Apache火花™教程:开始使用Apache火花砖
创建示例数据
有两种方法可以创建数据集:动态,通过阅读从JSON文件使用SparkSession。首先,原始类型的例子或演示,您可以创建数据集在Scala或Python笔记本或火花示例应用程序。例如,这里有一个方法来创建一个数据集的100个整数笔记本。我们使用火花变量来创建100个整数数据集(长)。
/ / 100数据来创建一个数据集。val range100 = spark.range (One hundred.)range100.collect ()
加载示例数据
更常见的方法是读取数据文件从外部数据源,HDFS, blob存储、NoSQL, RDBMS或本地文件系统。火花支持多种格式:JSON、CSV、文本、拼花,兽人等等。读取JSON文件,您还可以使用SparkSession变量火花。
开始使用数据集的最简单方法是使用砖中可用数据集的一个例子/ databricks-datasets在砖工作区文件夹访问。
val df = spark.read.json (“/ databricks-datasets /样本/人/ people.json”)在读取JSON文件,火花不知道您的数据的结构。也就是说,它不知道如何组织你的数据到一个JVM typed-specific对象。它试图推断出从JSON文件并创建一个模式DataFrame =数据集(行)通用的行对象。
您可以显式地转换DataFrame成一个数据集反映了Scala类对象通过定义一个特定领域的Scala用例类和把DataFrame转换成类型:
