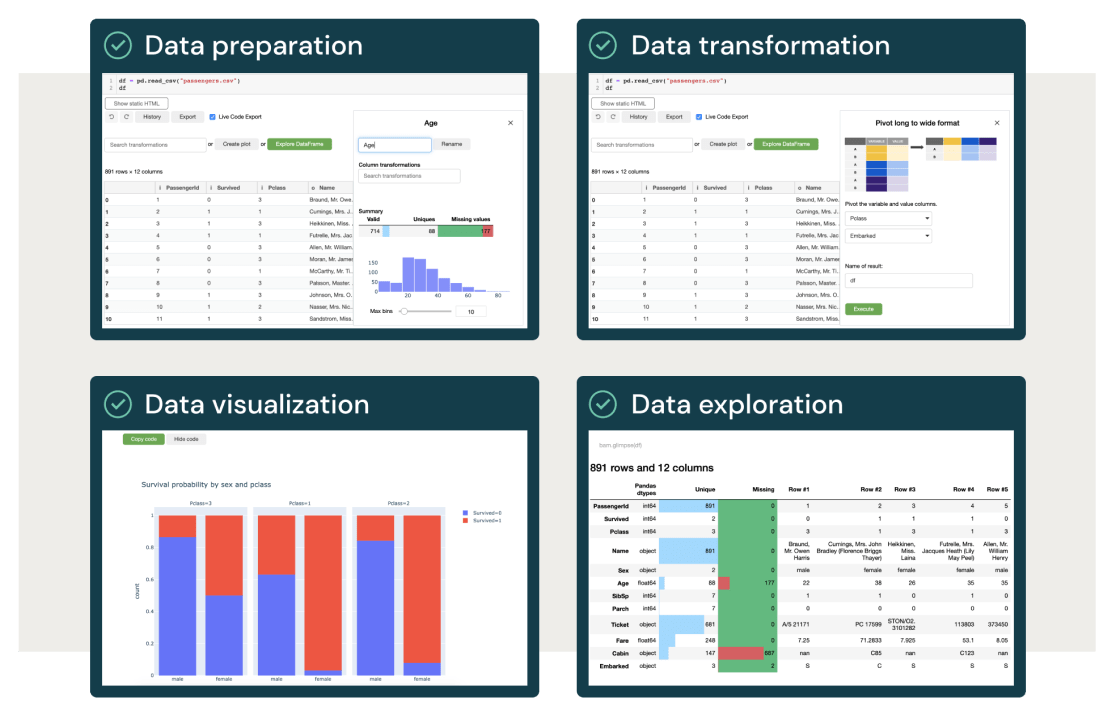
全自动机器学习
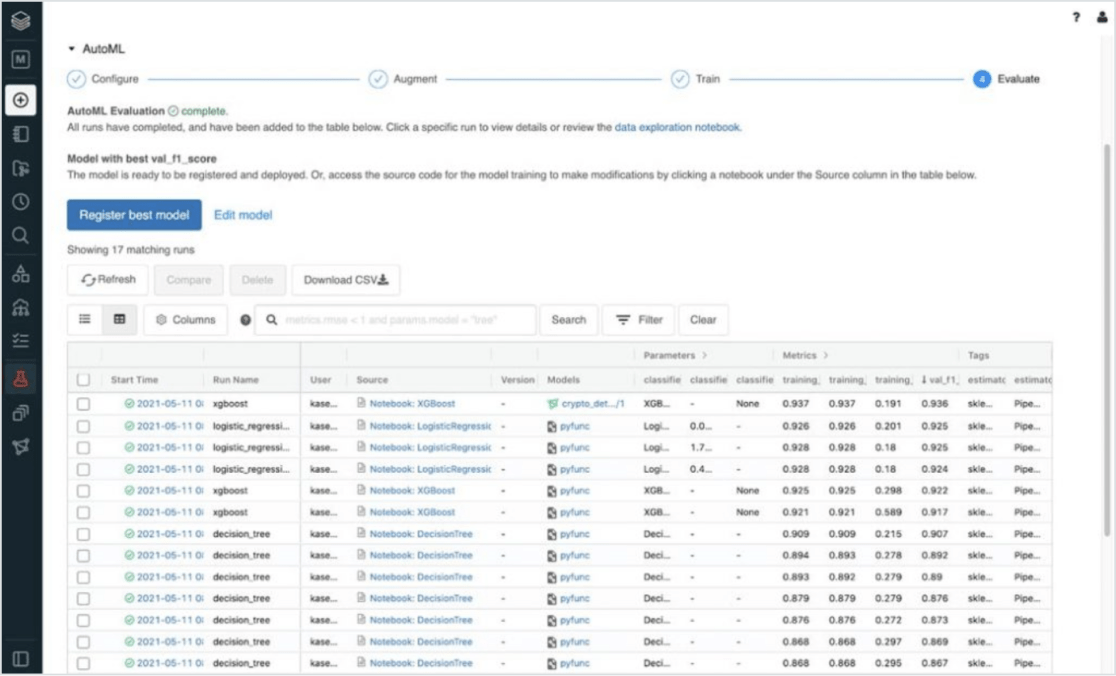
Databricks AutoML为公民数据科学提供了一个玻璃盒方法,使团队能够通过自动化繁重的预处理、特征工程和模型训练和调优来快速构建、训练和部署机器学习模型。导入数据集,配置培训和部署模型-无需离开UI。
透明度和可见性,当你需要时,你可以更仔细地查看
Databricks机器学习的独特之处在于,在UI中执行的所有步骤也会在底层生成生产级代码。