/ /首先,定义一个类代表一个特定于类型的Scala JVM对象情况下类人(名字:字符串,年龄:长)/ /读取JSON文件,DataFrames转换为特定类型的JVM Scala对象/ /人。在这个阶段的火花,在阅读JSON,创建了一个通用的/ / DataFrame =数据集(行)。通过显式地将DataFrame转化为数据集/ /结果在一个特定于类型的行或对象集合类型的人val ds= spark.read.json (“/ databricks-datasets /样本/人/ people.json”)。as[人]你可以做类似的JSON文件中捕获与物联网设备状态信息:定义一个用例类读取JSON文件,转换DataFrame =数据集[DeviceIoTData]。
将有两个原因DataFrame为一个特定类型的JVM对象。首先,显式转换后,对所有关系和使用数据集API查询表达式,得到编译类型安全。例如,如果您使用一个过滤器操作使用错误的数据类型,火花检测不匹配类型和问题一个编译错误而执行运行时错误,这样你捕获错误。第二,数据API提供了高阶方法,使代码更容易阅读和培养。一节中过程和可视化数据集,注意使用数据集类型对象使代码更易于表达和阅读。
就像在人示例中,创建一个用例类封装了Scala对象。访问文件,其中包含物联网数据,加载文件/ databricks-datasets /物联网/ iot_devices.json。