专家数据科学家和机器学习工程师可以检查这些代码并添加他们自己的定制,或者当可重复性和透明度至关重要时,监管机构可以引用它。Databricks机器学习本机集成MLflow,实现粒度实验跟踪和版本控制——从预处理和特性工程到培训和部署。
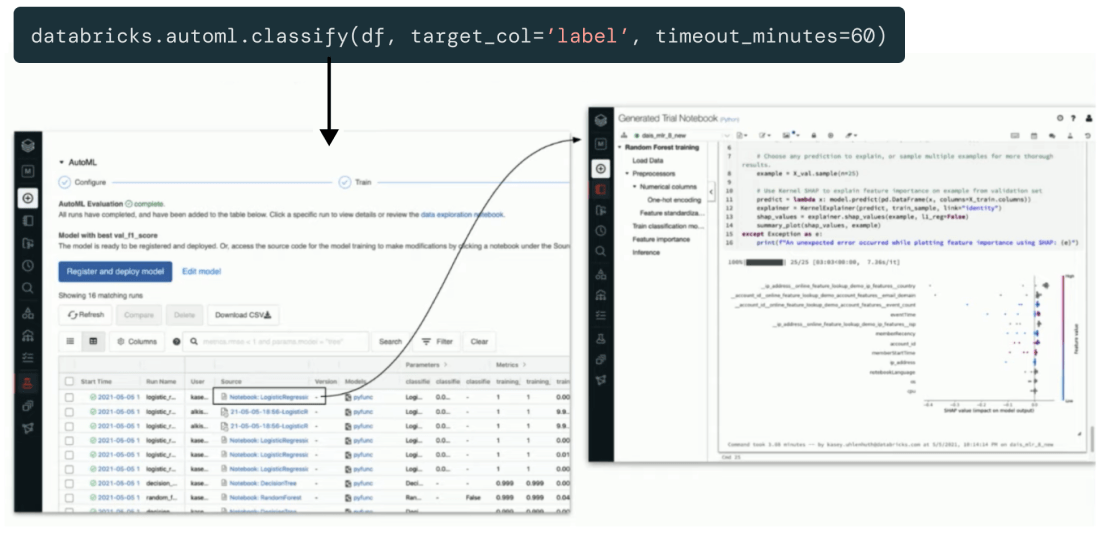
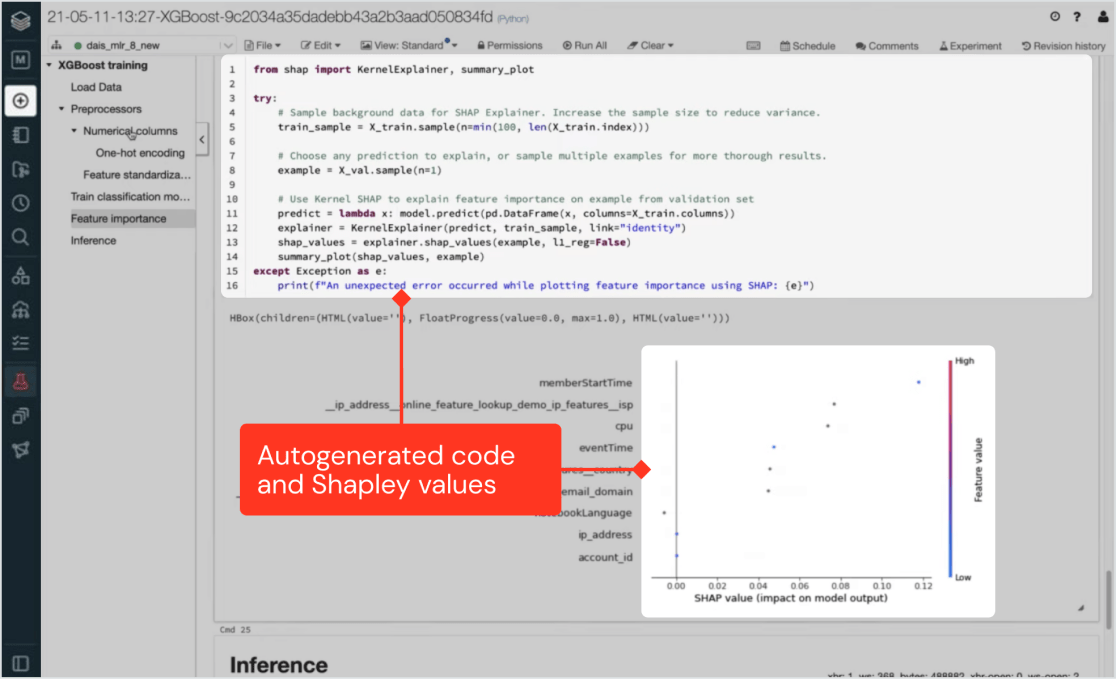
跨功能协作的可解释和兼容
Databricks对完整沿袭跟踪和注册自动生成代码的支持,确保每个人的数据科学项目都是安全、合规和可跟踪的。可解释性特性提供了对生成的模型影响最大的输入的洞察。这为各种各样的团队合作创造了基础——从用户到数据科学家和机器学习工程师,一直到IT、法律和合规。