/ /定义一个类,代表了设备数据。情况下类DeviceIoTData(battery_level:长,c02_level:长,cca2:字符串,cca3:字符串,cn:字符串,device_id:长,device_name:字符串,湿度:长,知识产权:字符串,纬度:双,经度:双,规模:字符串,临时:长,时间戳:长)/ /读取JSON文件并创建的数据集“‘DeviceIoTData案例类/ / ds现在DeviceIoTData JVM Scala对象的集合val ds= spark.read.json (“/ databricks-datasets /物联网/ iot_devices.json”)。as [DeviceIoTData]查看数据集
查看数据以表格格式而不是出口到第三方的工具,您可以使用砖显示()命令。一旦你加载JSON数据转换成一个数据集特定类型的JVM对象的集合,你可以把它们作为你会查看DataFrame通过使用显示()或标准火花命令,如带(),foreach (),println ()API调用。
/ /显示表刚从JSON文件读入数据集显示器(ds)/ /使用标准的火花命令,把()和foreach(),打印第一/ /数据集的10行。ds.take (10)。foreach(println (_))打印第一个10行数据集
过程和可视化数据集
一个数据集转换和行动。最重要的是高层次的领域特定操作等sum (),select (),avg (),加入(),联盟()。有关更多信息,请参见Scala API的数据集。
在这个示例中,您可以使用filter (),map (),groupBy (),avg (),所有的高级方法,创建新的数据集。值得注意的是,您可以访问的属性中定义的名字用例类。也就是说,使用点符号来访问单个字段。因此,它使代码易于阅读和写作。
/ /过滤掉所有设备的温度超过25度和生成/ /另一个数据集和三个感兴趣的领域,然后显示/ /映射的数据集val dsTemp = ds.filter (d= >d。临时>25). map (d= >(d。临时,d.device_name d.cca3)显示器(dsTemp)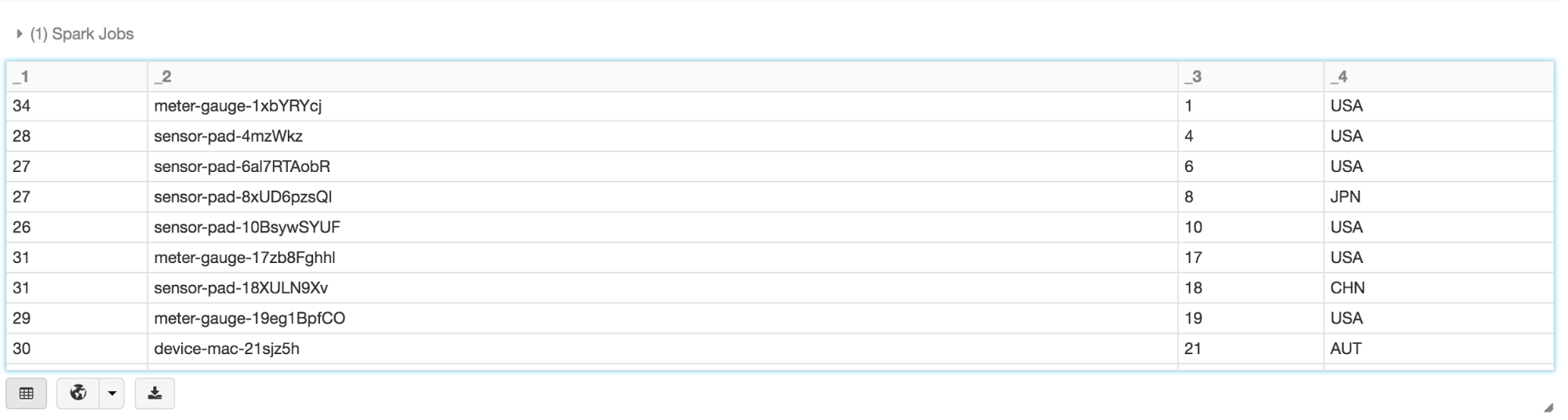
/ /数据集应用高级API方法如groupBy()和avg ()。/ /过滤温度> 25,以及它们的对应/ /设备的湿度,计算平均值,groupBy cca3国家代码,/ /并显示结果,使用表格和柱状图val dsAvgTmp = ds.filter (d= >{d。临时>25}). map (d= >(d。临时,d。湿度、d.cca3) .groupBy(美元)“_3”).avg ()/ /显示平均表,由国家进行分组显示器(dsAvgTmp)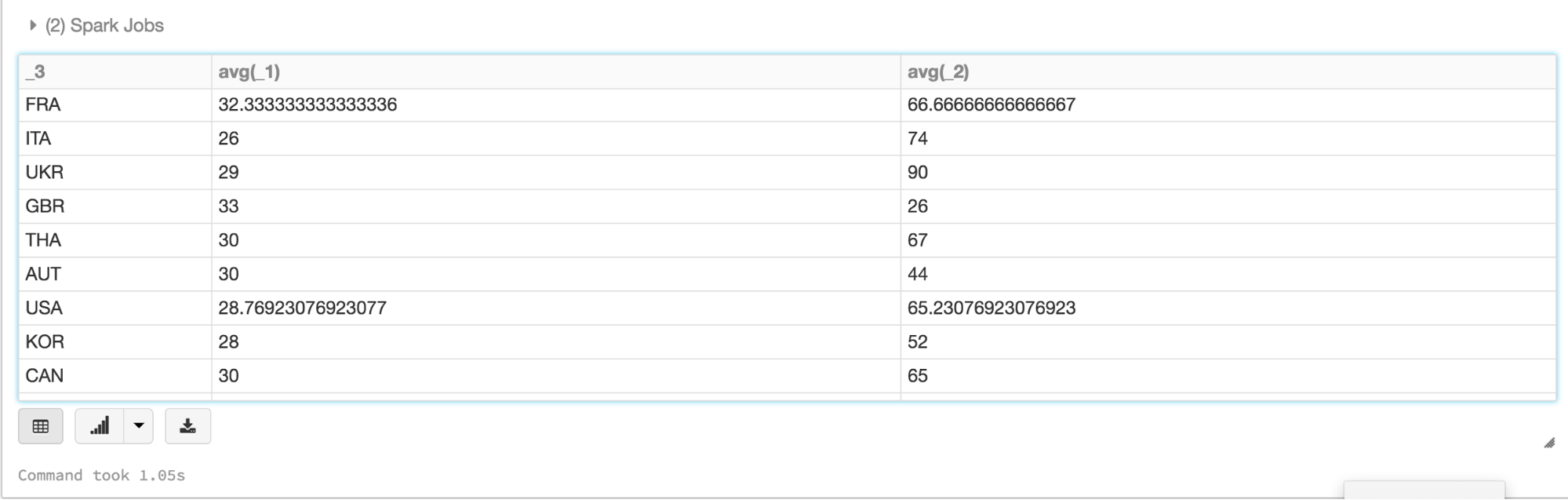
//选择单个字段使用数据集方法选择()//在哪里battery_level是大于6。注意这高- - - - - -水平//域具体的语言API读取就像一个SQL查询显示器(ds。选择($"battery_level", $"c02_level", $"device_name").在哪里(美元“battery_level”>6).sort (“c02_level”美元))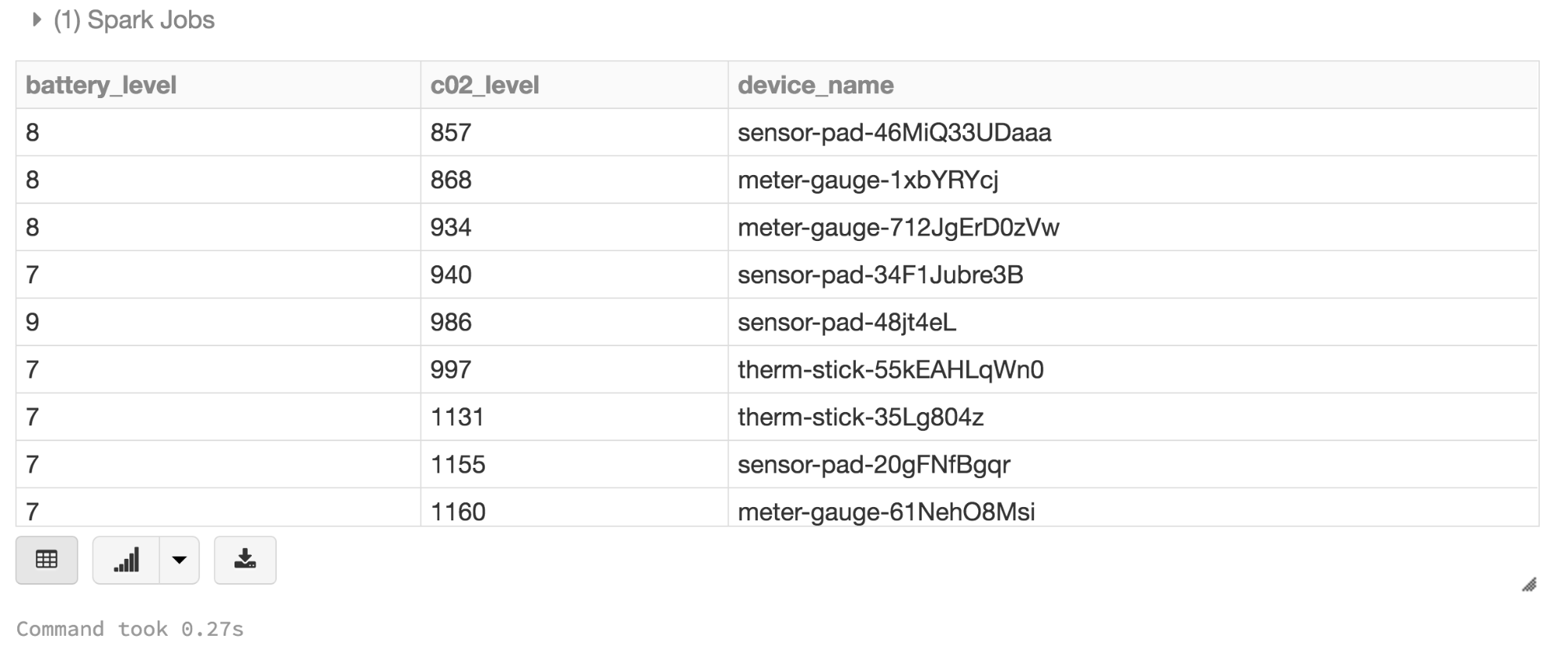
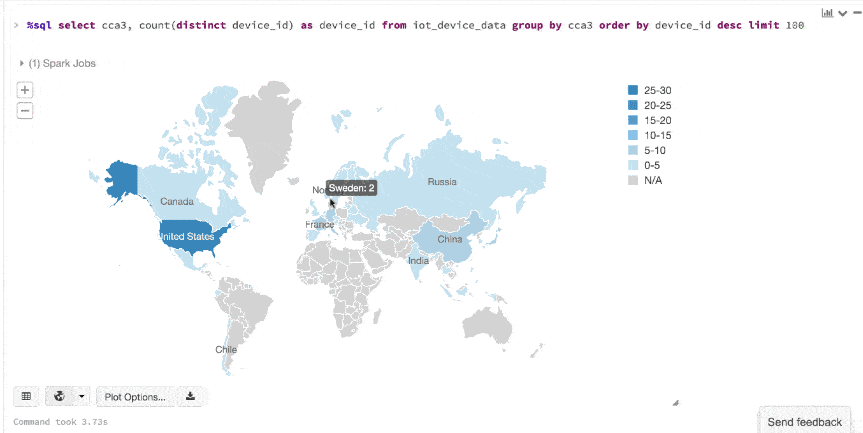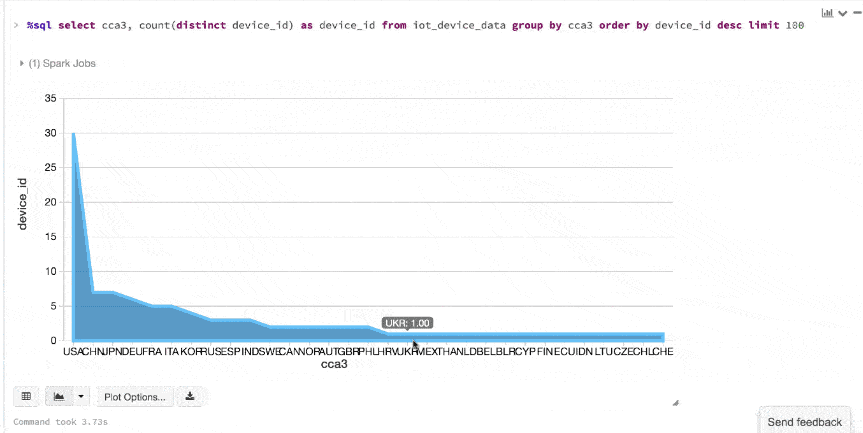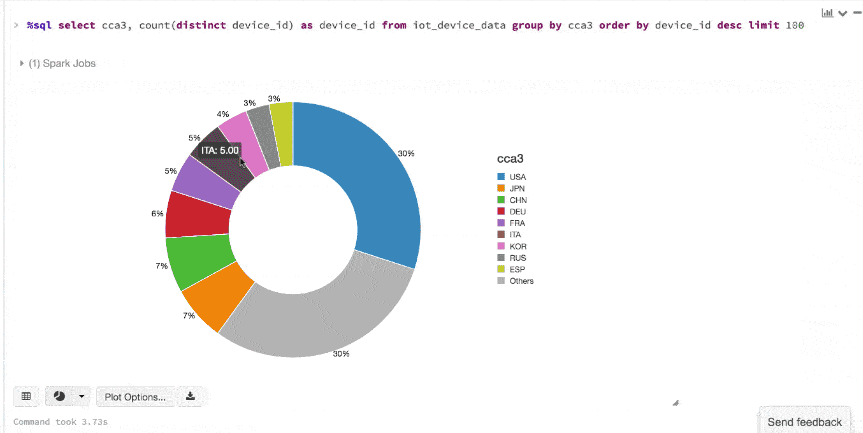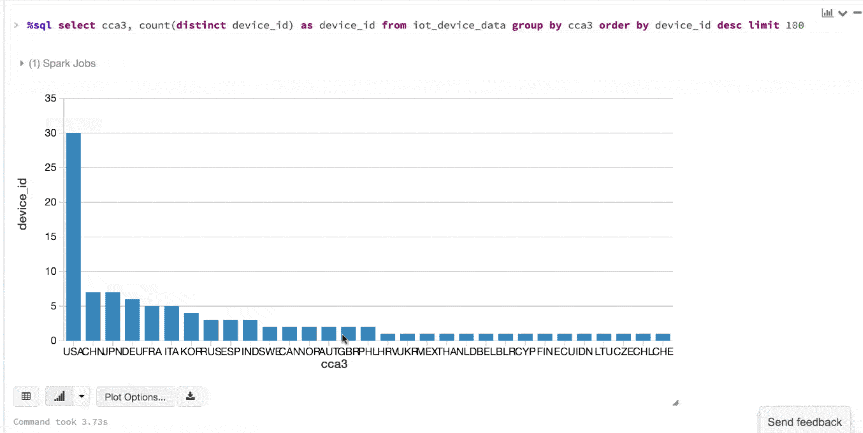
显示()命令,可以快速查看这些数据的嵌入式可视化。例如,在一个新细胞,可以发出SQL查询和点击地图查看数据。但首先你必须保存数据集,ds作为一个临时表。
/ /注册你的数据集作为一个临时表,可以发出SQL查询ds.createOrReplaceTempView (“iot_device_data”)在拯救了数据集DeviceIoTData临时表,可以发出SQL查询。
%sql选择cca3,数(截然不同的device_id)作为device_id从iot_device_data集团通过cca3订单通过device_iddesc限制One hundred.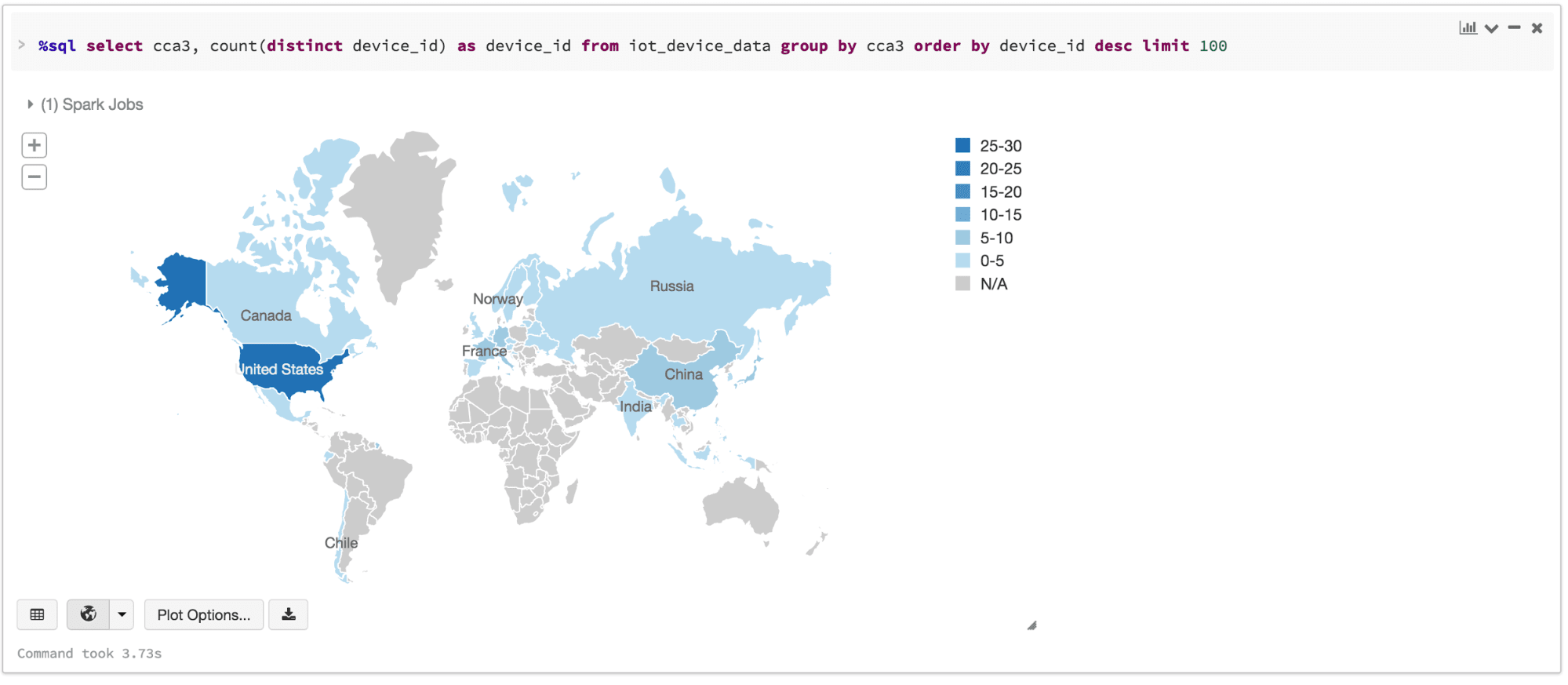
我们也提供一个样的笔记本你可以导入访问和运行的所有代码示例包含在模块。
